tl;dr: Through extensive systematic experiments, we show how the traditional approaches fail to explain why large neural networks generalize well in practice, and why understanding deep learning requires rethinking generalization.

Despite their massive size, successful deep artificial neural networks can
exhibit a remarkably small difference between training and test performance.
Conventional wisdom attributes small generalization error either to properties
of the model family, or to the regularization techniques used during training.
Through extensive systematic experiments, we show how these traditional
approaches fail to explain why large neural networks generalize well in
practice. Specifically, our experiments establish that state-of-the-art
convolutional networks for image classification trained with stochastic
gradient methods easily fit a random labeling of the training data. This
phenomenon is qualitatively unaffected by explicit regularization, and occurs
even if we replace the true images by completely unstructured random noise. We
corroborate these experimental findings with a theoretical construction
showing that simple depth two neural networks already have perfect finite
sample expressivity as soon as the number of parameters exceeds the
number of data points as it usually does in practice.
We interpret our experimental findings by comparison with traditional models.

Neural networks are powerful and flexible models that work well for many difficult learning tasks in image, speech and natural language understanding. Despite their success, neural networks are still hard to design. In this paper, we use a recurrent network to generate the model descriptions of neural networks and train this RNN with reinforcement learning to maximize the expected accuracy of the generated architectures on a validation set. On the CIFAR-10 dataset, our method, starting from scratch, can design a novel network architecture that rivals the best human-invented architecture in terms of test set accuracy. Our CIFAR-10 model achieves a test error rate of 3.65, which is 0.09 percent better and 1.05x faster than the previous state-of-the-art model that used a similar architectural scheme. On the Penn Treebank dataset, our model can compose a novel recurrent cell that outperforms the widely-used LSTM cell, and other state-of-the-art baselines. Our cell achieves a test set perplexity of 62.4 on the Penn Treebank, which is 3.6 perplexity better than the previous state-of-the-art model. The cell can also be transferred to the character language modeling task on PTB and achieves a state-of-the-art perplexity of 1.214.
tl;dr: We predict whether randomly initialized neural networks can be trained by studying whether or not information can travel through them.

We study the behavior of untrained neural networks whose weights and biases are randomly distributed using mean field theory. We show the existence of depth scales that naturally limit the maximum depth of signal propagation through these random networks. Our main practical result is to show that random networks may be trained precisely when information can travel through them. Thus, the depth scales that we identify provide bounds on how deep a network may be trained for a specific choice of hyperparameters. As a corollary to this, we argue that in networks at the edge of chaos, one of these depth scales diverges. Thus arbitrarily deep networks may be trained only sufficiently close to criticality. We show that the presence of dropout destroys the order-to-chaos critical point and therefore strongly limits the maximum trainable depth for random networks. Finally, we develop a mean field theory for backpropagation and we show that the ordered and chaotic phases correspond to regions of vanishing and exploding gradient respectively.
tl;dr: We present a novel method to train a class of probabilistic models with discrete latent variables using the variational autoencoder framework, including backpropagation through the discrete latent variables.

Probabilistic models with discrete latent variables naturally capture datasets composed of discrete classes. However, they are difficult to train efficiently, since backpropagation through discrete variables is generally not possible. We present a novel method to train a class of probabilistic models with discrete latent variables using the variational autoencoder framework, including backpropagation through the discrete latent variables. The associated class of probabilistic models comprises an undirected discrete component and a directed hierarchical continuous component. The discrete component captures the distribution over the disconnected smooth manifolds induced by the continuous component. As a result, this class of models efficiently learns both the class of objects in an image, and their specific realization in pixels, from unsupervised data; and outperforms state-of-the-art methods on the permutation-invariant MNIST, Omniglot, and Caltech-101 Silhouettes datasets.
tl;dr: I introduce a set of differentiable graph transformations, and use them to build a model with a graphical internal state that can extract structured data from text and use it to answer queries.

Graph-structured data is important in modeling relationships between multiple entities, and can be used to represent states of the world as well as many data structures. Li et al. (2016) describe a model known as a Gated Graph Sequence Neural Network (GGS-NN) that produces sequences from graph-structured input. In this work I introduce the Gated Graph Transformer Neural Network (GGT-NN), an extension of GGS-NNs that uses graph-structured data as an intermediate representation. The model can learn to construct and modify graphs in sophisticated ways based on textual input, and also to use the graphs to produce a variety of outputs. For example, the model successfully learns to solve almost all of the bAbI tasks (Weston et al., 2016), and also discovers the rules governing graphical formulations of a simple cellular automaton and a family of Turing machines.

Empirically, neural networks that attempt to learn programs from data have exhibited poor generalizability. Moreover, it has traditionally been difficult to reason about the behavior of these models beyond a certain level of input complexity. In order to address these issues, we propose augmenting neural architectures with a key abstraction: recursion. As an application, we implement recursion in the Neural Programmer-Interpreter framework on four tasks: grade-school addition, bubble sort, topological sort, and quicksort. We demonstrate superior generalizability and interpretability with small amounts of training data. Recursion divides the problem into smaller pieces and drastically reduces the domain of each neural network component, making it tractable to prove guarantees about the overall system’s behavior. Our experience suggests that in order for neural architectures to robustly learn program semantics, it is necessary to incorporate a concept like recursion.
tl;dr: We introduce a theory about generative adversarial networks and their issues.

The goal of this paper is not to introduce a single algorithm or method, but to make theoretical steps towards fully understanding the training dynamics of gen- erative adversarial networks. In order to substantiate our theoretical analysis, we perform targeted experiments to verify our assumptions, illustrate our claims, and quantify the phenomena. This paper is divided into three sections. The first sec- tion introduces the problem at hand. The second section is dedicated to studying and proving rigorously the problems including instability and saturation that arize when training generative adversarial networks. The third section examines a prac- tical and theoretically grounded direction towards solving these problems, while introducing new tools to study them.
tl;dr: Semi-supervised learning of a privacy-preserving student model with GANs by knowledge transfer from an ensemble of teachers trained on partitions of private data.

Some machine learning applications involve training data that is sensitive, such
as the medical histories of patients in a clinical trial. A model may
inadvertently and implicitly store some of its training data; careful analysis
of the model may therefore reveal sensitive information.
To address this problem, we demonstrate a generally applicable approach to
providing strong privacy guarantees for training data: Private Aggregation of Teacher Ensembles (PATE). The approach combines, in
a black-box fashion, multiple models trained with disjoint datasets, such as
records from different subsets of users. Because they rely directly on sensitive
data, these models are not published, but instead used as ''teachers'' for a ''student'' model.
The student learns to predict an output chosen by noisy voting
among all of the teachers, and cannot directly access an individual teacher or
the underlying data or parameters. The student's privacy properties can be
understood both intuitively (since no single teacher and thus no single dataset
dictates the student's training) and formally, in terms of differential privacy.
These properties hold even if an adversary can not only query the student but
also inspect its internal workings.
Compared with previous work, the approach imposes only weak assumptions on how
teachers are trained: it applies to any model, including non-convex models like
DNNs. We achieve state-of-the-art privacy/utility trade-offs on MNIST and SVHN
thanks to an improved privacy analysis and semi-supervised learning.
tl;dr: Novel model for unconditional audio generation task using hierarchical multi-scale RNNs and autoregressive MLP.

In this paper we propose a novel model for unconditional audio generation task that generates one audio sample at a time. We show that our model which profits from combining memory-less modules, namely autoregressive multilayer perceptron, and stateful recurrent neural networks in a hierarchical structure is de facto powerful to capture the underlying sources of variations in temporal domain for very long time on three datasets of different nature. Human evaluation on the generated samples indicate that our model is preferred over competing models. We also show how each component of the model contributes to the exhibited performance.

We describe an image compression method, consisting of a nonlinear analysis transformation, a uniform quantizer, and a nonlinear synthesis transformation. The transforms are constructed in three successive stages of convolutional linear filters and nonlinear activation functions. Unlike most convolutional neural networks, the joint nonlinearity is chosen to implement a form of local gain control, inspired by those used to model biological neurons. Using a variant of stochastic gradient descent, we jointly optimize the entire model for rate-distortion performance over a database of training images, introducing a continuous proxy for the discontinuous loss function arising from the quantizer. Under certain conditions, the relaxed loss function may be interpreted as the log likelihood of a generative model, as implemented by a variational autoencoder. Unlike these models, however, the compression model must operate at any given point along the rate-distortion curve, as specified by a trade-off parameter. Across an independent set of test images, we find that the optimized method generally exhibits better rate-distortion performance than the standard JPEG and JPEG 2000 compression methods. More importantly, we observe a dramatic improvement in visual quality for all images at all bit rates, which is supported by objective quality estimates using MS-SSIM.
tl;dr: A method for analyzing sentence embeddings on a fine-grained level using auxiliary prediction tasks

There is a lot of research interest in encoding variable length sentences into fixed
length vectors, in a way that preserves the sentence meanings. Two common
methods include representations based on averaging word vectors, and representations based on the hidden states of recurrent neural networks such as LSTMs.
The sentence vectors are used as features for subsequent machine learning tasks
or for pre-training in the context of deep learning. However, not much is known
about the properties that are encoded in these sentence representations and about
the language information they capture.
We propose a framework that facilitates better understanding of the encoded representations. We define prediction tasks around isolated aspects of sentence structure (namely sentence length, word content, and word order), and score representations by the ability to train a classifier to solve each prediction task when
using the representation as input. We demonstrate the potential contribution of the
approach by analyzing different sentence representation mechanisms. The analysis sheds light on the relative strengths of different sentence embedding methods with respect to these low level prediction tasks, and on the effect of the encoded
vector’s dimensionality on the resulting representations.
tl;dr: Use a graphical model as a hidden layer to perform attention over latent structures

Attention networks have proven to be an effective approach for embedding categorical inference within a deep neural network. However, for many tasks we may want to model richer structural dependencies without abandoning end-to-end training. In this work, we experiment with incorporating richer structural distributions, encoded using graphical models, within deep networks. We show that these structured attention networks are simple extensions of the basic attention procedure, and that they allow for extending attention beyond the standard soft-selection approach, such as attending to partial segmentations or to subtrees. We experiment with two different classes of structured attention networks: a linear-chain conditional random field and a graph-based parsing model, and describe how these models can be practically implemented as neural network layers. Experiments show that this approach is effective for incorporating structural biases, and structured attention networks outperform baseline attention models on a variety of synthetic and real tasks: tree transduction, neural machine translation, question answering, and natural language inference. We further find that models trained in this way learn interesting unsupervised hidden representations that generalize simple attention.
tl;dr: Acceleration of training by performing weight updates, using knowledge obtained from training other neural networks.
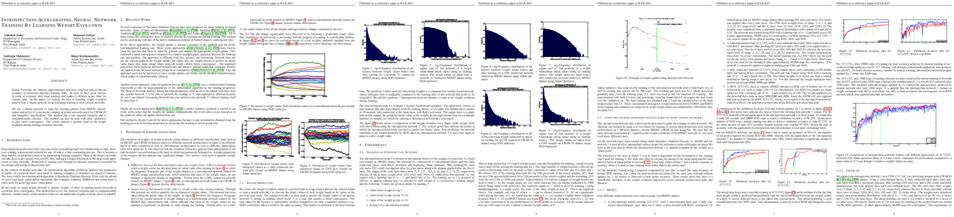
Neural Networks are function approximators that have achieved state-of-the-art accuracy in numerous machine learning tasks. In spite of their great success in terms of accuracy, their large training time makes it difficult to use them for various tasks. In this paper, we explore the idea of learning weight evolution pattern from a simple network for accelerating training of novel neural networks.
We use a neural network to learn the training pattern from MNIST classification and utilize it to accelerate training of neural networks used for CIFAR-10 and ImageNet classification. Our method has a low memory footprint and is computationally efficient. This method can also be used with other optimizers to give faster convergence. The results indicate a general trend in the weight evolution during training of neural networks.
tl;dr: This paper focuses on developing new optimization tools for deep learning that are tailored to exploit the local geometric properties of the objective function.

This paper proposes a new optimization algorithm called Entropy-SGD for training deep neural networks that is motivated by the local geometry of the energy landscape. Local extrema with low generalization error have a large proportion of almost-zero eigenvalues in the Hessian with very few positive or negative eigenvalues. We leverage upon this observation to construct a local-entropy-based objective function that favors well-generalizable solutions lying in large flat regions of the energy landscape, while avoiding poorly-generalizable solutions located in the sharp valleys. Conceptually, our algorithm resembles two nested loops of SGD where we use Langevin dynamics in the inner loop to compute the gradient of the local entropy before each update of the weights. We show that the new objective has a smoother energy landscape and show improved generalization over SGD using uniform stability, under certain assumptions. Our experiments on convolutional and recurrent neural networks demonstrate that Entropy-SGD compares favorably to state-of-the-art techniques in terms of generalization error and training time.

In this paper, we present a simple and efficient method for training deep neural networks in a semi-supervised setting where only a small portion of training data is labeled. We introduce self-ensembling, where we form a consensus prediction of the unknown labels using the outputs of the network-in-training on different epochs, and most importantly, under different regularization and input augmentation conditions. This ensemble prediction can be expected to be a better predictor for the unknown labels than the output of the network at the most recent training epoch, and can thus be used as a target for training. Using our method, we set new records for two standard semi-supervised learning benchmarks, reducing the (non-augmented) classification error rate from 18.44% to 7.05% in SVHN with 500 labels and from 18.63% to 16.55% in CIFAR-10 with 4000 labels, and further to 5.12% and 12.16% by enabling the standard augmentations. We additionally obtain a clear improvement in CIFAR-100 classification accuracy by using random images from the Tiny Images dataset as unlabeled extra inputs during training. Finally, we demonstrate good tolerance to incorrect labels.
tl;dr: An end-to-end dynamic neural network model for question answering that achieves the state of the art and best leaderboard performance on the Stanford QA dataset.

Several deep learning models have been proposed for question answering. How- ever, due to their single-pass nature, they have no way to recover from local maxima corresponding to incorrect answers. To address this problem, we introduce the Dynamic Coattention Network (DCN) for question answering. The DCN first fuses co-dependent representations of the question and the document in order to focus on relevant parts of both. Then a dynamic pointer decoder iterates over potential answer spans. This iterative procedure enables the model to recover from initial local maxima corresponding to incorrect answers. On the Stanford question answering dataset, a single DCN model improves the previous state of the art from 71.0% F1 to 75.9%, while a DCN ensemble obtains 80.4% F1.
tl;dr: Relaxed reparameterization trick for discrete stochastic units.

The reparameterization trick enables optimizing large scale stochastic computation graphs via gradient descent. The essence of the trick is to refactor each stochastic node into a differentiable function of its parameters and a random variable with fixed distribution. After refactoring, the gradients of the loss propagated by the chain rule through the graph are low variance unbiased estimators of the gradients of the expected loss. While many continuous random variables have such reparameterizations, discrete random variables lack useful reparameterizations due to the discontinuous nature of discrete states. In this work we introduce Concrete random variables -- continuous relaxations of discrete random variables. The Concrete distribution is a new family of distributions with closed form densities and a simple reparameterization. Whenever a discrete stochastic node of a computation graph can be refactored into a one-hot bit representation that is treated continuously, Concrete stochastic nodes can be used with automatic differentiation to produce low-variance biased gradients of objectives (including objectives that depend on the log-probability of latent stochastic nodes) on the corresponding discrete graph. We demonstrate the effectiveness of Concrete relaxations on density estimation and structured prediction tasks using neural networks.
tl;dr: Probabilisticly motivated image superresolution using a projection to the subspace of valid solutions

Image super-resolution (SR) is an underdetermined inverse problem, where a large number of plausible high resolution images can explain the same downsampled image. Most current single image SR methods use empirical risk minimisation, often with a pixel-wise mean squared error (MSE) loss.
However, the outputs from such methods tend to be blurry, over-smoothed and generally appear implausible. A more desirable approach would employ Maximum a Posteriori (MAP) inference, preferring solutions that always have a high probability under the image prior, and thus appear more plausible. Direct MAP estimation for SR is non-trivial, as it requires us to build a model for the image prior from samples. Here we introduce new methods for \emph{amortised MAP inference} whereby we calculate the MAP estimate directly using a convolutional neural network. We first introduce a novel neural network architecture that performs a projection to the affine subspace of valid SR solutions ensuring that the high resolution output of the network is always consistent with the low resolution input. We show that, using this architecture, the amortised MAP inference problem reduces to minimising the cross-entropy between two distributions, similar to training generative models. We propose three methods to solve this optimisation problem: (1) Generative Adversarial Networks (GAN) (2) denoiser-guided SR which backpropagates gradient-estimates from denoising to train the network, and (3) a baseline method using a maximum-likelihood-trained image prior. Our experiments show that the GAN based approach performs best on real image data. Lastly, we establish a connection between GANs and amortised variational inference as in e.g. variational autoencoders.
tl;dr: We present numerical evidence for the argument that if deep networks are trained using large (mini-)batches, they converge to sharp minimizers, and these minimizers have poor generalization properties.

The stochastic gradient descent (SGD) method and its variants are algorithms of choice for many Deep Learning tasks. These methods operate in a small-batch regime wherein a fraction of the training data, say $32$--$512$ data points, is sampled to compute an approximation to the gradient. It has been observed in practice that when using a larger batch there is a degradation in the quality of the model, as measured by its ability to generalize. We investigate the cause for this generalization drop in the large-batch regime and present numerical evidence that supports the view that large-batch methods tend to converge to sharp minimizers of the training and testing functions---and as is well known, sharp minima lead to poorer generalization. In contrast, small-batch methods consistently converge to flat minimizers, and our experiments support a commonly held view that this is due to the inherent noise in the gradient estimation. We discuss several strategies to attempt to help large-batch methods eliminate this generalization gap.

Ensembles of neural networks are known to be much more robust and accurate than individual networks. However, training multiple deep networks for model averaging is computationally expensive. In this paper, we propose a method to obtain the seemingly contradictory goal of ensembling multiple neural networks at no additional training cost. We achieve this goal by training a single neural network, converging to several local minima along its optimization path and saving the model parameters. To obtain repeated rapid convergence, we leverage recent work on cyclic learning rate schedules. The resulting technique, which we refer to as Snapshot Ensembling, is simple, yet surprisingly effective. We show in a series of experiments that our approach is compatible with diverse network architectures and learning tasks. It consistently yields lower error rates than state-of-the-art single models at no additional training cost, and compares favorably with traditional network ensembles. On CIFAR-10 and CIFAR-100 our DenseNet Snapshot Ensembles obtain error rates of 3.4% and 17.4% respectively.
tl;dr: We present a "metacontroller" neural architecture which can adaptively decide how long to run an model-based online optimization procedure for, and which models to use during the optimization.

Many machine learning systems are built to solve the hardest examples of a particular task, which often makes them large and expensive to run---especially with respect to the easier examples, which might require much less computation. For an agent with a limited computational budget, this "one-size-fits-all" approach may result in the agent wasting valuable computation on easy examples, while not spending enough on hard examples. Rather than learning a single, fixed policy for solving all instances of a task, we introduce a metacontroller which learns to optimize a sequence of "imagined" internal simulations over predictive models of the world in order to construct a more informed, and more economical, solution. The metacontroller component is a model-free reinforcement learning agent, which decides both how many iterations of the optimization procedure to run, as well as which model to consult on each iteration. The models (which we call "experts") can be state transition models, action-value functions, or any other mechanism that provides information useful for solving the task, and can be learned on-policy or off-policy in parallel with the metacontroller. When the metacontroller, controller, and experts were trained with "interaction networks" (Battaglia et al., 2016) as expert models, our approach was able to solve a challenging decision-making problem under complex non-linear dynamics. The metacontroller learned to adapt the amount of computation it performed to the difficulty of the task, and learned how to choose which experts to consult by factoring in both their reliability and individual computational resource costs. This allowed the metacontroller to achieve a lower overall cost (task loss plus computational cost) than more traditional fixed policy approaches. These results demonstrate that our approach is a powerful framework for using rich forward models for efficient model-based reinforcement learning.
tl;dr: A deep neural network to learn and combine artistic styles.

The diversity of painting styles represents a rich visual vocabulary for the construction of an image. The degree to which one may learn and parsimoniously capture this visual vocabulary measures our understanding of the higher level features of paintings, if not images in general. In this work we investigate the construction of a single, scalable deep network that can parsimoniously capture the artistic style of a diversity of paintings. We demonstrate that such a network generalizes across a diversity of artistic styles by reducing a painting to a point in an embedding space. Importantly, this model permits a user to explore new painting styles by arbitrarily combining the styles learned from individual paintings. We hope that this work provides a useful step towards building rich models of paintings and offers a window on to the structure of the learned representation of artistic style.
tl;dr: Zoneout is like dropout (for RNNs) but uses identity masks instead of zero masks

We propose zoneout, a novel method for regularizing RNNs.
At each timestep, zoneout stochastically forces some hidden units to maintain their previous values.
Like dropout, zoneout uses random noise to train a pseudo-ensemble, improving generalization.
But by preserving instead of dropping hidden units, gradient information and state information are more readily propagated through time, as in feedforward stochastic depth networks.
We perform an empirical investigation of various RNN regularizers, and find that zoneout gives significant performance improvements across tasks. We achieve competitive results with relatively simple models in character- and word-level language modelling on the Penn Treebank and Text8 datasets, and combining with recurrent batch normalization yields state-of-the-art results on permuted sequential MNIST.
tl;dr: Efficient invertible neural networks for density estimation and generation

Unsupervised learning of probabilistic models is a central yet challenging problem in machine learning. Specifically, designing models with tractable learning, sampling, inference and evaluation is crucial in solving this task. We extend the space of such models using real-valued non-volume preserving (real NVP) transformations, a set of powerful invertible and learnable transformations, resulting in an unsupervised learning algorithm with exact log-likelihood computation, exact sampling, exact inference of latent variables, and an interpretable latent space. We demonstrate its ability to model natural images on four datasets through sampling, log-likelihood evaluation and latent variable manipulations.

Machine comprehension (MC), answering a query about a given context paragraph, requires modeling complex interactions between the context and the query. Recently, attention mechanisms have been successfully extended to MC. Typically these methods use attention to focus on a small portion of the context and summarize it with a fixed-size vector, couple attentions temporally, and/or often form a uni-directional attention. In this paper we introduce the Bi-Directional Attention Flow (BIDAF) network, a multi-stage hierarchical process that represents the context at different levels of granularity and uses bi-directional attention flow mechanism to obtain a query-aware context representation without early summarization. Our experimental evaluations show that our model achieves the state-of-the-art results in Stanford Question Answering Dataset (SQuAD) and CNN/DailyMail cloze test.
tl;dr: We present an approach to sensorimotor control in immersive environments.

We present an approach to sensorimotor control in immersive environments. Our approach utilizes a high-dimensional sensory stream and a lower-dimensional measurement stream. The cotemporal structure of these streams provides a rich supervisory signal, which enables training a sensorimotor control model by interacting with the environment. The model is trained using supervised learning techniques, but without extraneous supervision. It learns to act based on raw sensory input from a complex three-dimensional environment. The presented formulation enables learning without a fixed goal at training time, and pursuing dynamically changing goals at test time. We conduct extensive experiments in three-dimensional simulations based on the classical first-person game Doom. The results demonstrate that the presented approach outperforms sophisticated prior formulations, particularly on challenging tasks. The results also show that trained models successfully generalize across environments and goals. A model trained using the presented approach won the Full Deathmatch track of the Visual Doom AI Competition, which was held in previously unseen environments.
tl;dr: Natural textures of high perceptual quality can be generated from networks with only a single layer, no pooling and random filters.

Natural image generation is currently one of the most actively explored fields in Deep Learning. Many approaches, e.g. for state-of-the-art artistic style transfer or natural texture synthesis, rely on the statistics of hierarchical representations in supervisedly trained deep neural networks. It is, however, unclear what aspects of this feature representation are crucial for natural image generation: is it the depth, the pooling or the training of the features on natural images? We here address this question for the task of natural texture synthesis and show that none of the above aspects are indispensable. Instead, we demonstrate that natural textures of high perceptual quality can be generated from networks with only a single layer, no pooling and random filters.
tl;dr: Propose a recurrent neural network architecture that can discover the underlying hierarchical structure in the temporal data.

Learning both hierarchical and temporal representation has been among the long- standing challenges of recurrent neural networks. Multiscale recurrent neural networks have been considered as a promising approach to resolve this issue, yet there has been a lack of empirical evidence showing that this type of models can actually capture the temporal dependencies by discovering the latent hierarchical structure of the sequence. In this paper, we propose a novel multiscale approach, called the hierarchical multiscale recurrent neural network, that can capture the latent hierarchical structure in the sequence by encoding the temporal dependencies with different timescales using a novel update mechanism. We show some evidence that the proposed model can discover underlying hierarchical structure in the sequences without using explicit boundary information. We evaluate our proposed model on character-level language modelling and handwriting sequence generation.
tl;dr: We make batching effective and easy to use for neural nets where every input may have a different shape (e.g. TreeRNNs).

Neural networks that compute over graph structures are a natural fit for problems in a variety of domains, including natural language (parse trees) and cheminformatics (molecular graphs). However, since the computation graph has a different shape and size for every input, such networks do not directly support batched training or inference. They are also difficult to implement in popular deep learning libraries, which are based on static data-flow graphs. We introduce a technique called dynamic batching, which not only batches together operations between different input graphs of dissimilar shape, but also between different nodes within a single input graph. The technique allows us to create static graphs, using popular libraries, that emulate dynamic computation graphs of arbitrary shape and size. We further present a high-level library of compositional blocks that simplifies the creation of dynamic graph models. Using the library, we demonstrate concise and batch-wise parallel implementations for a variety of models from the literature.
tl;dr: We introduce a method to stabilize Generative Adversarial Networks by defining the generator objective with respect to an unrolled optimization of the discriminator.

We introduce a method to stabilize Generative Adversarial Networks (GANs) by defining the generator objective with respect to an unrolled optimization of the discriminator. This allows training to be adjusted between using the optimal discriminator in the generator's objective, which is ideal but infeasible in practice, and using the current value of the discriminator, which is often unstable and leads to poor solutions. We show how this technique solves the common problem of mode collapse, stabilizes training of GANs with complex recurrent generators, and increases diversity and coverage of the data distribution by the generator.

Dropout, a simple and effective way to train deep neural networks, has led to a number of impressive empirical successes and spawned many recent theoretical investigations. However, the gap between dropout’s training and inference phases, introduced due to tractability considerations, has largely remained under-appreciated. In this work, we first formulate dropout as a tractable approximation of some latent variable model, leading to a clean view of parameter sharing and enabling further theoretical analysis. Then, we introduce (approximate) expectation-linear dropout neural networks, whose inference gap we are able to formally characterize. Algorithmically, we show that our proposed measure of the inference gap can be used to regularize the standard dropout training objective, resulting in an explicit control of the gap. Our method is as simple and efficient as standard dropout. We further prove the upper bounds on the loss in accuracy due to expectation-linearization, describe classes of input distributions that expectation-linearize easily. Experiments on three image classification benchmark datasets demonstrate that reducing the inference gap can indeed improve the performance consistently.

In this paper, we propose to equip Generative Adversarial Networks with the ability to produce direct energy estimates for samples.
Specifically, we propose a flexible adversarial training framework, and prove this framework not only ensures the generator converges to the true data distribution, but also enables the discriminator to retain the density information at the global optimal.
We derive the analytic form of the induced solution, and analyze the properties.
In order to make the proposed framework trainable in practice, we introduce two effective approximation techniques.
Empirically, the experiment results closely match our theoretical analysis, verifying the discriminator is able to recover the energy of data distribution.
tl;dr: Framework for temporal abstractions in policy space by learning to repeat actions

Reinforcement Learning algorithms can learn complex behavioral patterns for sequential decision making tasks wherein an agent interacts with an environment and acquires feedback in the form of rewards sampled from it. Traditionally, such algorithms make decisions, i.e., select actions to execute, at every single time step of the agent-environment interactions. In this paper, we propose a novel framework, Fine Grained Action Repetition (FiGAR), which enables the agent to decide the action as well as the time scale of repeating it.
FiGAR can be used for improving any Deep Reinforcement Learning algorithm which maintains an explicit policy estimate by enabling temporal abstractions in the action space and implicitly enabling planning through sequences of repetitive macro-actions.
We empirically demonstrate the efficacy of our framework by showing performance improvements on top of three policy search algorithms in different domains: Asynchronous Advantage Actor Critic in the Atari 2600 domain, Trust Region Policy Optimization in Mujoco domain and Deep Deterministic Policy Gradients in the TORCS car racing domain.
tl;dr: A new open dataset and testbed for training and evaluating end-to-end dialog systems in goal-oriented scenarios.

Traditional dialog systems used in goal-oriented applications require a lot of domain-specific handcrafting, which hinders scaling up to new domains. End- to-end dialog systems, in which all components are trained from the dialogs themselves, escape this limitation. But the encouraging success recently obtained in chit-chat dialog may not carry over to goal-oriented settings. This paper proposes a testbed to break down the strengths and shortcomings of end-to-end dialog systems in goal-oriented applications. Set in the context of restaurant reservation, our tasks require manipulating sentences and symbols, so as to properly conduct conversations, issue API calls and use the outputs of such calls. We show that an end-to-end dialog system based on Memory Networks can reach promising, yet imperfect, performance and learn to perform non-trivial operations. We confirm those results by comparing our system to a hand-crafted slot-filling baseline on data from the second Dialog State Tracking Challenge (Henderson et al., 2014a). We show similar result patterns on data extracted from an online concierge service.

Deep reinforcement learning agents have achieved state-of-the-art results by directly maximising cumulative reward. However, environments contain a much wider variety of possible training signals. In this paper, we introduce an agent that also maximises many other pseudo-reward functions simultaneously by reinforcement learning. All of these tasks share a common representation that, like unsupervised learning, continues to develop in the absence of extrinsic rewards. We also introduce a novel mechanism for focusing this representation upon extrinsic rewards, so that learning can rapidly adapt to the most relevant aspects of the actual task. Our agent significantly outperforms the previous state-of-the-art on Atari, averaging 880\% expert human performance, and a challenging suite of first-person, three-dimensional \emph{Labyrinth} tasks leading to a mean speedup in learning of 10$\times$ and averaging 87\% expert human performance on Labyrinth.
tl;dr: We propose an LSTM-based meta-learner model to learn the exact optimization algorithm used to train another learner neural network in the few-shot regime

Though deep neural networks have shown great success in the large data domain, they generally perform poorly on few-shot learning tasks, where a model has to quickly generalize after seeing very few examples from each class. The general belief is that gradient-based optimization in high capacity models requires many iterative steps over many examples to perform well. Here, we propose an LSTM-based meta-learner model to learn the exact optimization algorithm used to train another learner neural network in the few-shot regime. The parametrization of our model allows it to learn appropriate parameter updates specifically for the scenario where a set amount of updates will be made, while also learning a general initialization of the learner network that allows for quick convergence of training. We demonstrate that this meta-learning model is competitive with deep metric-learning techniques for few-shot learning.
tl;dr: We combine a policy gradient style update with a Q-learning style update into a single RL algorithm we call PGQL.

Policy gradient is an efficient technique for improving a policy in a reinforcement learning setting. However, vanilla online variants are on-policy only and not able to take advantage of off-policy data. In this paper we describe a new technique that combines policy gradient with off-policy Q-learning, drawing experience from a replay buffer. This is motivated by making a connection between the fixed points of the regularized policy gradient algorithm and the Q-values. This connection allows us to estimate the Q-values from the action preferences of the policy, to which we apply Q-learning updates. We refer to the new technique as ‘PGQL’, for policy gradient and Q-learning. We also establish an equivalency between action-value fitting techniques and actor-critic algorithms, showing that regularized policy gradient techniques can be interpreted as advantage function learning algorithms. We conclude with some numerical examples that demonstrate improved data efficiency and stability of PGQL. In particular, we tested PGQL on the full suite of Atari games and achieved performance exceeding that of both asynchronous advantage actor-critic (A3C) and Q-learning.

Two potential bottlenecks on the expressiveness of recurrent neural networks (RNNs) are their ability to store information about the task in their parameters, and to store information about the input history in their units. We show experimentally that all common RNN architectures achieve nearly the same per-task and per-unit capacity bounds with careful training, for a variety of tasks and stacking depths. They can store an amount of task information which is linear in the number of parameters, and is approximately 5 bits per parameter. They can additionally store approximately one real number from their input history per hidden unit. We further find that for several tasks it is the per-task parameter capacity bound that determines performance. These results suggest that many previous results comparing RNN architectures are driven primarily by differences in training effectiveness, rather than differences in capacity. Supporting this observation, we compare training difficulty for several architectures, and show that vanilla RNNs are far more difficult to train, yet have slightly higher capacity. Finally, we propose two novel RNN architectures, one of which is easier to train than the LSTM or GRU for deeply stacked architectures.
tl;dr: Pointer sentinel mixture models provide a method to combine a traditional vocabulary softmax with a pointer network, providing state of the art results in language modeling on PTB and the newly introduced WikiText with few extra parameters.

Recent neural network sequence models with softmax classifiers have achieved their best language modeling performance only with very large hidden states and large vocabularies. Even then they struggle to predict rare or unseen words even if the context makes the prediction unambiguous. We introduce the pointer sentinel mixture architecture for neural sequence models which has the ability to either reproduce a word from the recent context or produce a word from a standard softmax classifier. Our pointer sentinel-LSTM model achieves state of the art language modeling performance on the Penn Treebank (70.9 perplexity) while using far fewer parameters than a standard softmax LSTM. In order to evaluate how well language models can exploit longer contexts and deal with more realistic vocabularies and corpora we also introduce the freely available WikiText corpus.
tl;dr: We propose a factorization of a physical scene into composable object-based representations and also a model architecture whose compositional structure factorizes object dynamics into pairwise interactions.

We present the Neural Physics Engine (NPE), a framework for learning simulators of intuitive physics that naturally generalize across variable object count and different scene configurations. We propose a factorization of a physical scene into composable object-based representations and a neural network architecture whose compositional structure factorizes object dynamics into pairwise interactions. Like a symbolic physics engine, the NPE is endowed with generic notions of objects and their interactions; realized as a neural network, it can be trained via stochastic gradient descent to adapt to specific object properties and dynamics of different worlds. We evaluate the efficacy of our approach on simple rigid body dynamics in two-dimensional worlds. By comparing to less structured architectures, we show that the NPE's compositional representation of the structure in physical interactions improves its ability to predict movement, generalize across variable object count and different scene configurations, and infer latent properties of objects such as mass.
tl;dr: Learning representations of datasets with an extension of VAEs.

An efficient learner is one who reuses what they already know to tackle a new problem. For a machine learner, this means understanding the similarities amongst datasets. In order to do this, one must take seriously the idea of working with datasets, rather than datapoints, as the key objects to model. Towards this goal, we demonstrate an extension of a variational autoencoder that can learn a method for computing representations, or statistics, of datasets in an unsupervised fashion. The network is trained to produce statistics that encapsulate a generative model for each dataset. Hence the network enables efficient learning from new datasets for both unsupervised and supervised tasks. We show that we are able to learn statistics that can be used for: clustering datasets, transferring generative models to new datasets, selecting representative samples of datasets and classifying previously unseen classes. We refer to our model as a neural statistician, and by this we mean a neural network that can learn to compute summary statistics of datasets without supervision.

While great strides have been made in using deep learning algorithms to solve supervised learning tasks, the problem of unsupervised learning - leveraging unlabeled examples to learn about the structure of a domain - remains a difficult unsolved challenge. Here, we explore prediction of future frames in a video sequence as an unsupervised learning rule for learning about the structure of the visual world. We describe a predictive neural network ("PredNet") architecture that is inspired by the concept of "predictive coding" from the neuroscience literature. These networks learn to predict future frames in a video sequence, with each layer in the network making local predictions and only forwarding deviations from those predictions to subsequent network layers. We show that these networks are able to robustly learn to predict the movement of synthetic (rendered) objects, and that in doing so, the networks learn internal representations that are useful for decoding latent object parameters (e.g. pose) that support object recognition with fewer training views. We also show that these networks can scale to complex natural image streams (car-mounted camera videos), capturing key aspects of both egocentric movement and the movement of objects in the visual scene, and the representation learned in this setting is useful for estimating the steering angle. These results suggest that prediction represents a powerful framework for unsupervised learning, allowing for implicit learning of object and scene structure.

We introduce an exceptionally simple gated recurrent neural network (RNN) that achieves performance comparable to well-known gated architectures, such as LSTMs and GRUs, on the word-level language modeling task. We prove that our model has simple, predicable and non-chaotic dynamics. This stands in stark contrast to more standard gated architectures, whose underlying dynamical systems exhibit chaotic behavior.

Performance of machine learning algorithms depends critically on identifying a good set of hyperparameters. While recent approaches use Bayesian Optimization to adaptively select configurations, we focus on speeding up random search through adaptive resource allocation. We present Hyperband, a novel algorithm for hyperparameter optimization that is simple, flexible, and theoretically sound. Hyperband is a principled early-stoppping method that adaptively allocates a predefined resource, e.g., iterations, data samples or number of features, to randomly sampled configurations. We compare Hyperband with state-of-the-art Bayesian Optimization methods on several hyperparameter optimization problems. We observe that Hyperband can provide over an order of magnitude speedups over competitors on a variety of neural network and kernel-based learning problems.
tl;dr: We present and adverserially trained generative model with an inference network. Samples quality is high. Competitive semi-supervised results are achieved.

We introduce the adversarially learned inference (ALI) model, which jointly
learns a generation network and an inference network using an adversarial
process. The generation network maps samples from stochastic latent variables to
the data space while the inference network maps training examples in data space
to the space of latent variables. An adversarial game is cast between these two
networks and a discriminative network that is trained to distinguish between
joint latent/data-space samples from the generative network and joint samples
from the inference network. We illustrate the ability of the model to learn
mutually coherent inference and generation networks through the inspections of
model samples and reconstructions and confirm the usefulness of the learned
representations by obtaining a performance competitive with other recent
approaches on the semi-supervised SVHN task.
tl;dr: Make batch normalization work in recurrent neural networks

We propose a reparameterization of LSTM that brings the benefits of batch normalization to recurrent neural networks. Whereas previous works only apply batch normalization to the input-to-hidden transformation of RNNs, we demonstrate that it is both possible and beneficial to batch-normalize the hidden-to-hidden transition, thereby reducing internal covariate shift between time steps.
We evaluate our proposal on various sequential problems such as sequence classification, language modeling and question answering. Our empirical results show that our batch-normalized LSTM consistently leads to faster convergence and improved generalization.
tl;dr: This paper presents INQ, targeting to efficiently transform any pre-trained full-precision convolutional neural network (CNN) model into a low-precision version whose connection weights are constrained to be either powers of two or zero.

This paper presents incremental network quantization (INQ), a novel method, targeting to efficiently convert any pre-trained full-precision convolutional neural network (CNN) model into a low-precision version whose weights are constrained to be either powers of two or zero. Unlike existing methods which are struggled in noticeable accuracy loss, our INQ has the potential to resolve this issue, as benefiting from two innovations. On one hand, we introduce three interdependent operations, namely weight partition, group-wise quantization and re-training. A well-proven measure is employed to divide the weights in each layer of a pre-trained CNN model into two disjoint groups. The weights in the first group are responsible to form a low-precision base, thus they are quantized by a variable-length encoding method. The weights in the other group are responsible to compensate for the accuracy loss from the quantization, thus they are the ones to be re-trained. On the other hand, these three operations are repeated on the latest re-trained group in an iterative manner until all the weights are converted into low-precision ones, acting as an incremental network quantization and accuracy enhancement procedure. Extensive experiments on the ImageNet classification task using almost all known deep CNN architectures including AlexNet, VGG-16, GoogleNet and ResNets well testify the efficacy of the proposed method. Specifically, at 5-bit quantization (a variable-length encoding: 1 bit for representing zero value, and the remaining 4 bits represent at most 16 different values for the powers of two), our models have improved accuracy than the 32-bit floating-point references. Taking ResNet-18 as an example, we further show that our quantized models with 4-bit, 3-bit and 2-bit ternary weights have improved or very similar accuracy against its 32-bit floating-point baseline. Besides, impressive results with the combination of network pruning and INQ are also reported. We believe that our method sheds new insights on how to make deep CNNs to be applicable on mobile or embedded devices. The code will be made publicly available.
tl;dr: We present a novel form of policy gradient for model-free reinforcement learning with improved exploration properties.

This paper presents a novel form of policy gradient for model-free reinforcement learning (RL) with improved exploration properties. Current policy-based methods use entropy regularization to encourage undirected exploration of the reward landscape, which is ineffective in high dimensional spaces with sparse rewards. We propose a more directed exploration strategy that promotes exploration of under-appreciated reward regions. An action sequence is considered under-appreciated if its log-probability under the current policy under-estimates its resulting reward. The proposed exploration strategy is easy to implement, requiring only small modifications to the standard REINFORCE algorithm. We evaluate the approach on a set of algorithmic tasks that have long challenged RL methods. We find that our approach reduces hyper-parameter sensitivity and demonstrates significant improvements over baseline methods. Notably, the approach is able to solve a benchmark multi-digit addition task. To our knowledge, this is the first time that a pure RL method has solved addition using only reward feedback.
tl;dr: An ensemble optimization approach to help transfer neural network policies from simulated domains to real-world target domains.

Sample complexity and safety are major challenges when learning policies with reinforcement learning for real-world tasks, especially when the policies are represented using rich function approximators like deep neural networks. Model-based methods where the real-world target domain is approximated using a simulated source domain provide an avenue to tackle the above challenges by augmenting real data with simulated data. However, discrepancies between the simulated source domain and the target domain pose a challenge for simulated training. We introduce the EPOpt algorithm, which uses an ensemble of simulated source domains and a form of adversarial training to learn policies that are robust and generalize to a broad range of possible target domains, including to unmodeled effects. Further, the probability distribution over source domains in the ensemble can be adapted using data from the target domain and approximate Bayesian methods, to progressively make it a better approximation. Thus, learning on a model ensemble, along with source domain adaptation, provides the benefit of both robustness and learning.
tl;dr: We propose a new reinforcement learning algorithm based on zero order optimization, that we evaluate on StarCraft micromanagement scenarios.

We consider scenarios from the real-time strategy game StarCraft as benchmarks for reinforcement learning algorithms. We focus on micromanagement, that is, the short-term, low-level control of team members during a battle. We propose several scenarios that are challenging for reinforcement learning algorithms because the state- action space is very large, and there is no obvious feature representation for the value functions. We describe our approach to tackle the micromanagement scenarios with deep neural network controllers from raw state features given by the game engine. We also present a heuristic reinforcement learning algorithm which combines direct exploration in the policy space and backpropagation. This algorithm collects traces for learning using deterministic policies, which appears much more efficient than, e.g., ε-greedy exploration. Experiments show that this algorithm allows to successfully learn non-trivial strategies for scenarios with armies of up to 15 agents, where both Q-learning and REINFORCE struggle.
tl;dr: Modern binary classifiers can be easily turned into powerful two-sample tests, and used to evaluate generative models.

The goal of two-sample tests is to assess whether two samples, $S_P \sim P^n$ and $S_Q \sim Q^m$, are drawn from the same distribution. Perhaps intriguingly, one relatively unexplored method to build two-sample tests is the use of binary classifiers. In particular, construct a dataset by pairing the $n$ examples in $S_P$ with a positive label, and by pairing the $m$ examples in $S_Q$ with a negative label. If the null hypothesis ``$P = Q$'' is true, then the classification accuracy of a binary classifier on a held-out subset of this dataset should remain near chance-level. As we will show, such \emph{Classifier Two-Sample Tests} (C2ST) learn a suitable representation of the data on the fly, return test statistics in interpretable units, have a simple null distribution, and their predictive uncertainty allow to interpret where $P$ and $Q$ differ.
The goal of this paper is to establish the properties, performance, and uses of C2ST. First, we analyze their main theoretical properties. Second, we compare their performance against a variety of state-of-the-art alternatives. Third, we propose their use to evaluate the sample quality of generative models with intractable likelihoods, such as Generative Adversarial Networks (GANs). Fourth, we showcase the novel application of GANs together with C2ST for causal discovery.
tl;dr: A simple unsupervised method for sentence embedding that can get results comparable to sophisticated models like RNN's and LSTM's

The success of neural network methods for computing word embeddings has motivated methods for generating semantic embeddings of longer pieces of text, such as sentences and paragraphs. Surprisingly, Wieting et al (ICLR'16) showed that such complicated methods are outperformed, especially in out-of-domain (transfer learning) settings, by simpler methods involving mild retraining of word embeddings and basic linear regression. The method of Wieting et al. requires retraining with a substantial labeled dataset such as Paraphrase Database (Ganitkevitch et al., 2013).
The current paper goes further, showing that the following completely unsupervised sentence embedding is a formidable baseline: Use word embeddings computed using one of the popular methods on unlabeled corpus like Wikipedia, represent the sentence by a weighted average of the word vectors, and then modify them a bit using PCA/SVD. This weighting improves performance by about 10% to 30% in textual similarity tasks, and beats sophisticated supervised methods including RNN's and LSTM's. It even improves Wieting et al.'s embeddings.
This simple method should be used as the baseline to beat in future, especially when labeled training data is scarce or nonexistent.
The paper also gives a theoretical explanation of the success of the above unsupervised method using a latent variable generative model for sentences, which is a simple extension of the model in Arora et al. (TACL'16) with new "smoothing" terms that allow for
words occurring out of context, as well as high probabilities for words like and, not in all contexts.
tl;dr: We propose a framework for learning a diverse set of skills using stochastic neural networks with minimum supervision, and utilize these skills in a hierarchical architecture to solve challenging tasks with sparse rewards

Deep reinforcement learning has achieved many impressive results in recent years. However, tasks with sparse rewards or long horizons continue to pose significant challenges. To tackle these important problems, we propose a general framework that first learns useful skills in a pre-training environment, and then leverages the acquired skills for learning faster in downstream tasks.
Our approach brings together some of the strengths of intrinsic motivation and hierarchical methods: the learning of useful skill is guided by a single proxy reward, the design of which requires very minimal domain knowledge about the downstream tasks. Then a high-level policy is trained on top of these skills, providing a significant improvement of the exploration and allowing to tackle sparse rewards in the downstream tasks. To efficiently pre-train a large span of skills, we use Stochastic Neural Networks combined with an information-theoretic regularizer. Our experiments show that this combination is effective in learning a wide span of interpretable skills in a sample-efficient way, and can significantly boost the learning performance uniformly across a wide range of downstream tasks.
tl;dr: A deep neural network that saves computation on temporal data by using neurons that only communicate their changes in activation

Deep neural networks can be obscenely wasteful. When processing video, a convolutional network expends a fixed amount of computation for each frame with no regard to the similarity between neighbouring frames. As a result, it ends up repeatedly doing very similar computations. To put an end to such waste, we introduce Sigma-Delta networks. With each new input, each layer in this network sends a discretized form of its change in activation to the next layer. Thus the amount of computation that the network does scales with the amount of change in the input and layer activations, rather than the size of the network. We introduce an optimization method for converting any pre-trained deep network into an optimally efficient Sigma-Delta network, and show that our algorithm, if run on the appropriate hardware, could cut at least an order of magnitude from the computational cost of processing video data.

Sequence-to-sequence models rely on a fixed decomposition of the target sequences into a sequence of tokens that may be words, word-pieces or characters. The choice of these tokens and the decomposition of the target sequences into a sequence of tokens is often static, and independent of the input, output data domains. This can potentially lead to a sub-optimal choice of token dictionaries, as the decomposition is not informed by the particular problem being solved. In this paper we present Latent Sequence Decompositions (LSD), a framework in which the decomposition of sequences into constituent tokens is learnt during the training of the model. The decomposition depends both on the input sequence and on the output sequence. In LSD, during training, the model samples decompositions incrementally, from left to right by locally sampling between valid extensions. We experiment with the Wall Street Journal speech recognition task. Our LSD model achieves 12.9% WER compared to a character baseline of 14.8% WER. When combined with a convolutional network on the encoder, we achieve a WER of 9.6%.
tl;dr: We propose a novel training algorithm for reinforcement learning which combines the strength of deep Q-learning with a constrained optimization approach to tighten optimality and encourage faster reward propagation.

We propose a novel training algorithm for reinforcement learning which combines the strength of deep Q-learning with a constrained optimization approach to tighten optimality and encourage faster reward propagation. Our novel technique makes deep reinforcement learning more practical by drastically reducing the training time. We evaluate the performance of our approach on the 49 games of the challenging Arcade Learning Environment, and report significant improvements in both training time and accuracy.
tl;dr: We introduce the "Energy-based Generative Adversarial Network" (EBGAN) model.

We introduce the "Energy-based Generative Adversarial Network" model (EBGAN) which views the discriminator as an energy function that attributes low energies to the regions near the data manifold and higher energies to other regions. Similar to the probabilistic GANs, a generator is seen as being trained to produce contrastive samples with minimal energies, while the discriminator is trained to assign high energies to these generated samples. Viewing the discriminator as an energy function allows to use a wide variety of architectures and loss functionals in addition to the usual binary classifier with logistic output. Among them, we show one instantiation of EBGAN framework as using an auto-encoder architecture, with the energy being the reconstruction error, in place of the discriminator. We show that this form of EBGAN exhibits more stable behavior than regular GANs during training. We also show that a single-scale architecture can be trained to generate high-resolution images.
tl;dr: We investigate how a bot can benefit from interacting with users and asking questions.

A good dialogue agent should have the ability to interact with users by both responding to questions and by asking questions, and importantly to learn from both types of interactions. In this work, we explore this direction by designing a simulator and a set of synthetic tasks in the movie domain that allow such interactions between a learner and a teacher. We investigate how a learner can benefit from asking questions in both offline and online reinforcement learning settings, and demonstrate that the learner improves when asking questions. Our work represents a first step in developing such end-to-end learned interactive dialogue agents.
tl;dr: We use deep semantic features, learned predictive dynamics, and reinforcement learning to efficiently learn a visual servoing policy that is robust to visual variations.

Visual servoing involves choosing actions that move a robot in response to observations from a camera, in order to reach a goal configuration in the world. Standard visual servoing approaches typically rely on manually designed features and analytical dynamics models, which limits their generalization capability and often requires extensive application-specific feature and model engineering. In this work, we study how learned visual features, learned predictive dynamics models, and reinforcement learning can be combined to learn visual servoing mechanisms. We focus on target following, with the goal of designing algorithms that can learn a visual servo using low amounts of data of the target in question, to enable quick adaptation to new targets. Our approach is based on servoing the camera in the space of learned visual features, rather than image pixels or manually-designed keypoints. We demonstrate that standard deep features, in our case taken from a model trained for object classification, can be used together with a bilinear predictive model to learn an effective visual servo that is robust to visual variation, changes in viewing angle and appearance, and occlusions. A key component of our approach is to use a sample-efficient fitted Q-iteration algorithm to learn which features are best suited for the task at hand. We show that we can learn an effective visual servo on a complex synthetic car following benchmark using just 20 training trajectory samples for reinforcement learning. We demonstrate substantial improvement over a conventional approach based on image pixels or hand-designed keypoints, and we show an improvement in sample-efficiency of more than two orders of magnitude over standard model-free deep reinforcement learning algorithms. Videos are available at http://rll.berkeley.edu/visual_servoing.
tl;dr: New approach for removing unnecessary conv neurons from network. Work is focused on how to estimate importance fast and efficiently by Taylor expantion.

We propose a new formulation for pruning convolutional kernels in neural networks to enable efficient inference. We interleave greedy criteria-based pruning with fine-tuning by backpropagation-a computationally efficient procedure that maintains good generalization in the pruned network. We propose a new criterion based on Taylor expansion that approximates the change in the cost function induced by pruning network parameters. We focus on transfer learning, where large pretrained networks are adapted to specialized tasks. The proposed criterion demonstrates superior performance compared to other criteria, e.g. the norm of kernel weights or feature map activation, for pruning large CNNs after adaptation to fine-grained classification tasks (Birds-200 and Flowers-102) relaying only on the first order gradient information. We also show that pruning can lead to more than 10x theoretical reduction in adapted 3D-convolutional filters with a small drop in accuracy in a recurrent gesture classifier. Finally, we show results for the large-scale ImageNet dataset to emphasize the flexibility of our approach.
tl;dr: A new method for hidden activation distribution matching in the context of domain adaptation.

The learning of domain-invariant representations in the context of domain adaptation with neural networks is considered. We propose a new regularization method that minimizes the domain-specific latent feature representations directly in the hidden activation space. Although some standard distribution matching approaches exist that can be interpreted as the matching of weighted sums of moments, e.g. Maximum Mean Discrepancy (MMD), an explicit order-wise matching of higher order moments has not been considered before.
We propose to match the higher order central moments of probability distributions by means of order-wise moment differences. Our model does not require computationally expensive distance and kernel matrix computations. We utilize the equivalent representation of probability distributions by moment sequences to define a new distance function, called Central Moment Discrepancy (CMD). We prove that CMD is a metric on the set of probability distributions on a compact interval. We further prove that convergence of probability distributions on compact intervals w.r.t. the new metric implies convergence in distribution of the respective random variables.
We test our approach on two different benchmark data sets for object recognition (Office) and sentiment analysis of product reviews (Amazon reviews). CMD achieves a new state-of-the-art performance on most domain adaptation tasks of Office and outperforms networks trained with MMD, Variational Fair Autoencoders and Domain Adversarial Neural Networks on Amazon reviews. In addition, a post-hoc parameter sensitivity analysis shows that the new approach is stable w. r. t. parameter changes in a certain interval. The source code of the experiments is publicly available.
tl;dr: We propose Q-Prop, a novel policy gradient method with an off-policy critic as control variate, that is more sample efficient than TRPO-GAE and more stable than DDPG, the state-of-the-art on-policy and off-policy methods.

Model-free deep reinforcement learning (RL) methods have been successful in a wide variety of simulated domains. However, a major obstacle facing deep RL in the real world is their high sample complexity. Batch policy gradient methods offer stable learning, but at the cost of high variance, which often requires large batches. TD-style methods, such as off-policy actor-critic and Q-learning, are more sample-efficient but biased, and often require costly hyperparameter sweeps to stabilize. In this work, we aim to develop methods that combine the stability of policy gradients with the efficiency of off-policy RL. We present Q-Prop, a policy gradient method that uses a Taylor expansion of the off-policy critic as a control variate. Q-Prop is both sample efficient and stable, and effectively combines the benefits of on-policy and off-policy methods. We analyze the connection between Q-Prop and existing model-free algorithms, and use control variate theory to derive two variants of Q-Prop with conservative and aggressive adaptation. We show that conservative Q-Prop provides substantial gains in sample efficiency over trust region policy optimization (TRPO) with generalized advantage estimation (GAE), and improves stability over deep deterministic policy gradient (DDPG), the state-of-the-art on-policy and off-policy methods, on OpenAI Gym's MuJoCo continuous control environments.

We use reinforcement learning to learn
tree-structured neural networks for computing representations of natural language sentences.
In contrast with prior work on tree-structured models, in which the trees are either provided as input or
predicted using supervision from explicit treebank annotations,
the tree structures in this work are optimized to improve performance on a downstream task.
Experiments demonstrate the benefit of
learning task-specific composition orders, outperforming both sequential encoders and recursive encoders based on treebank annotations.
We analyze the induced trees and show that while they discover
some linguistically intuitive structures (e.g., noun phrases, simple verb phrases),
they are different than conventional English syntactic structures.

The ability of the Generative Adversarial Networks (GANs) framework to learn generative models mapping from simple latent distributions to arbitrarily complex data distributions has been demonstrated empirically, with compelling results showing generators learn to "linearize semantics" in the latent space of such models. Intuitively, such latent spaces may serve as useful feature representations for auxiliary problems where semantics are relevant. However, in their existing form, GANs have no means of learning the inverse mapping -- projecting data back into the latent space. We propose Bidirectional Generative Adversarial Networks (BiGANs) as a means of learning this inverse mapping, and demonstrate that the resulting learned feature representation is useful for auxiliary supervised discrimination tasks, competitive with contemporary approaches to unsupervised and self-supervised feature learning.
tl;dr: Drastically reducing the number of parameters, when the number of input features is orders of magnitude larger than the number of training examples, such as in genomics.

Learning tasks such as those involving genomic data often poses a serious challenge: the number of input features can be orders of magnitude larger than the number of training examples, making it difficult to avoid overfitting, even when using the known regularization techniques. We focus here on tasks in which the input is a description of the genetic variation specific to a patient, the single nucleotide polymorphisms (SNPs), yielding millions of ternary inputs. Improving the ability of deep learning to handle such datasets could have an important impact in medical research, more specifically in precision medicine, where high-dimensional data regarding a particular patient is used to make predictions of interest. Even though the amount of data for such tasks is increasing, this mismatch between the number of examples and the number of inputs remains a concern. Naive implementations of classifier neural networks involve a huge number of free parameters in their first layer (number of input features times number of hidden units): each input feature is associated with as many parameters as there are hidden units. We propose a novel neural network parametrization which considerably reduces the number of free parameters. It is based on the idea that we can first learn or provide a distributed representation for each input feature (e.g. for each position in the genome where variations are observed in data), and then learn (with another neural network called the parameter prediction network) how to map a feature's distributed representation (based on the feature's identity not its value) to the vector of parameters specific to that feature in the classifier neural network (the weights which link the value of the feature to each of the hidden units). This approach views the problem of producing the parameters associated with each feature as a multi-task learning problem. We show experimentally on a population stratification task of interest to medical studies that the proposed approach can significantly reduce both the number of parameters and the error rate of the classifier.

In this paper, we propose TopicRNN, a recurrent neural network (RNN)-based language model designed to directly capture the global semantic meaning relating words in a document via latent topics. Because of their sequential nature, RNNs are good at capturing the local structure of a word sequence – both semantic and syntactic – but might face difficulty remembering long-range dependencies. Intuitively, these long-range dependencies are of semantic nature. In contrast, latent topic models are able to capture the global underlying semantic structure of a document but do not account for word ordering. The proposed TopicRNN model integrates the merits of RNNs and latent topic models: it captures local (syntactic) dependencies using an RNN and global (semantic) dependencies using latent topics. Unlike previous work on contextual RNN language modeling, our model is learned end-to-end. Empirical results on word prediction show that TopicRNN outperforms existing contextual RNN baselines. In addition, TopicRNN can be used as an unsupervised feature extractor for documents. We do this for sentiment analysis on the IMDB movie review dataset and report an error rate of 6.28%. This is comparable to the state-of-the-art 5.91% resulting from a semi-supervised approach. Finally, TopicRNN also yields sensible topics, making it a useful alternative to document models such as latent Dirichlet allocation.

Network quantization is one of network compression techniques to reduce the redundancy of deep neural networks. It reduces the number of distinct network parameter values by quantization in order to save the storage for them. In this paper, we design network quantization schemes that minimize the performance loss due to quantization given a compression ratio constraint. We analyze the quantitative relation of quantization errors to the neural network loss function and identify that the Hessian-weighted distortion measure is locally the right objective function for the optimization of network quantization. As a result, Hessian-weighted k-means clustering is proposed for clustering network parameters to quantize. When optimal variable-length binary codes, e.g., Huffman codes, are employed for further compression, we derive that the network quantization problem can be related to the entropy-constrained scalar quantization (ECSQ) problem in information theory and consequently propose two solutions of ECSQ for network quantization, i.e., uniform quantization and an iterative solution similar to Lloyd's algorithm. Finally, using the simple uniform quantization followed by Huffman coding, we show from our experiments that the compression ratios of 51.25, 22.17 and 40.65 are achievable for LeNet, 32-layer ResNet and AlexNet, respectively.
tl;dr: DeepDSL(a DSL embedded in Scala) that compiles deep learning networks written in DeepDSL to Java source code, which runs on any GPU equipped machines with competitive efficiency as existing state-of-the-art tools (e.g. Caffe and Tensorflow)

In recent years, Deep Learning (DL) has found great success in domains such as multimedia understanding. However, the complex nature of multimedia data makes it difficult to develop DL-based software. The state-of-the-art tools, such as Caffe, TensorFlow, Torch7, and CNTK, while are successful in their applicable domains, are programming libraries with fixed user interface, internal representation, and execution environment. This makes it difficult to implement portable and customized DL applications.
In this paper, we present DeepDSL, a domain specific language (DSL) embedded in Scala, that compiles deep networks written in DeepDSL to Java source code. Deep DSL provides
(1) intuitive constructs to support compact encoding of deep networks;
(2) symbolic gradient derivation of the networks;
(3) static analysis for memory consumption and error detection; and
(4) DSL-level optimization to improve memory and runtime efficiency.
DeepDSL programs are compiled into compact, efficient, customizable, and portable Java source code, which operates the CUDA and CUDNN interfaces running on NVIDIA GPU via a Java Native Interface (JNI) library. We evaluated DeepDSL with a number of popular DL networks. Our experiments show that the compiled programs have very competitive runtime performance and memory efficiency compared to the existing libraries.

Recently there has been much interest in understanding why deep neural networks are preferred to shallow networks. We show that, for a large class of piecewise smooth functions, the number of neurons needed by a shallow network to approximate a function is exponentially larger than the corresponding number of neurons needed by a deep network for a given degree of function approximation. First, we consider univariate functions on a bounded interval and require a neural network to achieve an approximation error of $\varepsilon$ uniformly over the interval. We show that shallow networks (i.e., networks whose depth does not depend on $\varepsilon$) require $\Omega(\text{poly}(1/\varepsilon))$ neurons while deep networks (i.e., networks whose depth grows with $1/\varepsilon$) require $\mathcal{O}(\text{polylog}(1/\varepsilon))$ neurons. We then extend these results to certain classes of important multivariate functions. Our results are derived for neural networks which use a combination of rectifier linear units (ReLUs) and binary step units, two of the most popular type of activation functions. Our analysis builds on a simple observation: the multiplication of two bits can be represented by a ReLU.
70. Steerable CNNs

It has long been recognized that the invariance and equivariance properties of a representation are critically important for success in many vision tasks. In this paper we present Steerable Convolutional Neural Networks, an efficient and flexible class of equivariant convolutional networks. We show that steerable CNNs achieve state of the art results on the CIFAR image classification benchmark. The mathematical theory of steerable representations reveals a type system in which any steerable representation is a composition of elementary feature types, each one associated with a particular kind of symmetry. We show how the parameter cost of a steerable filter bank depends on the types of the input and output features, and show how to use this knowledge to construct CNNs that utilize parameters effectively.
tl;dr: We introduce a word importance score for LSTMs, and show that we can use it to replicate an LSTM's performance using a simple, rules-based classifier.

Although deep learning models have proven effective at solving problems in natural language processing, the mechanism by which they come to their conclusions is often unclear. As a result, these models are generally treated as black boxes, yielding no insight of the underlying learned patterns. In this paper we consider Long Short Term Memory networks (LSTMs) and demonstrate a new approach for tracking the importance of a given input to the LSTM for a given output. By identifying consistently important patterns of words, we are able to distill state of the art LSTMs on sentiment analysis and question answering into a set of representative phrases. This representation is then quantitatively validated by using the extracted phrases to construct a simple, rule-based classifier which approximates the output of the LSTM.
tl;dr: DSD effectively achieves superior optimization performance on a wide range of deep neural networks.

Modern deep neural networks have a large number of parameters, making them very hard to train. We propose DSD, a dense-sparse-dense training flow, for regularizing deep neural networks and achieving better optimization performance. In the first D (Dense) step, we train a dense network to learn connection weights and importance. In the S (Sparse) step, we regularize the network by pruning the unimportant connections with small weights and retraining the network given the sparsity constraint. In the final D (re-Dense) step, we increase the model capacity by removing the sparsity constraint, re-initialize the pruned parameters from zero and retrain the whole dense network. Experiments show that DSD training can improve the performance for a wide range of CNNs, RNNs and LSTMs on the tasks of image classification, caption generation and speech recognition. On ImageNet, DSD improved the Top1 accuracy of GoogLeNet by 1.1%, VGG-16 by 4.3%, ResNet-18 by 1.2% and ResNet-50 by 1.1%, respectively. On the WSJ’93 dataset, DSD improved DeepSpeech and DeepSpeech2 WER by 2.0% and 1.1%. On the Flickr-8K dataset, DSD improved the NeuralTalk BLEU score by over 1.7. DSD is easy to use in practice: at training time, DSD incurs only one extra hyper-parameter: the sparsity ratio in the S step. At testing time, DSD doesn’t change the network architecture or incur any inference overhead. The consistent and significant performance gain of DSD experiments shows the inadequacy of the current training methods for finding the best local optimum, while DSD effectively achieves superior optimization performance for finding a better solution. DSD models are available to download at https://songhan.github.io/DSD.

The current mainstream approach to train natural language systems is to expose them to large amounts of text. This passive learning is problematic if we are in- terested in developing interactive machines, such as conversational agents. We propose a framework for language learning that relies on multi-agent communi- cation. We study this learning in the context of referential games. In these games, a sender and a receiver see a pair of images. The sender is told one of them is the target and is allowed to send a message to the receiver, while the receiver must rely on it to identify the target. Thus, the agents develop their own language interactively out of the need to communicate. We show that two networks with simple configurations are able to learn to coordinate in the referential game. We further explore whether the “word meanings” induced in the game reflect intuitive semantic properties of the objects depicted in the image, and we present a simple strategy for grounding the agents’ code into natural language, a necessary step in developing machines that should eventually be able to communicate with humans.
tl;dr: A general "compare-aggregate" framework that performs word-level matching followed by aggregation using Convolutional Neural Networks

Many NLP tasks including machine comprehension, answer selection and text entailment require the comparison between sequences. Matching the important units between sequences is a key to solve these problems. In this paper, we present a general "compare-aggregate" framework that performs word-level matching followed by aggregation using Convolutional Neural Networks. We particularly focus on the different comparison functions we can use to match two vectors. We use four different datasets to evaluate the model. We find that some simple comparison functions based on element-wise operations can work better than standard neural network and neural tensor network.
tl;dr: We learn a markov transition operator acting on inputspace, to denoise random noise into a target distribution. We use a novel target injection technique to guide the training.

In this work, we investigate a novel training procedure to learn a generative model as the transition operator of a Markov chain, such that, when applied repeatedly on an unstructured random noise sample, it will denoise it into a sample that matches the target distribution from the training set. The novel training procedure to learn this progressive denoising operation involves sampling from a slightly different chain than the model chain used for generation in the absence of a denoising target. In the training chain we infuse information from the training target example that we would like the chains to reach with a high probability. The thus learned transition operator is able to produce quality and varied samples in a small number of steps. Experiments show competitive results compared to the samples generated with a basic Generative Adversarial Net.
tl;dr: We use soft weight-sharing to compress neural network weights.

The success of deep learning in numerous application domains created the desire to run and train them on mobile devices. This however, conflicts with their computationally, memory and energy intense nature, leading to a growing interest in compression.
Recent work by Han et al. (2016) propose a pipeline that involves retraining, pruning and quantization of neural network weights, obtaining state-of-the-art compression rates.
In this paper, we show that competitive compression rates can be achieved by using a version of "soft weight-sharing" (Nowlan & Hinton, 1991). Our method achieves both quantization and pruning in one simple (re-)training procedure.
This point of view also exposes the relation between compression and the minimum description length (MDL) principle.
tl;dr: We introduce a memory module for life-long learning that adds one-shot learning capability to any supervised neural network.

Despite recent advances, memory-augmented deep neural networks are still limited
when it comes to life-long and one-shot learning, especially in remembering rare events.
We present a large-scale life-long memory module for use in deep learning.
The module exploits fast nearest-neighbor algorithms for efficiency and
thus scales to large memory sizes.
Except for the nearest-neighbor query, the module is fully differentiable
and trained end-to-end with no extra supervision. It operates in
a life-long manner, i.e., without the need to reset it during training.
Our memory module can be easily added to any part of a supervised neural network.
To show its versatility we add it to a number of networks, from simple
convolutional ones tested on image classification to deep sequence-to-sequence
and recurrent-convolutional models.
In all cases, the enhanced network gains the ability to remember
and do life-long one-shot learning.
Our module remembers training examples shown many thousands
of steps in the past and it can successfully generalize from them.
We set new state-of-the-art for one-shot learning on the Omniglot dataset
and demonstrate, for the first time, life-long one-shot learning in
recurrent neural networks on a large-scale machine translation task.

Maximum entropy modeling is a flexible and popular framework for formulating statistical models given partial knowledge. In this paper, rather than the traditional method of optimizing over the continuous density directly, we learn a smooth and invertible transformation that maps a simple distribution to the desired maximum entropy distribution. Doing so is nontrivial in that the objective being maximized (entropy) is a function of the density itself. By exploiting recent developments in normalizing flow networks, we cast the maximum entropy problem into a finite-dimensional constrained optimization, and solve the problem by combining stochastic optimization with the augmented Lagrangian method. Simulation results demonstrate the effectiveness of our method, and applications to finance and computer vision show the flexibility and accuracy of using maximum entropy flow networks.

Large computer-understandable proofs consist of millions of intermediate
logical steps. The vast majority of such steps originate from manually
selected and manually guided heuristics applied to intermediate goals.
So far, machine learning has generally not been used to filter or
generate these steps. In this paper, we introduce a new dataset based on
Higher-Order Logic (HOL) proofs, for the purpose of developing new
machine learning-based theorem-proving strategies. We make this dataset
publicly available under the BSD license. We propose various machine
learning tasks that can be performed on this dataset, and discuss their
significance for theorem proving. We also benchmark a set of simple baseline
machine learning models suited for the tasks (including logistic regression
convolutional neural networks and recurrent neural networks). The results of our
baseline models show the promise of applying machine learning to HOL
theorem proving.
tl;dr: Showing connections between GANs, ABC, ratio estimation and other approaches for learning in deep generative models.

Generative adversarial networks (GANs) provide an algorithmic framework for constructing generative models with several appealing properties: they do not require a likelihood function to be specified, only a generating procedure; they provide samples that are sharp and compelling; and they allow us to harness our knowledge of building highly accurate neural network classifiers. Here, we develop our understanding of GANs with the aim of forming a rich view of this growing area of machine learning---to build connections to the diverse set of statistical thinking on this topic, of which much can be gained by a mutual exchange of ideas. We frame GANs within the wider landscape of algorithms for learning in implicit generative models---models that only specify a stochastic procedure with which to generate data---and relate these ideas to modelling problems in related fields, such as econometrics and approximate Bayesian computation. We develop likelihood-free inference methods and highlight hypothesis testing as a principle for learning in implicit generative models, using which we are able to derive the objective function used by GANs, and many other related objectives. The testing viewpoint directs our focus to the general problem of density ratio estimation. There are four approaches for density ratio estimation, one of which is a solution using classifiers to distinguish real from generated data. Other approaches such as divergence minimisation and moment matching have also been explored in the GAN literature, and we synthesise these views to form an understanding in terms of the relationships between them and the wider literature, highlighting avenues for future exploration and cross-pollination.
tl;dr: A way to optimize the power of an MMD test, to use it for evaluating generative models and training GANs

We propose a method to optimize the representation and distinguishability of samples from two probability distributions, by maximizing the estimated power of a statistical test based on the maximum mean discrepancy (MMD). This optimized MMD is applied to the setting of unsupervised learning by generative adversarial networks (GAN), in which a model attempts to generate realistic samples, and a discriminator attempts to tell these apart from data samples. In this context, the MMD may be used in two roles: first, as a discriminator, either directly on the samples, or on features of the samples. Second, the MMD can be used to evaluate the performance of a generative model, by testing the model’s samples against a reference data set. In the latter role, the optimized MMD is particularly helpful, as it gives an interpretable indication of how the model and data distributions differ, even in cases where individual model samples are not easily distinguished either by eye or by classifier.

We propose an extension to neural network language models to adapt their prediction to the recent history. Our model is a simplified version of memory augmented networks, which stores past hidden activations as memory and accesses them through a dot product with the current hidden activation. This mechanism is very efficient and scales to very large memory sizes. We also draw a link between the use of external memory in neural network and cache models used with count based language models. We demonstrate on several language model datasets that our approach performs significantly better than recent memory augmented networks.
83. HyperNetworks
tl;dr: We train a small RNN to generate weights for a larger RNN, and train the system end-to-end. We obtain state-of-the-art results on a variety of sequence modelling tasks.

This work explores hypernetworks: an approach of using one network, also known as a hypernetwork, to generate the weights for another network. We apply hypernetworks to generate adaptive weights for recurrent networks. In this case, hypernetworks can be viewed as a relaxed form of weight-sharing across layers. In our implementation, hypernetworks are are trained jointly with the main network in an end-to-end fashion. Our main result is that hypernetworks can generate non-shared weights for LSTM and achieve state-of-the-art results on a variety of sequence modelling tasks including character-level language modelling, handwriting generation and neural machine translation, challenging the weight-sharing paradigm for recurrent networks.
tl;dr: We propose an algorithm for generalizing a deep neural network policy using "unlabeled" experience collected in MDPs where rewards are not available.

Deep reinforcement learning (RL) can acquire complex behaviors from low-level inputs, such as images. However, real-world applications of such methods require generalizing to the vast variability of the real world. Deep networks are known to achieve remarkable generalization when provided with massive amounts of labeled data, but can we provide this breadth of experience to an RL agent, such as a robot? The robot might continuously learn as it explores the world around it, even while it is deployed and performing useful tasks. However, this learning requires access to a reward function, to tell the agent whether it is succeeding or failing at its task. Such reward functions are often hard to measure in the real world, especially in domains such as robotics and dialog systems, where the reward could depend on the unknown positions of objects or the emotional state of the user. On the other hand, it is often quite practical to provide the agent with reward functions in a limited set of situations, such as when a human supervisor is present, or in a controlled laboratory setting. Can we make use of this limited supervision, and still benefit from the breadth of experience an agent might collect in the unstructured real world? In this paper, we formalize this problem setting as semi-supervised reinforcement learning (SSRL), where the reward function can only be evaluated in a set of “labeled” MDPs, and the agent must generalize its behavior to the wide range of states it might encounter in a set of “unlabeled” MDPs, by using experience from both settings. Our proposed method infers the task objective in the unlabeled MDPs through an algorithm that resembles inverse RL, using the agent’s own prior experience in the labeled MDPs as a kind of demonstration of optimal behavior. We evaluate our method on challenging, continuous control tasks that require control directly from images, and show that our approach can improve the generalization of a learned deep neural network policy by using experience for which no reward function is available. We also show that our method outperforms direct supervised learning of the reward.
tl;dr: We show that that models regularized with local feature decorrelation have lower overfitting.

Regularization is key for deep learning since it allows training more complex models while keeping lower levels of overfitting. However, the most prevalent regularizations do not leverage all the capacity of the models since they rely on reducing the effective number of parameters. Feature decorrelation is an alternative for using the full capacity of the models but the overfitting reduction margins are too narrow given the overhead it introduces. In this paper, we show that regularizing negatively correlated features is an obstacle for effective decorrelation and present OrthoReg, a novel regularization technique that locally enforces feature orthogonality. As a result, imposing locality constraints in feature decorrelation removes interferences between negatively correlated feature weights, allowing the regularizer to reach higher decorrelation bounds, and reducing the overfitting more effectively.
In particular, we show that the models regularized with OrthoReg have higher accuracy bounds even when batch normalization and dropout are present. Moreover, since our regularization is directly performed on the weights, it is especially suitable for fully convolutional neural networks, where the weight space is constant compared to the feature map space. As a result, we are able to reduce the overfitting of state-of-the-art CNNs on CIFAR-10, CIFAR-100, and SVHN.
tl;dr: A new memory-augmented model which learns to track the world state, obtaining SOTA on the bAbI tasks amongst other results.

We introduce a new model, the Recurrent Entity Network (EntNet). It is equipped
with a dynamic long-term memory which allows it to maintain and update a rep-
resentation of the state of the world as it receives new data. For language under-
standing tasks, it can reason on-the-fly as it reads text, not just when it is required
to answer a question or respond as is the case for a Memory Network (Sukhbaatar
et al., 2015). Like a Neural Turing Machine or Differentiable Neural Computer
(Graves et al., 2014; 2016) it maintains a fixed size memory and can learn to
perform location and content-based read and write operations. However, unlike
those models it has a simple parallel architecture in which several memory loca-
tions can be updated simultaneously. The EntNet sets a new state-of-the-art on
the bAbI tasks, and is the first method to solve all the tasks in the 10k training
examples setting. We also demonstrate that it can solve a reasoning task which
requires a large number of supporting facts, which other methods are not able to
solve, and can generalize past its training horizon. It can also be practically used
on large scale datasets such as Children’s Book Test, where it obtains competitive
performance, reading the story in a single pass.
tl;dr: We propose a general architecture for transfer that can avoid negative transfer and transfer selectively from multiple source tasks in the same domain.

Transferring knowledge from prior source tasks in solving a new target task can be useful in several learning applications. The application of transfer poses two serious challenges which have not been adequately addressed. First, the agent should be able to avoid negative transfer, which happens when the transfer hampers or slows down the learning instead of helping it. Second, the agent should be able to selectively transfer, which is the ability to select and transfer from different and multiple source tasks for different parts of the state space of the target task. We propose A2T (Attend Adapt and Transfer), an attentive deep architecture which adapts and transfers from these source tasks. Our model is generic enough to effect transfer of either policies or value functions. Empirical evaluations on different learning algorithms show that A2T is an effective architecture for transfer by being able to avoid negative transfer while transferring selectively from multiple source tasks in the same domain.
tl;dr: Method for visualizing evidence for and against deep convolutional neural network classification decisions in a given input image.

This article presents the prediction difference analysis method for visualizing the response of a deep neural network to a specific input. When classifying images, the method highlights areas in a given input image that provide evidence for or against a certain class. It overcomes several shortcoming of previous methods and provides great additional insight into the decision making process of classifiers. Making neural network decisions interpretable through visualization is important both to improve models and to accelerate the adoption of black-box classifiers in application areas such as medicine. We illustrate the method in experiments on natural images (ImageNet data), as well as medical images (MRI brain scans).
tl;dr: We investigate various memory-augmented neural language models and compare them against state-of-the-art architectures.

Current language modeling architectures often use recurrent neural networks. Recently, various methods for incorporating differentiable memory into these architectures have been proposed. When predicting the next token, these models query information from a memory of the recent history and thus can facilitate learning mid- and long-range dependencies. However, conventional attention models produce a single output vector per time step that is used for predicting the next token as well as the key and value of a differentiable memory of the history of tokens. In this paper, we propose a key-value attention mechanism that produces separate representations for the key and value of a memory, and for a representation that encodes the next-word distribution. This usage of past memories outperforms existing memory-augmented neural language models on two corpora. Yet, we found that it mainly utilizes past memory only of the previous five representations. This led to the unexpected main finding that a much simpler model which simply uses a concatenation of output representations from the previous three-time steps is on par with more sophisticated memory-augmented neural language models.

Vector representations of words have heralded a transformational approach to classical problems in NLP; the most popular example is word2vec. However, a single vector does not suffice to model the polysemous nature of many (frequent) words, i.e., words with multiple meanings. In this paper, we propose a three-fold approach for unsupervised polysemy modeling: (a) context representations, (b) sense induction and disambiguation and (c) lexeme (as a word and sense pair) representations. A key feature of our work is the finding that a sentence containing a target word is well represented by a low-rank subspace, instead of a point in a vector space. We then show that the subspaces associated with a particular sense of the target word tend to intersect over a line (one-dimensional subspace), which we use to disambiguate senses using a clustering algorithm that harnesses the Grassmannian geometry of the representations. The disambiguation algorithm, which we call $K$-Grassmeans, leads to a procedure to label the different senses of the target word in the corpus -- yielding lexeme vector representations, all in an unsupervised manner starting from a large (Wikipedia) corpus in English. Apart from several prototypical target (word,sense) examples and a host of empirical studies to intuit and justify the various geometric representations, we validate our algorithms on standard sense induction and disambiguation datasets and present new state-of-the-art results.

Normalization techniques have only recently begun to be exploited in supervised learning tasks. Batch normalization exploits mini-batch statistics to normalize the activations. This was shown to speed up training and result in better models. However its success has been very limited when dealing with recurrent neural networks. On the other hand, layer normalization normalizes the activations across all activities within a layer. This was shown to work well in the recurrent setting. In this paper we propose a unified view of normalization techniques, as forms of divisive normalization, which includes layer and batch normalization as special cases. Our second contribution is the finding that a small modification to these normalization schemes, in conjunction with a sparse regularizer on the activations, leads to significant benefits over standard normalization techniques. We demonstrate the effectiveness of our unified divisive normalization framework in the context of convolutional neural nets and recurrent neural networks, showing improvements over baselines in image classification, language modeling as well as super-resolution.
tl;dr: We show that a linear transformation between word vector spaces should be orthogonal and can be obtained analytically using the SVD, and introduce the inverted softmax for information retrieval.

Usually bilingual word vectors are trained "online''. Mikolov et al. showed they can also be found "offline"; whereby two pre-trained embeddings are aligned with a linear transformation, using dictionaries compiled from expert knowledge. In this work, we prove that the linear transformation between two spaces should be orthogonal. This transformation can be obtained using the singular value decomposition. We introduce a novel "inverted softmax" for identifying translation pairs, with which we improve the precision @1 of Mikolov's original mapping from 34% to 43%, when translating a test set composed of both common and rare English words into Italian. Orthogonal transformations are more robust to noise, enabling us to learn the transformation without expert bilingual signal by constructing a "pseudo-dictionary" from the identical character strings which appear in both languages, achieving 40% precision on the same test set. Finally, we extend our method to retrieve the true translations of English sentences from a corpus of 200k Italian sentences with a precision @1 of 68%.

In this paper, we study the problem of question answering when reasoning over multiple facts is required. We propose Query-Reduction Network (QRN), a variant of Recurrent Neural Network (RNN) that effectively handles both short-term (local) and long-term (global) sequential dependencies to reason over multiple facts. QRN considers the context sentences as a sequence of state-changing triggers, and reduces the original query to a more informed query as it observes each trigger (context sentence) through time. Our experiments show that QRN produces the state-of-the-art results in bAbI QA and dialog tasks, and in a real goal-oriented dialog dataset. In addition, QRN formulation allows parallelization on RNN's time axis, saving an order of magnitude in time complexity for training and inference.
tl;dr: We propose a new ''density-diversity penalty'' to fully-connected layers to get significantly high sparsity and low diversity trained matrices, while keeping the performance the same.

Deep models have achieved great success on a variety of challenging tasks. How- ever, the models that achieve great performance often have an enormous number of parameters, leading to correspondingly great demands on both computational and memory resources, especially for fully-connected layers. In this work, we propose a new “density-diversity penalty” regularizer that can be applied to fully-connected layers of neural networks during training. We show that using this regularizer results in significantly fewer parameters (i.e., high sparsity), and also significantly fewer distinct values (i.e., low diversity), so that the trained weight matrices can be highly compressed without any appreciable loss in performance. The resulting trained models can hence reside on computational platforms (e.g., portables, Internet-of-Things devices) where it otherwise would be prohibitive.
tl;dr: This paper provides the first empirical demonstration that deep convolutional models really need to be both deep and convolutional, even when trained with model distillation and heavy hyperparameter optimization.

Yes, they do. This paper provides the first empirical demonstration that deep convolutional models really need to be both deep and convolutional, even when trained with methods such as distillation that allow small or shallow models of high accuracy to be trained. Although previous research showed that shallow feed-forward nets sometimes can learn the complex functions previously learned by deep nets while using the same number of parameters as the deep models they mimic, in this paper we demonstrate that the same methods cannot be used to train accurate models on CIFAR-10 unless the student models contain multiple layers of convolution. Although the student models do not have to be as deep as the teacher model they mimic, the students need multiple convolutional layers to learn functions of comparable accuracy as the deep convolutional teacher.
tl;dr: We propose to incorporate the RNN to model the generative process in Hidden Semi-Markov Model for unsupervised segmentation and labeling.

Segmentation and labeling of high dimensional time series data has wide applications in behavior understanding and medical diagnosis. Due to the difficulty in obtaining the label information for high dimensional data, realizing this objective in an unsupervised way is highly desirable. Hidden Semi-Markov Model (HSMM) is a classical tool for this problem. However, existing HSMM and its variants has simple conditional assumptions of observations, thus the ability to capture the nonlinear and complex dynamics within segments is limited. To tackle this limitation, we propose to incorporate the Recurrent Neural Network (RNN) to model the generative process in HSMM, resulting the Recurrent HSMM (R-HSMM). To accelerate the inference while preserving accuracy, we designed a structure encoding function to mimic the exact inference. By generalizing the penalty method to distribution space, we are able to train the model and the encoding function simultaneously. Empirical results show that the proposed R-HSMM achieves the state-of-the-art performances on both synthetic and real-world datasets.

Recurrent neural networks have been very successful at predicting sequences of words in tasks such as language modeling. However, all such models are based on the conventional classification framework, where the model is trained against one-hot targets, and each word is represented both as an input and as an output in isolation. This causes inefficiencies in learning both in terms of utilizing all of the information and in terms of the number of parameters needed to train. We introduce a novel theoretical framework that facilitates better learning in language modeling, and show that our framework leads to tying together the input embedding and the output projection matrices, greatly reducing the number of trainable variables. Our framework leads to state of the art performance on the Penn Treebank with a variety of network models.

Deep neural network models, though very powerful and highly successful, are computationally expensive in terms of space and time. Recently, there have been a number of attempts on binarizing the network weights and activations. This greatly reduces the network size, and replaces the underlying multiplications to additions or even XNOR bit operations. However, existing binarization schemes are based on simple matrix approximations and ignore the effect of binarization on the loss. In this paper, we propose a proximal Newton algorithm with diagonal Hessian approximation that directly minimizes the loss w.r.t. the binarized weights. The underlying proximal step has an efficient closed-form solution, and the second-order information can be efficiently obtained from the second moments already computed by the Adam optimizer. Experiments on both feedforward and recurrent networks show that the proposed loss-aware binarization algorithm outperforms existing binarization schemes, and is also more robust for wide and deep networks.

We study reinforcement learning of chat-bots with recurrent neural network
architectures when the rewards are noisy and expensive to
obtain. For instance, a chat-bot used in automated customer service support can
be scored by quality assurance agents, but this process can be expensive, time consuming
and noisy.
Previous reinforcement learning work for natural language uses on-policy updates
and/or is designed for on-line learning settings.
We demonstrate empirically that such strategies are not appropriate for this setting
and develop an off-policy batch policy gradient method (\bpg).
We demonstrate the efficacy of our method via a series of
synthetic experiments and an Amazon Mechanical Turk experiment on
a restaurant recommendations dataset.
tl;dr: Semi-supervised classification with a CNN model for graphs. State-of-the-art results on a number of citation network datasets.

We present a scalable approach for semi-supervised learning on graph-structured data that is based on an efficient variant of convolutional neural networks which operate directly on graphs. We motivate the choice of our convolutional architecture via a localized first-order approximation of spectral graph convolutions. Our model scales linearly in the number of graph edges and learns hidden layer representations that encode both local graph structure and features of nodes. In a number of experiments on citation networks and on a knowledge graph dataset we demonstrate that our approach outperforms related methods by a significant margin.
tl;dr: We present a general probabilistic method based on Bayesian neural networks to predit learning curves of iterative machine learning methods.

Different neural network architectures, hyperparameters and training protocols lead to different performances as a function of time.
Human experts routinely inspect the resulting learning curves to quickly terminate runs with poor hyperparameter settings and thereby considerably speed up manual hyperparameter optimization. Exploiting the same information in automatic Bayesian hyperparameter optimization requires a probabilistic model of learning curves across hyperparameter settings. Here, we study the use of Bayesian neural networks for this purpose and improve their performance by a specialized learning curve layer.
tl;dr: Applying recurrent neural networks to fix errors and omissions in patient medication records.

It is a surprising fact that electronic medical records are failing at one of their primary purposes, that of tracking the set of medications that the patient is actively taking. Studies estimate that up to 50% of such lists omit active drugs, and that up to 25% of all active medications do not appear on the appropriate patient list. Manual efforts to maintain these lists involve a great deal of tedious human labor, which could be reduced by computational tools to suggest likely missing or incorrect medications on a patient’s list. We report here an application of recurrent neural networks to predict the likely therapeutic classes of medications that a patient is taking, given a sequence of the last 100 billing codes in their record. Our best model was a GRU that achieved high prediction accuracy (micro-averaged AUC 0.93, Label Ranking Loss 0.076), limited by hardware constraints on model size. Additionally, examining individual cases revealed that many of the predictions marked incorrect were likely to be examples of either omitted medications or omitted billing codes, supporting our assertion of a substantial number of errors and omissions in the data, and the likelihood of models such as these to help correct them.
tl;dr: We propose a simple warm restart technique for stochastic gradient descent to improve its anytime performance.

Restart techniques are common in gradient-free optimization to deal with multimodal functions. Partial warm restarts are also gaining popularity in gradient-based optimization to improve the rate of convergence in accelerated gradient schemes to deal with ill-conditioned functions. In this paper, we propose a simple warm restart technique for stochastic gradient descent to improve its anytime performance when training deep neural networks. We empirically study its performance on the CIFAR-10 and CIFAR-100 datasets,
where we demonstrate new state-of-the-art results at 3.14\% and 16.21\%, respectively. We also demonstrate its advantages on a dataset of EEG recordings and on a downsampled version of the ImageNet dataset. Our source code is available at \\ \url{https://github.com/loshchil/SGDR}

We propose a statistical model applicable to character level language modeling and show that it is a good fit for both, program source code and English text. The model is parameterized by a program from a domain-specific language (DSL) that allows expressing non-trivial data dependencies. Learning is done in two phases: (i) we synthesize a program from the DSL, essentially learning a good representation for the data, and (ii) we learn parameters from the training data - the process is done via counting, as in simple language models such as n-gram.
Our experiments show that the precision of our model is comparable to that of neural networks while sharing a number of advantages with n-gram models such as fast query time and the capability to quickly add and remove training data samples. Further, the model is parameterized by a program that can be manually inspected, understood and updated, addressing a major problem of neural networks.

Code super-optimization is the task of transforming any given program to a more efficient version while preserving its input-output behaviour. In some sense, it is similar to the paraphrase problem from natural language processing where the intention is to change the syntax of an utterance without changing its semantics. Code-optimization has been the subject of years of research that has resulted in the development of rule-based transformation strategies that are used by compilers. More recently, however, a class of stochastic search based methods have been shown to outperform these strategies. This approach involves repeated sampling of modifications to the program from a proposal distribution, which are accepted or rejected based on whether they preserve correctness, and the improvement they achieve. These methods, however, neither learn from past behaviour nor do they try to leverage the semantics of the program under consideration. Motivated by this observation, we present a novel learning based approach for code super-optimization. Intuitively, our method works by learning the proposal distribution using unbiased estimators of the gradient of the expected improvement. Experiments on benchmarks comprising of automatically generated as well as existing (``Hacker's Delight'') programs show that the proposed method is able to significantly outperform state of the art approaches for code super-optimization.

The past year saw the introduction of new architectures such as Highway networks and Residual networks which, for the first time, enabled the training of feedforward networks with dozens to hundreds of layers using simple gradient descent.
While depth of representation has been posited as a primary reason for their success, there are indications that these architectures defy a popular view of deep learning as a hierarchical computation of increasingly abstract features at each layer.
In this report, we argue that this view is incomplete and does not adequately explain several recent findings.
We propose an alternative viewpoint based on unrolled iterative estimation---a group of successive layers iteratively refine their estimates of the same features instead of computing an entirely new representation.
We demonstrate that this viewpoint directly leads to the construction of highway and residual networks.
Finally we provide preliminary experiments to discuss the similarities and differences between the two architectures.
tl;dr: We train agents to conduct experiments in interactive simulated physical environments.

When encountering novel objects, humans are able to infer a wide range of physical properties such as mass, friction and deformability by interacting with them in a goal driven way. This process of active interaction is in the same spirit as a scientist performing experiments to discover hidden facts. Recent advances in artificial intelligence have yielded machines that can achieve superhuman performance in Go, Atari, natural language processing, and complex control problems; however, it is not clear that these systems can rival the scientific intuition of even a young child. In this work we introduce a basic set of tasks that require agents to estimate properties such as mass and cohesion of objects in an interactive simulated environment where they can manipulate the objects and observe the consequences. We found that deep reinforcement learning methods can learn to perform the experiments necessary to discover such hidden properties. By systematically manipulating the problem difficulty and the cost incurred by the agent for performing experiments, we found that agents learn different strategies that balance the cost of gathering information against the cost of making mistakes in different situations. We also compare our learned experimentation policies to randomized baselines and show that the learned policies lead to better predictions.
tl;dr: We generalize Turing machines to the continuous setting using Lie group actions on manifolds.

External neural memory structures have recently become a popular tool for
algorithmic deep learning
(Graves et al. 2014; Weston et al. 2014). These models
generally utilize differentiable versions of traditional discrete
memory-access structures (random access, stacks, tapes) to provide
the storage necessary for computational tasks. In
this work, we argue that these neural memory systems lack specific
structure important for relative indexing, and propose an
alternative model, Lie-access memory, that is explicitly designed
for the neural setting. In this paradigm, memory is accessed using
a continuous head in a key-space manifold. The head is moved via Lie
group actions, such as shifts or rotations, generated by a
controller, and memory access is performed by linear smoothing in
key space. We argue that Lie groups provide a natural generalization
of discrete memory structures, such as Turing machines, as they
provide inverse and identity operators while maintaining
differentiability. To experiment with this approach, we implement
a simplified Lie-access neural Turing machine (LANTM) with
different Lie groups. We find that this approach is able to perform
well on a range of algorithmic tasks.

The success of CNNs in various applications is accompanied by a significant increase in the computation and parameter storage costs. Recent efforts toward reducing these overheads involve pruning and compressing the weights of various layers without hurting original accuracy. However, magnitude-based pruning of weights reduces a significant number of parameters from the fully connected layers and may not adequately reduce the computation costs in the convolutional layers due to irregular sparsity in the pruned networks. We present an acceleration method for CNNs, where we prune filters from CNNs that are identified as having a small effect on the output accuracy. By removing whole filters in the network together with their connecting feature maps, the computation costs are reduced significantly. In contrast to pruning weights, this approach does not result in sparse connectivity patterns. Hence, it does not need the support of sparse convolution libraries and can work with existing efficient BLAS libraries for dense matrix multiplications. We show that even simple filter pruning techniques can reduce inference costs for VGG-16 by up to 34% and ResNet-110 by up to 38% on CIFAR10 while regaining close to the original accuracy by retraining the networks.

We propose an approximate strategy to efficiently train neural network based language models over very large vocabularies. Our approach, called adaptive softmax, circumvents the linear dependency on the vocabulary size by exploiting the unbalanced word distribution to form clusters that explicitly minimize the expectation of computational complexity. Our approach further reduces the computational cost by exploiting the specificities of modern architectures and matrix-matrix vector operations, making it particularly suited for graphical processing units. Our experiments carried out on standard benchmarks, such as EuroParl and One Billion Word, show that our approach brings a large gain in efficiency over standard approximations while achieving an accuracy close to that of the full softmax.
tl;dr: We present a novel information-theoretic framework for fast and robust unsupervised Learning via information maximization for neural population coding.

A framework is presented for unsupervised learning of representations based on infomax principle for large-scale neural populations. We use an asymptotic approximation to the Shannon's mutual information for a large neural population to demonstrate that a good initial approximation to the global information-theoretic optimum can be obtained by a hierarchical infomax method. Starting from the initial solution, an efficient algorithm based on gradient descent of the final objective function is proposed to learn representations from the input datasets, and the method works for complete, overcomplete, and undercomplete bases. As confirmed by numerical experiments, our method is robust and highly efficient for extracting salient features from input datasets. Compared with the main existing methods, our algorithm has a distinct advantage in both the training speed and the robustness of unsupervised representation learning. Furthermore, the proposed method is easily extended to the supervised or unsupervised model for training deep structure networks.
tl;dr: A simple approach to train autoencoders to compress images as well or better than JPEG 2000.

We propose a new approach to the problem of optimizing autoencoders for lossy image compression. New media formats, changing hardware technology, as well as diverse requirements and content types create a need for compression algorithms which are more flexible than existing codecs. Autoencoders have the potential to address this need, but are difficult to optimize directly due to the inherent non-differentiabilty of the compression loss. We here show that minimal changes to the loss are sufficient to train deep autoencoders competitive with JPEG 2000 and outperforming recently proposed approaches based on RNNs. Our network is furthermore computationally efficient thanks to a sub-pixel architecture, which makes it suitable for high-resolution images. This is in contrast to previous work on autoencoders for compression using coarser approximations, shallower architectures, computationally expensive methods, or focusing on small images.
tl;dr: A multi-task representation learning framework that learns cross-task sharing structure at every layer in a deep network.

Most contemporary multi-task learning methods assume linear models. This setting is considered shallow in the era of deep learning. In this paper, we present a new deep multi-task representation learning framework that learns cross-task sharing structure at every layer in a deep network. Our approach is based on generalising the matrix factorisation techniques explicitly or implicitly used by many conventional MTL algorithms to tensor factorisation, to realise automatic learning of end-to-end knowledge sharing in deep networks. This is in contrast to existing deep learning approaches that need a user-defined multi-task sharing strategy. Our approach applies to both homogeneous and heterogeneous MTL. Experiments demonstrate the efficacy of our deep multi-task representation learning in terms of both higher accuracy and fewer design choices.

The capacity of a neural network to absorb information is limited by its number of parameters. Conditional computation, where parts of the network are active on a per-example basis, has been proposed in theory as a way of dramatically increasing model capacity without a proportional increase in computation. In practice, however, there are significant algorithmic and performance challenges. In this work, we address these challenges and finally realize the promise of conditional computation, achieving greater than 1000x improvements in model capacity with only minor losses in computational efficiency on modern GPU clusters. We introduce a Sparsely-Gated Mixture-of-Experts layer (MoE), consisting of up to thousands of feed-forward sub-networks. A trainable gating network determines a sparse combination of these experts to use for each example. We apply the MoE to the tasks of language modeling and machine translation, where model capacity is critical for absorbing the vast quantities of knowledge available in the training corpora. We present model architectures in which a MoE with up to 137 billion parameters is applied convolutionally between stacked LSTM layers. On large language modeling and machine translation benchmarks, these models achieve significantly better results than state-of-the-art at lower computational cost.
tl;dr: VAE with an autoregressive PixelCNN-based decoder with strong performance on binarized MNIST, ImageNet 64x64, and LSUN bedrooms.

Natural image modeling is a landmark challenge of unsupervised learning. Variational Autoencoders (VAEs) learn a useful latent representation and model global structure well but have difficulty capturing small details. PixelCNN models details very well, but lacks a latent code and is difficult to scale for capturing large structures. We present PixelVAE, a VAE model with an autoregressive decoder based on PixelCNN. Our model requires very few expensive autoregressive layers compared to PixelCNN and learns latent codes that are more compressed than a standard VAE while still capturing most non-trivial structure. Finally, we extend our model to a hierarchy of latent variables at different scales. Our model achieves state-of-the-art performance on binarized MNIST, competitive performance on 64 × 64 ImageNet, and high-quality samples on the LSUN bedrooms dataset.
116. Towards Deep Interpretability (MUS-ROVER II): Learning Hierarchical Representations of Tonal Music

Music theory studies the regularity of patterns in music to capture concepts underlying music styles and composers' decisions. This paper continues the study of building \emph{automatic theorists} (rovers) to learn and represent music concepts that lead to human interpretable knowledge and further lead to materials for educating people. Our previous work took a first step in algorithmic concept learning of tonal music, studying high-level representations (concepts) of symbolic music (scores) and extracting interpretable rules for composition. This paper further studies the representation \emph{hierarchy} through the learning process, and supports \emph{adaptive} 2D memory selection in the resulting language model. This leads to a deeper-level interpretability that expands from individual rules to a dynamic system of rules, making the entire rule learning process more cognitive. The outcome is a new rover, MUS-ROVER \RN{2}, trained on Bach's chorales, which outputs customizable syllabi for learning compositional rules. We demonstrate comparable results to our music pedagogy, while also presenting the differences and variations. In addition, we point out the rover's potential usages in style recognition and synthesis, as well as applications beyond music.
tl;dr: Adding discretized logistic mixture Likelihood and other modifications to PixelCNN improves performance.

PixelCNNs are a recently proposed class of powerful generative models with tractable likelihood. Here we discuss our implementation of PixelCNNs which we make available at https://github.com/openai/pixel-cnn. Our implementation contains a number of modifications to the original model that both simplify its structure and improve its performance. 1) We use a discretized logistic mixture likelihood on the pixels, rather than a 256-way softmax, which we find to speed up training. 2) We condition on whole pixels, rather than R/G/B sub-pixels, simplifying the model structure. 3) We use downsampling to efficiently capture structure at multiple resolutions. 4) We introduce additional short-cut connections to further speed up optimization. 5) We regularize the model using dropout. Finally, we present state-of-the-art log likelihood results on CIFAR-10 to demonstrate the usefulness of these modifications.
tl;dr: Efficient biconvex learning of binary autoencoders, using pairwise correlations between encodings and decodings, is strongly optimal.

We formulate learning of a binary autoencoder as a biconvex optimization problem which learns from the pairwise correlations between encoded and decoded bits. Among all possible algorithms that use this information, ours finds the autoencoder that reconstructs its inputs with worst-case optimal loss. The optimal decoder is a single layer of artificial neurons, emerging entirely from the minimax loss minimization, and with weights learned by convex optimization. All this is reflected in competitive experimental results, demonstrating that binary autoencoding can be done efficiently by conveying information in pairwise correlations in an optimal fashion.
tl;dr: We study the ability of convolutional networks to model correlations among regions of their input, showing that this is controlled by shapes of pooling windows.

Our formal understanding of the inductive bias that drives the success of convolutional networks on computer vision tasks is limited. In particular, it is unclear what makes hypotheses spaces born from convolution and pooling operations so suitable for natural images. In this paper we study the ability of convolutional networks to model correlations among regions of their input. We theoretically analyze convolutional arithmetic circuits, and empirically validate our findings on other types of convolutional networks as well. Correlations are formalized through the notion of separation rank, which for a given partition of the input, measures how far a function is from being separable. We show that a polynomially sized deep network supports exponentially high separation ranks for certain input partitions, while being limited to polynomial separation ranks for others. The network's pooling geometry effectively determines which input partitions are favored, thus serves as a means for controlling the inductive bias. Contiguous pooling windows as commonly employed in practice favor interleaved partitions over coarse ones, orienting the inductive bias towards the statistics of natural images. Other pooling schemes lead to different preferences, and this allows tailoring the network to data that departs from the usual domain of natural imagery. In addition to analyzing deep networks, we show that shallow ones support only linear separation ranks, and by this gain insight into the benefit of functions brought forth by depth - they are able to efficiently model strong correlation under favored partitions of the input.

Convolutional neural networks (CNNs) are powerful tools for classification of visual inputs. An important property of CNN is its restriction to local connections and sharing of local weights among different locations. In this paper, we consider the definition of appropriate local neighborhoods in CNN. We provide a theoretical analysis that justifies the traditional square filter used in CNN for analyzing natural images. The analysis also provides a principle for designing customized filter shapes for application domains that do not resemble natural images. We propose an approach that automatically designs multiple layers of different customized filter shapes by repeatedly solving lasso problems. It is applied to customize the filter shape for both bioacoustic applications and gene sequence analysis applications. In those domains with small sample sizes we demonstrate that the customized filters achieve superior classification accuracy, improved convergence behavior in training and reduced sensitivity to hyperparameters.
tl;dr: QRNNs, composed of convolutions and a recurrent pooling function, outperform LSTMs on a variety of sequence tasks and are up to 16 times faster.

Recurrent neural networks are a powerful tool for modeling sequential data, but the dependence of each timestep’s computation on the previous timestep’s output limits parallelism and makes RNNs unwieldy for very long sequences. We introduce quasi-recurrent neural networks (QRNNs), an approach to neural sequence modeling that alternates convolutional layers, which apply in parallel across timesteps, and a minimalist recurrent pooling function that applies in parallel across channels. Despite lacking trainable recurrent layers, stacked QRNNs have better predictive accuracy than stacked LSTMs of the same hidden size. Due to their increased parallelism, they are up to 16 times faster at train and test time. Experiments on language modeling, sentiment classification, and character-level neural machine translation demonstrate these advantages and underline the viability of QRNNs as a basic building block for a variety of sequence tasks.
tl;dr: We define a variational autoencoder variant with stick-breaking latent variables thereby giving it adaptive width.

We extend Stochastic Gradient Variational Bayes to perform posterior inference for the weights of Stick-Breaking processes. This development allows us to define a Stick-Breaking Variational Autoencoder (SB-VAE), a Bayesian nonparametric version of the variational autoencoder that has a latent representation with stochastic dimensionality. We experimentally demonstrate that the SB-VAE, and a semi-supervised variant, learn highly discriminative latent representations that often outperform the Gaussian VAE’s.

Previous work combines word-level and character-level representations using concatenation or scalar weighting, which is suboptimal for high-level tasks like reading comprehension. We present a fine-grained gating mechanism to dynamically combine word-level and character-level representations based on properties of the words. We also extend the idea of fine-grained gating to modeling the interaction between questions and paragraphs for reading comprehension. Experiments show that our approach can improve the performance on reading comprehension tasks, achieving new state-of-the-art results on the Children's Book Test and Who Did What datasets. To demonstrate the generality of our gating mechanism, we also show improved results on a social media tag prediction task.

Recent papers have shown that neural networks obtain state-of-the-art performance on several different sequence tagging tasks. One appealing property of such systems is their generality, as excellent performance can be achieved with a unified architecture and without task-specific feature engineering. However, it is unclear if such systems can be used for tasks without large amounts of training data. In this paper we explore the problem of transfer learning for neural sequence taggers, where a source task with plentiful annotations (e.g., POS tagging on Penn Treebank) is used to improve performance on a target task with fewer available annotations (e.g., POS tagging for microblogs). We examine the effects of transfer learning for deep hierarchical recurrent networks across domains, applications, and languages, and show that significant improvement can often be obtained. These improvements lead to improvements over the current state-of-the-art on several well-studied tasks.
tl;dr: A VAE that provably learns global structure of images with a local PixelCNN decoder.

Representation learning seeks to expose certain aspects of observed data in a learned representation that's amenable to downstream tasks like classification.
For instance, a good representation for 2D images might be one that describes only global structure and discards information about detailed texture.
In this paper, we present a simple but principled method to learn such global representations by combining Variational Autoencoder (VAE) with neural autoregressive models such as RNN, MADE and PixelRNN/CNN.
Our proposed VAE model allows us to have control over what the global latent code can learn and , by designing the architecture accordingly, we can force the global latent code to discard irrelevant information such as texture in 2D images, and hence the code only ``autoencodes'' data in a lossy fashion.
In addition, by leveraging autoregressive models as both prior distribution $p(z)$ and decoding distribution $p(x|z)$, we can greatly improve generative modeling performance of VAEs, achieving new state-of-the-art results on MNIST, OMNIGLOT and Caltech-101 as well as competitive results on CIFAR10.
126. Learning to Optimize
tl;dr: We explore learning an optimization algorithm automatically.

Algorithm design is a laborious process and often requires many iterations of ideation and validation. In this paper, we explore automating algorithm design and present a method to learn an optimization algorithm. We approach this problem from a reinforcement learning perspective and represent any particular optimization algorithm as a policy. We learn an optimization algorithm using guided policy search and demonstrate that the resulting algorithm outperforms existing hand-engineered algorithms in terms of convergence speed and/or the final objective value.

We propose a framework for detecting action patterns from motion sequences and modeling the sensory-motor relationship of animals, using a generative recurrent neural network. The network has a discriminative part (classifying actions) and a generative part (predicting motion), whose recurrent cells are laterally connected, allowing higher levels of the network to represent high level behavioral phenomena. We test our framework on two types of tracking data, fruit fly behavior and online handwriting. Our results show that 1) taking advantage of unlabeled sequences, by predicting future motion, significantly improves action detection performance when training labels are scarce, 2) the network learns to represent high level phenomena such as writer identity and fly gender, without supervision, and 3) simulated motion trajectories, generated by treating motion prediction as input to the network, look realistic and may be used to qualitatively evaluate whether the model has learnt generative control rules.

We propose Edward, a Turing-complete probabilistic programming language. Edward defines two compositional representations—random variables and inference. By treating inference as a first class citizen, on a par with modeling, we show that probabilistic programming can be as flexible and computationally efficient as traditional deep learning. For flexibility, Edward makes it easy to fit the same model using a variety of composable inference methods, ranging from point estimation to variational inference to MCMC. In addition, Edward can reuse the modeling representation as part of inference, facilitating the design of rich variational models and generative adversarial networks. For efficiency, Edward is integrated into TensorFlow, providing significant speedups over existing probabilistic systems. For example, we show on a benchmark logistic regression task that Edward is at least 35x faster than Stan and 6x faster than PyMC3. Further, Edward incurs no runtime overhead: it is as fast as handwritten TensorFlow.
tl;dr: Derive data noising schemes for neural network language models corresponding to techniques in n-gram smoothing.

Data noising is an effective technique for regularizing neural network models. While noising is widely adopted in application domains such as vision and speech, commonly used noising primitives have not been developed for discrete sequence-level settings such as language modeling. In this paper, we derive a connection between input noising in neural network language models and smoothing in n-gram models. Using this connection, we draw upon ideas from smoothing to develop effective noising schemes. We demonstrate performance gains when applying the proposed schemes to language modeling and machine translation. Finally, we provide empirical analysis validating the relationship between noising and smoothing.
tl;dr: We propose to use Annealed Importance Sampling to evaluate decoder-based generative network, and investigate various properties of these models.

The past several years have seen remarkable progress in generative models which produce convincing samples of images and other modalities. A shared component of some popular models such as generative adversarial networks and generative moment matching networks, is a decoder network, a parametric deep neural net that defines a generative distribution. Unfortunately, it can be difficult to quantify the performance of these models because of the intractability of log-likelihood estimation, and inspecting samples can be misleading. We propose to use Annealed Importance Sampling for evaluating log-likelihoods for decoder-based models and validate its accuracy using bidirectional Monte Carlo. Using this technique, we analyze the performance of decoder-based models, the effectiveness of existing log-likelihood estimators, the degree of overfitting, and the degree to which these models miss important modes of the data distribution.
tl;dr: GANs with multiple discriminators accelerate training to more robust performance.

Generative adversarial networks (GANs) are a framework for producing a generative model by way of a two-player minimax game. In this paper, we propose the \emph{Generative Multi-Adversarial Network} (GMAN), a framework that extends GANs to multiple discriminators. In previous work, the successful training of GANs requires modifying the minimax objective to accelerate training early on. In contrast, GMAN can be reliably trained with the original, untampered objective. We explore a number of design perspectives with the discriminator role ranging from formidable adversary to forgiving teacher. Image generation tasks comparing the proposed framework to standard GANs demonstrate GMAN produces higher quality samples in a fraction of the iterations when measured by a pairwise GAM-type metric.

We study the problem of transferring a sample in one domain to an analog sample in another domain. Given two related domains, S and T, we would like to learn a generative function G that maps an input sample from S to the domain T, such that the output of a given representation function f, which accepts inputs in either domains, would remain unchanged. Other than f, the training data is unsupervised and consist of a set of samples from each domain, without any mapping between them. The Domain Transfer Network (DTN) we present employs a compound loss function that includes a multiclass GAN loss, an f preserving component, and a regularizing component that encourages G to map samples from T to themselves. We apply our method to visual domains including digits and face images and demonstrate its ability to generate convincing novel images of previously unseen entities, while preserving their identity.
tl;dr: We formulate sequence to sequence transduction as a noisy channel decoding problem and use recurrent neural networks to parameterise the source and channel models.

We formulate sequence to sequence transduction as a noisy channel decoding problem and use recurrent neural networks to parameterise the source and channel models. Unlike direct models which can suffer from explaining-away effects during training, noisy channel models must produce outputs that explain their inputs, and their component models can be trained with not only paired training samples but also unpaired samples from the marginal output distribution. Using a latent variable to control how much of the conditioning sequence the channel model needs to read in order to generate a subsequent symbol, we obtain a tractable and effective beam search decoder. Experimental results on abstractive sentence summarisation, morphological inflection, and machine translation show that noisy channel models outperform direct models, and that they significantly benefit from increased amounts of unpaired output data that direct models cannot easily use.
tl;dr: A new state-of-the-art on the VQA (real image) dataset using an attention mechanism of low-rank bilinear pooling

Bilinear models provide rich representations compared with linear models. They have been applied in various visual tasks, such as object recognition, segmentation, and visual question-answering, to get state-of-the-art performances taking advantage of the expanded representations. However, bilinear representations tend to be high-dimensional, limiting the applicability to computationally complex tasks. We propose low-rank bilinear pooling using Hadamard product for an efficient attention mechanism of multimodal learning. We show that our model outperforms compact bilinear pooling in visual question-answering tasks with the state-of-the-art results on the VQA dataset, having a better parsimonious property.
tl;dr: Use a denoiser trained on discriminator features to train better generators.

We propose an augmented training procedure for generative adversarial networks designed to address shortcomings of the original by directing the generator towards probable configurations of abstract discriminator features. We estimate and track the distribution of these features, as computed from data, with a denoising auto-encoder, and use it to propose high-level targets for the generator. We combine this new loss with the original and evaluate the hybrid criterion on the task of unsupervised image synthesis from datasets comprising a diverse set of visual categories, noting a qualitative and quantitative improvement in the ``objectness'' of the resulting samples.
tl;dr: Adapting Actor-Critic methods from reinforcement learning to structured prediction

We present an approach to training neural networks to generate sequences using actor-critic methods from reinforcement learning (RL). Current log-likelihood training methods are limited by the discrepancy between their training and testing modes, as models must generate tokens conditioned on their previous guesses rather than the ground-truth tokens. We address this problem by introducing a textit{critic} network that is trained to predict the value of an output token, given the policy of an textit{actor} network. This results in a training procedure that is much closer to the test phase, and allows us to directly optimize for a task-specific score such as BLEU. Crucially, since we leverage these techniques in the supervised learning setting rather than the traditional RL setting, we condition the critic network on the ground-truth output. We show that our method leads to improved performance on both a synthetic task, and for German-English machine translation. Our analysis paves the way for such methods to be applied in natural language generation tasks, such as machine translation, caption generation, and dialogue modelling.

We propose a deep neural network for the prediction of future frames in natural video sequences. To effectively handle complex evolution of pixels in videos, we propose to decompose the motion and content, two key components generating dynamics in videos. Our model is built upon the Encoder-Decoder Convolutional Neural Network and Convolutional LSTM for pixel-level prediction, which independently capture the spatial layout of an image and the corresponding temporal dynamics. By independently modeling motion and content, predicting the next frame reduces to converting the extracted content features into the next frame content by the identified motion features, which simplifies the task of prediction. Our model is end-to-end trainable over multiple time steps, and naturally learns to decompose motion and content without separate training. We evaluate the pro- posed network architecture on human activity videos using KTH, Weizmann action, and UCF-101 datasets. We show state-of-the-art performance in comparison to recent approaches. To the best of our knowledge, this is the first end-to-end trainable network architecture with motion and content separation to model the spatio-temporal dynamics for pixel-level future prediction in natural videos.

Hypothesis testing is an important cognitive process that supports human reasoning. In this paper, we introduce a computational hypothesis testing approach based on memory augmented neural networks. Our approach involves a hypothesis testing loop that reconsiders and progressively refines a previously formed hypothesis in order to generate new hypotheses to test. We apply the proposed approach to language comprehension task by using Neural Semantic Encoders (NSE). Our NSE models achieve the state-of-the-art results showing an absolute improvement of 1.2% to 2.6% accuracy over previous results obtained by single and ensemble systems on standard machine comprehension benchmarks such as the Children's Book Test (CBT) and Who-Did-What (WDW) news article datasets.
tl;dr: Implementation and analysis of the computational aspect of a GPU version of the Asynchronous Advantage Actor-Critic (A3C) algorithm

We introduce a hybrid CPU/GPU version of the Asynchronous Advantage Actor-Critic (A3C) algorithm, currently the state-of-the-art method in reinforcement learning for various gaming tasks. We analyze its computational traits and concentrate on aspects critical to leveraging the GPU's computational power. We introduce a system of queues and a dynamic scheduling strategy, potentially helpful for other asynchronous algorithms as well. Our hybrid CPU/GPU version of A3C, based on TensorFlow, achieves a significant speed up compared to a CPU implementation; we make it publicly available to other researchers at https://github.com/NVlabs/GA3C.

We present an algorithm for policy search in stochastic dynamical systems using
model-based reinforcement learning. The system dynamics are described with
Bayesian neural networks (BNNs) that include stochastic input variables. These
input variables allow us to capture complex statistical
patterns in the transition dynamics (e.g. multi-modality and
heteroskedasticity), which are usually missed by alternative modeling approaches. After
learning the dynamics, our BNNs are then fed into an algorithm that performs
random roll-outs and uses stochastic optimization for policy learning. We train
our BNNs by minimizing $\alpha$-divergences with $\alpha = 0.5$, which usually produces better
results than other techniques such as variational Bayes. We illustrate the performance of our method by
solving a challenging problem where model-based approaches usually fail and by
obtaining promising results in real-world scenarios including the control of a
gas turbine and an industrial benchmark.
tl;dr: A new dataset QRAQ of ambiguous stories in which an Agent must learn to reason and interact with a User to obtain important missing information needed to answer a challenge question.

A key goal of research in conversational systems is to train an interactive agent to help a user with a task. Human conversation, however, is notoriously incomplete, ambiguous, and full of extraneous detail. To operate effectively, the agent must not only understand what was explicitly conveyed but also be able to reason in the presence of missing or unclear information. When unable to resolve ambiguities on its own, the agent must be able to ask the user for the necessary clarifications and incorporate the response in its reasoning. Motivated by this problem we introduce QRAQ ("crack"; Query, Reason, and Answer Questions), a new synthetic domain, in which a User gives an Agent a short story and asks a challenge question. These problems are designed to test the reasoning and interaction capabilities of a learning-based Agent in a setting that requires multiple conversational turns. A good Agent should ask only non-deducible, relevant questions until it has enough information to correctly answer the User's question. We use standard and improved reinforcement learning based memory-network architectures to solve QRAQ problems in the difficult setting where the reward signal only tells the Agent if its final answer to the challenge question is correct or not. To provide an upper-bound to the RL results we also train the same architectures using supervised information that tells the Agent during training which variables to query and the answer to the challenge question. We evaluate our architectures on four QRAQ dataset types, and scale the complexity for each along multiple dimensions.
tl;dr: a simple document representation learning framework that is very efficient to train and test

We present an efficient document representation learning framework, Document Vector through Corruption (Doc2VecC). Doc2VecC represents each document as a simple average of word embeddings. It ensures a representation generated as such captures the semantic meanings of the document during learning. A corruption model is included, which introduces a data-dependent regularization that favors informative or rare words while forcing the embeddings of common and non-discriminative ones to be close to zero. Doc2VecC produces significantly better word embeddings than Word2Vec. We compare Doc2VecC with several state-of-the-art document representation learning algorithms. The simple model architecture introduced by Doc2VecC matches or out-performs the state-of-the-art in generating high-quality document representations for sentiment analysis, document classification as well as semantic relatedness tasks. The simplicity of the model enables training on billions of words per hour on a single machine. At the same time, the model is very efficient in generating representations of unseen documents at test time.
tl;dr: A neural architecture for learning programs in a domain-specific language that are consistent with a given set of input-output examples

Recent years have seen the proposal of a number of neural architectures for the problem of Program Induction. Given a set of input-output examples, these architectures are able to learn mappings that generalize to new test inputs. While achieving impressive results, these approaches have a number of important limitations: (a) they are computationally expensive and hard to train, (b) a model has to be trained for each task (program) separately, and (c) it is hard to interpret or verify the correctness of the learnt mapping (as it is defined by a neural network). In this paper, we propose a novel technique, Neuro-Symbolic Program Synthesis, to overcome the above-mentioned problems. Once trained, our approach can automatically construct computer programs in a domain-specific language that are consistent with a set of input-output examples provided at test time. Our method is based on two novel neural modules. The first module, called the cross correlation I/O network, given a set of input-output examples, produces a continuous representation of the set of I/O examples. The second module, the Recursive-Reverse-Recursive Neural Network (R3NN), given the continuous representation of the examples, synthesizes a program by incrementally expanding partial programs. We demonstrate the effectiveness of our approach by applying it to the rich and complex domain of regular expression based string transformations. Experiments show that the R3NN model is not only able to construct programs from new input-output examples, but it is also able to construct new programs for tasks that it had never observed before during training.

Adversarial training provides a means of regularizing supervised learning algorithms while virtual adversarial training is able to extend supervised learning algorithms to the semi-supervised setting.
However, both methods require making small perturbations to numerous entries of the input vector, which is inappropriate for sparse high-dimensional inputs such as one-hot word representations.
We extend adversarial and virtual adversarial training to the text domain by applying perturbations to the word embeddings in a recurrent neural network rather than to the original input itself.
The proposed method achieves state of the art results on multiple benchmark semi-supervised and purely supervised tasks.
We provide visualizations and analysis showing that the learned word embeddings have improved in quality and that while training, the model is less prone to overfitting.
tl;dr: We present Support Regularized Sparse Coding (SRSC) to improve the regular sparse coding, and propose a feed-forward neural network termed Deep Support Regularized Sparse Coding (Deep-SRSC) as its fast encoder.

Sparse coding represents a signal by a linear combination of only a few atoms of a learned over-complete dictionary. While sparse coding exhibits compelling performance for various machine learning tasks, the process of obtaining sparse code with fixed dictionary is independent for each data point without considering the geometric information and manifold structure of the entire data. We propose Support Regularized Sparse Coding (SRSC) which produces sparse codes that account for the manifold structure of the data by encouraging nearby data in the manifold to choose similar dictionary atoms. In this way, the obtained support regularized sparse codes capture the locally linear structure of the data manifold and enjoy robustness to data noise. We present the optimization algorithm of SRSC with theoretical guarantee for the optimization over the sparse codes. We also propose a feed-forward neural network termed Deep Support Regularized Sparse Coding (Deep-SRSC) as a fast encoder to approximate the sparse codes generated by SRSC. Extensive experimental results demonstrate the effectiveness of SRSC and Deep-SRSC.

Models that can simulate how environments change in response to actions can be used by agents to plan and act efficiently. We improve on previous environment simulators from high-dimensional pixel observations by introducing recurrent neural networks that are able to make temporally and spatially coherent predictions for hundreds of time-steps into the future. We present an in-depth analysis of the factors affecting performance, providing the most extensive attempt to advance the understanding of the properties of these models. We address the issue of computationally inefficiency with a model that does not need to generate a high-dimensional image at each time-step. We show that our approach can be used to improve exploration and is adaptable to many diverse environments, namely 10 Atari games, a 3D car racing environment, and complex 3D mazes.
tl;dr: We introduce a new large-scale music dataset, define a multi-label classification task, and benchmark machine learning architectures on this task.

This paper introduces a new large-scale music dataset, MusicNet, to serve as a source
of supervision and evaluation of machine learning methods for music research.
MusicNet consists of hundreds of freely-licensed classical music recordings
by 10 composers, written for 11 instruments, together with instrument/note
annotations resulting in over 1 million temporal labels on 34 hours of chamber music
performances under various studio and microphone conditions.
The paper defines a multi-label classification task to predict notes in musical recordings,
along with an evaluation protocol, and benchmarks several machine learning architectures for this task:
i) learning from spectrogram features;
ii) end-to-end learning with a neural net;
iii) end-to-end learning with a convolutional neural net.
These experiments show that end-to-end models trained for note prediction learn frequency
selective filters as a low-level representation of audio.
tl;dr: Fixed typos pointed out by AnonReviewer1 and AnonReviewer4 and added the experiments in Fig. 6 showing the poor scaling of batch normalized SGD using a batch size of 2048 on googlenet.

As more computational resources become available, machine learning researchers train ever larger neural networks on millions of data points using stochastic gradient descent (SGD). Although SGD scales well in terms of both the size of dataset and the number of parameters of the model, it has rapidly diminishing returns as parallel computing resources increase. Second-order optimization methods have an affinity for well-estimated gradients and large mini-batches, and can therefore benefit much more from parallel computation in principle. Unfortunately, they often employ severe approximations to the curvature matrix in order to scale to large models with millions of parameters, limiting their effectiveness in practice versus well-tuned SGD with momentum. The recently proposed K-FAC method(Martens and Grosse, 2015) uses a stronger and more sophisticated curvature approximation, and has been shown to make much more per-iteration progress than SGD, while only introducing a modest overhead. In this paper, we develop a version of K-FAC that distributes the computation of gradients and additional quantities required by K-FAC across multiple machines, thereby taking advantage of method’s superior scaling to large mini-batches and mitigating its additional overheads. We provide a Tensorflow implementation of our approach which is easy to use and can be applied to many existing codebases without modification. Additionally, we develop several algorithmic enhancements to K-FAC which can improve its computational performance for very large models. Finally, we show that our distributed K-FAC method speeds up training of various state-of-the-art ImageNet classification models by a factor of two compared to Batch Normalization(Ioffe and Szegedy, 2015).
tl;dr: Reduce parameter count in recurrent neural networks to create smaller models for faster deployment

Recurrent neural networks (RNN) are widely used to solve a variety of problems and as the quantity of data and the amount of available compute have increased, so have model sizes. The number of parameters in recent state-of-the-art networks makes them hard to deploy, especially on mobile phones and embedded devices. The challenge is due to both the size of the model and the time it takes to evaluate it. In order to deploy these RNNs efficiently, we propose a technique to reduce the parameters of a network by pruning weights during the initial training of the network. At the end of training, the parameters of the network are sparse while accuracy is still close to the original dense neural network. The network size is reduced by 8× and the time required to train the model remains constant. Additionally, we can prune a larger dense network to achieve better than baseline performance while still reducing the total number of parameters significantly. Pruning RNNs reduces the size of the model and can also help achieve significant inference time speed-up using sparse GEMMs. Benchmarks show that using our technique model size can be reduced by 90% and speed-up is around 2× to 7×.
tl;dr: A layered recursive GAN for image generation, which considers the structure in images and can disentangle the foreground objects from background well in unsupervised manner.

We present LR-GAN: an adversarial image generation model which takes scene structure and context into account. Unlike previous generative adversarial networks (GANs), the proposed GAN learns to generate image background and foregrounds separately and recursively, and stitch the foregrounds on the background in a contextually relevant manner to produce a complete natural image. For each foreground, the model learns to generate its appearance, shape and pose. The whole model is unsupervised, and is trained in an end-to-end manner with conventional gradient descent methods. The experiments demonstrate that LR-GAN can generate more natural images with objects that are more human recognizable than baseline GANs.
tl;dr: Using Match-LSTM and Answer Pointer to select a variable length answer from a paragraph

Machine comprehension of text is an important problem in natural language processing. A recently released dataset, the Stanford Question Answering Dataset (SQuAD), offers a large number of real questions and their answers created by humans through crowdsourcing. SQuAD provides a challenging testbed for evaluating machine comprehension algorithms, partly because compared with previous datasets, in SQuAD the answers do not come from a small set of candidate answers and they have variable lengths. We propose an end-to-end neural architecture for the task. The architecture is based on match-LSTM, a model we proposed previously for textual entailment, and Pointer Net, a sequence-to-sequence model proposed by Vinyals et al. (2015) to constrain the output tokens to be from the input sequences. We propose two ways of using Pointer Net for our tasks. Our experiments show that both of our two models substantially outperform the best results obtained by Rajpurkar et al. (2016) using logistic regression and manually crafted features. Besides, our boundary model also achieves the best performance on the MSMARCO dataset (Nguyen et al. 2016).
tl;dr: We present and evaluate an approach for detecting adversarial perturbations in images based on attaching a small subnetwork to a deep neural network that is trained specifically to detect adversarial perturbations.

Machine learning and deep learning in particular has advanced tremendously on perceptual tasks in recent years. However, it remains vulnerable against adversarial perturbations of the input that have been crafted specifically to fool the system while being quasi-imperceptible to a human. In this work, we propose to augment deep neural networks with a small ``detector'' subnetwork which is trained on the binary classification task of distinguishing genuine data from data containing adversarial perturbations. Our method is orthogonal to prior work on addressing adversarial perturbations, which has mostly focused on making the classification network itself more robust. We show empirically that adversarial perturbations can be detected surprisingly well even though they are quasi-imperceptible to humans. Moreover, while the detectors have been trained to detect only a specific adversary, they generalize to similar and weaker adversaries. In addition, we propose an adversarial attack that fools both the classifier and the detector and a novel training procedure for the detector that counteracts this attack.
tl;dr: Paleo: An analytical performance model for exploring the space of scalable deep learning systems and quickly diagnosing their effectiveness for a given problem instance.

Although various scalable deep learning software packages have been proposed, it remains unclear how to best leverage parallel and distributed computing infrastructure to accelerate their training and deployment. Moreover, the effectiveness of existing parallel and distributed systems varies widely based on the neural network architecture and dataset under consideration. In order to efficiently explore the space of scalable deep learning systems and quickly diagnose their effectiveness for a given problem instance, we introduce an analytical performance model called Paleo. Our key observation is that a neural network architecture carries with it a declarative specification of the computational requirements associated with its training and evaluation. By extracting these requirements from a given architecture and mapping them to a specific point within the design space of software, hardware and communication strategies, Paleo can efficiently and accurately model the expected scalability and performance of a putative deep learning system. We show that Paleo is robust to the choice of network architecture, hardware, software, communication schemes, and parallelization strategies. We further demonstrate its ability to accurately model various recently published scalability results for CNNs such as NiN, Inception and AlexNet.

We propose a metric learning framework for the construction of invariant geometric
functions of planar curves for the Euclidean and Similarity group of transformations.
We leverage on the representational power of convolutional neural
networks to compute these geometric quantities. In comparison with axiomatic
constructions, we show that the invariants approximated by the learning architectures
have better numerical qualities such as robustness to noise, resiliency to
sampling, as well as the ability to adapt to occlusion and partiality. Finally, we develop
a novel multi-scale representation in a similarity metric learning paradigm.
155. Automated Generation of Multilingual Clusters for the Evaluation of Distributed Representations
tl;dr: Applying simple heuristics to the Wikidata entity graph results in a high-quality semantic similarity dataset.

We propose a language-agnostic way of automatically generating sets of semantically similar clusters of entities along with sets of "outlier" elements, which may then be used to perform an intrinsic evaluation of word embeddings in the outlier detection task. We used our methodology to create a gold-standard dataset, which we call WikiSem500, and evaluated multiple state-of-the-art embeddings. The results show a correlation between performance on this dataset and performance on sentiment analysis.

Developing accurate predictive models of sensory neurons is vital to understanding sensory processing and brain computations. The current standard approach to modeling neurons is to start with simple models and to incrementally add interpretable features. An alternative approach is to start with a more complex model that captures responses accurately, and then probe the fitted model structure to understand the neural computations. Here, we show that a multitask recurrent neural network (RNN) framework provides the flexibility necessary to model complex computations of neurons that cannot be captured by previous methods. Specifically, multilayer recurrent neural networks that share features across neurons outperform generalized linear models (GLMs) in predicting the spiking responses of parasol ganglion cells in the primate retina to natural images. The networks achieve good predictive performance given surprisingly small amounts of experimental training data. Additionally, we present a novel GLM-RNN hybrid model with separate spatial and temporal processing components which provides insights into the aspects of retinal processing better captured by the recurrent neural networks.

Adversarial examples are malicious inputs designed to fool machine learning models.
They often transfer from one model to another, allowing attackers to mount black
box attacks without knowledge of the target model's parameters.
Adversarial training is the process of explicitly training a model on adversarial
examples, in order to make it more robust to attack or to reduce its test error
on clean inputs.
So far, adversarial training has primarily been applied to small problems.
In this research, we apply adversarial training to ImageNet.
Our contributions include:
(1) recommendations for how to succesfully scale adversarial training to large models and datasets,
(2) the observation that adversarial training confers robustness to single-step attack methods,
(3) the finding that multi-step attack methods are somewhat less transferable than single-step attack
methods, so single-step attacks are the best for mounting black-box attacks,
and
(4) resolution of a ``label leaking'' effect that causes adversarially trained models to perform
better on adversarial examples than on clean examples, because the adversarial
example construction process uses the true label and the model can learn to
exploit regularities in the construction process.
tl;dr: A new architecture for generating tree-structured objects from encoded representations, which models separately the width and depth recurrences across the tree and predicts both content and topology.

We propose a neural network architecture for generating tree-structured objects from encoded representations. The core of the method is a doubly-recurrent neural network that models separately the width and depth recurrences across the tree, and combines them inside each cell to generate an output. The topology of the tree is explicitly modeled, allowing the network to predict both content and topology of the tree when decoding. That is, given only an encoded vector representation, the network is able to simultaneously generate a tree from it and predict labels for the nodes. We test this architecture in an encoder-decoder framework, where we train a network to encode a sentence as a vector, and then generate a tree structure from it. The experimental results show the effectiveness of this architecture at recovering latent tree structure in sequences and at mapping sentences to simple functional programs.
tl;dr: We propose a simple extension to the Gatys et al. algorithm which makes it possible to incorporate long-range structure into texture generation.

Gatys et al. (2015) showed that pair-wise products of features in a convolutional network are a very effective representation of image textures. We propose a simple modification to that representation which makes it possible to incorporate long-range structure into image generation, and to render images that satisfy various symmetry constraints. We show how this can greatly improve rendering of regular textures and of images that contain other kinds of symmetric structure. We also present applications to inpainting and season transfer.
160. Mollifying Networks
tl;dr: We are proposing a new continuation method for neural networks, that starts from optimizing a convex objective function and gradually during the training the function evolves into more non-convex function.

The optimization of deep neural networks can be more challenging than the traditional convex optimization problems due to highly non-convex nature of the loss function, e.g. it can involve pathological landscapes such as saddle-surfaces that can be difficult to escape from for algorithms based on simple gradient descent. In this paper, we attack the problem of optimization of highly non-convex neural networks objectives by starting with a smoothed -- or mollified -- objective function which becomes more complex as the training proceeds. Our proposition is inspired by the recent studies in continuation methods: similarly to curriculum methods, we begin by learning an easier (possibly convex) objective function and let it evolve during training until it eventually becomes the original, difficult to optimize objective function. The complexity of the mollified networks is controlled by a single hyperparameter that is annealed during training. We show improvements on various difficult optimization tasks and establish a relationship between recent works on continuation methods for neural networks and mollifiers.
tl;dr: a new model for extracting an interpretable sentence embedding by introducing self-attention and matrix representation.

This paper proposes a new model for extracting an interpretable sentence embedding by introducing self-attention. Instead of using a vector, we use a 2-D matrix to represent the embedding, with each row of the matrix attending on a different part of the sentence. We also propose a self-attention mechanism and a special regularization term for the model. As a side effect, the embedding comes with an easy way of visualizing what specific parts of the sentence are encoded into the embedding. We evaluate our model on 3 different tasks: author profiling, sentiment classification and textual entailment. Results show that our model yields a significant performance gain compared to other sentence embedding methods in all of the 3 tasks.

In many computer vision tasks, the relevant information to solve the problem at hand is mixed to irrelevant, distracting information. This has motivated researchers to design attentional models that can dynamically focus on parts of images or videos that are salient, e.g., by down-weighting irrelevant pixels. In this work, we propose a spatiotemporal attentional model that learns where to look in a video directly from human fixation data. We model visual attention with a mixture of Gaussians at each frame. This distribution is used to express the probability of saliency for each pixel. Time consistency in videos is modeled hierarchically by: 1) deep 3D convolutional features to represent spatial and short-term time relations and 2) a long short-term memory network on top that aggregates the clip-level representation of sequential clips and therefore expands the temporal domain from few frames to seconds. The parameters of the proposed model are optimized via maximum likelihood estimation using human fixations as training data, without knowledge of the action in each video. Our experiments on Hollywood2 show state-of-the-art performance on saliency prediction for video. We also show that our attentional model trained on Hollywood2 generalizes well to UCF101 and it can be leveraged to improve action classification accuracy on both datasets.
tl;dr: To our knowledge, this paper presents the first weakly supervised, end-to-end neural network model to induce programs on a real-world dataset.

Learning a natural language interface for database tables is a challenging task that involves deep language understanding and multi-step reasoning. The task is often approached by mapping natural language queries to logical forms or programs that provide the desired response when executed on the database. To our knowledge, this paper presents the first weakly supervised, end-to-end neural network model to induce such programs on a real-world dataset. We enhance the objective function of Neural Programmer, a neural network with built-in discrete operations, and apply it on WikiTableQuestions, a natural language question-answering dataset. The model is trained end-to-end with weak supervision of question-answer pairs, and does not require domain-specific grammars, rules, or annotations that are key elements in previous approaches to program induction. The main experimental result in this paper is that a single Neural Programmer model achieves 34.2% accuracy using only 10,000 examples with weak supervision. An ensemble of 15 models, with a trivial combination technique, achieves 37.7% accuracy, which is competitive to the current state-of-the-art accuracy of 37.1% obtained by a traditional natural language semantic parser.
tl;dr: We automatically set the size of an MLP by adding and removing units during training as appropriate.

Automatically determining the optimal size of a neural network for a given task without prior information currently requires an expensive global search and training many networks from scratch. In this paper, we address the problem of automatically finding a good network size during a single training cycle. We introduce {\it nonparametric neural networks}, a non-probabilistic framework for conducting optimization over all possible network sizes and prove its soundness when network growth is limited via an $\ell_p$ penalty. We train networks under this framework by continuously adding new units while eliminating redundant units via an $\ell_2$ penalty. We employ a novel optimization algorithm, which we term ``Adaptive Radial-Angular Gradient Descent'' or {\it AdaRad}, and obtain promising results.
tl;dr: Emerging theory explaining residual networks alongside new empirical progress

An emerging design principle in deep learning is that each layer of a deep
artificial neural network should be able to easily express the identity
transformation. This idea not only motivated various normalization techniques,
such as batch normalization, but was also key to the immense success of
residual networks.
In this work, we put the principle of identity parameterization on a more
solid theoretical footing alongside further empirical progress. We first
give a strikingly simple proof that arbitrarily deep linear residual networks
have no spurious local optima. The same result for feed-forward networks in
their standard parameterization is substantially more delicate. Second, we
show that residual networks with ReLu activations have universal finite-sample
expressivity in the sense that the network can represent any function of its
sample provided that the model has more parameters than the sample size.
Directly inspired by our theory, we experiment with a radically simple
residual architecture consisting of only residual convolutional layers and
ReLu activations, but no batch normalization, dropout, or max pool. Our model
improves significantly on previous all-convolutional networks on the CIFAR10,
CIFAR100, and ImageNet classification benchmarks.
tl;dr: We got autoencoding variational bayes to work for latent Dirichlet allocation using one weird trick. The new inference method then made it easy to make a new topic model that works even better than LDA.

Topic models are one of the most popular methods for learning representations of
text, but a major challenge is that any change to the topic model requires mathematically
deriving a new inference algorithm. A promising approach to address
this problem is autoencoding variational Bayes (AEVB), but it has proven diffi-
cult to apply to topic models in practice. We present what is to our knowledge the
first effective AEVB based inference method for latent Dirichlet allocation (LDA),
which we call Autoencoded Variational Inference For Topic Model (AVITM). This
model tackles the problems caused for AEVB by the Dirichlet prior and by component
collapsing. We find that AVITM matches traditional methods in accuracy
with much better inference time. Indeed, because of the inference network, we
find that it is unnecessary to pay the computational cost of running variational
optimization on test data. Because AVITM is black box, it is readily applied
to new topic models. As a dramatic illustration of this, we present a new topic
model called ProdLDA, that replaces the mixture model in LDA with a product
of experts. By changing only one line of code from LDA, we find that ProdLDA
yields much more interpretable topics, even if LDA is trained via collapsed Gibbs
sampling.
tl;dr: Prepared for ICLR 2017.

This paper presents an actor-critic deep reinforcement learning agent with experience replay that is stable, sample efficient, and performs remarkably well on challenging environments, including the discrete 57-game Atari domain and several continuous control problems. To achieve this, the paper introduces several innovations, including truncated importance sampling with bias correction, stochastic dueling network architectures, and a new trust region policy optimization method.
168. Sparsely-Connected Neural Networks: Towards Efficient VLSI Implementation of Deep Neural Networks
tl;dr: We show that the number of connections in fully-connected networks can be reduced by up to 90% while improving the accuracy performance.

Recently deep neural networks have received considerable attention due to their ability to extract and represent high-level abstractions in data sets. Deep neural networks such as fully-connected and convolutional neural networks have shown excellent performance on a wide range of recognition and classification tasks. However, their hardware implementations currently suffer from large silicon area and high power consumption due to the their high degree of complexity. The power/energy consumption of neural networks is dominated by memory accesses, the majority of which occur in fully-connected networks. In fact, they contain most of the deep neural network parameters. In this paper, we propose sparsely-connected networks, by showing that the number of connections in fully-connected networks can be reduced by up to 90% while improving the accuracy performance on three popular datasets (MNIST, CIFAR10 and SVHN). We then propose an efficient hardware architecture based on linear-feedback shift registers to reduce the memory requirements of the proposed sparsely-connected networks. The proposed architecture can save up to 90% of memory compared to the conventional implementations of fully-connected neural networks. Moreover, implementation results show up to 84% reduction in the energy consumption of a single neuron of the proposed sparsely-connected networks compared to a single neuron of fully-connected neural networks.
tl;dr: Simple, differentiable sampling mechanism for categorical variables that can be trained in neural nets via standard backprop.

Categorical variables are a natural choice for representing discrete structure in the world. However, stochastic neural networks rarely use categorical latent variables due to the inability to backpropagate through samples. In this work, we present an efficient gradient estimator that replaces the non-differentiable sample from a categorical distribution with a differentiable sample from a novel Gumbel-Softmax distribution. This distribution has the essential property that it can be smoothly annealed into a categorical distribution. We show that our Gumbel-Softmax estimator outperforms state-of-the-art gradient estimators on structured output prediction and unsupervised generative modeling tasks with categorical latent variables, and enables large speedups on semi-supervised classification.
tl;dr: Applying the information bottleneck to deep networks using the variational lower bound and reparameterization trick.

We present a variational approximation to the information bottleneck of Tishby et al. (1999). This variational approach allows us to parameterize the information bottleneck model using a neural network and leverage the reparameterization trick for efficient training. We call this method “Deep Variational Information Bottleneck”, or Deep VIB. We show that models trained with the VIB objective outperform those that are trained with other forms of regularization, in terms of generalization performance and robustness to adversarial attack.

We consider the problem of inferring a sequence of hidden states associated with a sequence of observations produced by an individual within a population. Instead of learning a single sequence model for the population (which does not account for variations within the population), we learn a set of basis sequence models based on different individuals. The sequence of hidden states for a new individual is inferred in an online fashion by estimating a distribution over the basis models that best explain the sequence of observations of this new individual. We explain how to do this in the context of hidden Markov models with Gaussian mixture models that are learned based on streaming data by online Bayesian moment matching. The resulting transfer learning technique is demonstrated with three real-word applications: activity recognition based on smartphone sensors, sleep classification based on electroencephalography data and the prediction of the direction of future packet flows between a pair of servers in telecommunication networks.
tl;dr: Highly-performance sparse convolution outperforms dense with only 70% sparsity. Performance model that guides training to find useful sparsity range, applied to AlexNet and GoogLeNet

Phenomenally successful in practical inference problems, convolutional neural networks (CNN) are widely deployed in mobile devices, data centers, and even supercomputers.
The number of parameters needed in CNNs, however, are often large and undesirable. Consequently, various methods have been developed to prune a CNN once it is trained.
Nevertheless, the resulting CNNs offer limited benefits. While pruning the fully connected layers reduces a CNN's size considerably, it does not improve inference speed noticeably as the compute heavy parts lie in convolutions. Pruning CNNs in a way that increase inference speed often imposes specific sparsity structures, thus limiting the achievable sparsity levels.
We present a method to realize simultaneously size economy and speed improvement while pruning CNNs. Paramount to our success is an efficient general sparse-with-dense matrix
multiplication implementation that is applicable to convolution of feature maps with kernels of arbitrary sparsity patterns. Complementing this, we developed a performance model that predicts sweet spots of sparsity levels for different layers and on different computer architectures. Together, these two allow us to demonstrate 3.1-7.3x convolution speedups over dense convolution in AlexNet, on Intel Atom, Xeon, and Xeon Phi processors, spanning the spectrum from mobile devices to supercomputers.
tl;dr: Learning a common feature space between robots with different morphology or actuation to transfer skills.

People can learn a wide range of tasks from their own experience, but can also learn from observing other creatures. This can accelerate acquisition of new skills even when the observed agent differs substantially from the learning agent in terms of morphology. In this paper, we examine how reinforcement learning algorithms can transfer knowledge between morphologically different agents (e.g., different robots). We introduce a problem formulation where twp agents are tasked with learning multiple skills by sharing information. Our method uses the skills that were learned by both agents to train invariant feature spaces that can then be used to transfer other skills from one agent to another. The process of learning these invariant feature spaces can be viewed as a kind of ``analogy making,'' or implicit learning of partial correspondences between two distinct domains. We evaluate our transfer learning algorithm in two simulated robotic manipulation skills, and illustrate that we can transfer knowledge between simulated robotic arms with different numbers of links, as well as simulated arms with different actuation mechanisms, where one robot is torque-driven while the other is tendon-driven.
tl;dr: We proposed a deep RL method, augmented with memory and auxiliary learning targets, for training agents to navigate within large and visually rich environments that include frequently changing start and goal locations

Learning to navigate in complex environments with dynamic elements is an important milestone in developing AI agents. In this work we formulate the navigation question as a reinforcement learning problem and show that data efficiency and task performance can be dramatically improved by relying on additional auxiliary tasks to bootstrap learning. In particular we consider jointly learning the goal-driven reinforcement learning problem with an unsupervised depth prediction task and a self-supervised loop closure classification task. Using this approach we can learn to navigate from raw sensory input in complicated 3D mazes, approaching human-level performance even under conditions where the goal location changes frequently. We provide detailed analysis of the agent behaviour, its ability to localise, and its network activity dynamics, that show that the agent implicitly learns key navigation abilities, with only sparse rewards and without direct supervision.

We develop a first line of attack for solving programming competition-style problems from input-output examples using deep learning. The approach is to train a neural network to predict properties of the program that generated the outputs from the inputs. We use the neural network's predictions to augment search techniques from the programming languages community, including enumerative search and an SMT-based solver. Empirically, we show that our approach leads to an order of magnitude speedup over the strong non-augmented baselines and a Recurrent Neural Network approach, and that we are able to solve problems of difficulty comparable to the simplest problems on programming competition websites.
tl;dr: We analyse the mechanisms which permit to accelerate sparse coding resolution using the problem structure, as it is the case in LISTA.

Sparse coding is a core building block in many data analysis and machine learning pipelines. Typically it is solved by relying on generic optimization techniques, such as the Iterative Soft Thresholding Algorithm and its accelerated version (ISTA, FISTA). These methods are optimal in the class of first-order methods for non-smooth, convex functions. However, they do not exploit the particular structure of the problem at hand nor the input data distribution. An acceleration using neural networks, coined LISTA, was proposed in \cite{Gregor10}, which showed empirically that one could achieve high quality estimates with few iterations by modifying the parameters of the proximal splitting appropriately.
In this paper we study the reasons for such acceleration. Our mathematical analysis reveals that it is related to a specific matrix factorization of the Gram kernel of the dictionary, which attempts to nearly diagonalise the kernel with a basis that produces a small perturbation of the $\ell_1$ ball. When this factorization succeeds, we prove that the resulting splitting algorithm enjoys an improved convergence bound with respect to the non-adaptive version. Moreover, our analysis also shows that conditions for acceleration occur mostly at the beginning of the iterative process, consistent with numerical experiments. We further validate our analysis by showing that on dictionaries where this factorization does not exist, adaptive acceleration fails.

We introduce Deep Variational Bayes Filters (DVBF), a new method for unsupervised learning and identification of latent Markovian state space models. Leveraging recent advances in Stochastic Gradient Variational Bayes, DVBF can overcome intractable inference distributions via variational inference. Thus, it can handle highly nonlinear input data with temporal and spatial dependencies such as image sequences without domain knowledge. Our experiments show that enabling backpropagation through transitions enforces state space assumptions and significantly improves information content of the latent embedding. This also enables realistic long-term prediction.

In this work we study the problem of network morphism, an effective learning scheme to morph a well-trained neural network to a new one with the network function completely preserved. Different from existing work where basic morphing types on the layer level were addressed, we target at the central problem of network morphism at a higher level, i.e., how a convolutional layer can be morphed into an arbitrary module of a neural network. To simplify the representation of a network, we abstract a module as a graph with blobs as vertices and convolutional layers as edges, based on which the morphing process is able to be formulated as a graph transformation problem. Two atomic morphing operations are introduced to compose the graphs, based on which modules are classified into two families, i.e., simple morphable modules and complex modules. We present practical morphing solutions for both of these two families, and prove that any reasonable module can be morphed from a single convolutional layer. Extensive experiments have been conducted based on the state-of-the-art ResNet on benchmark datasets, and the effectiveness of the proposed solution has been verified.
tl;dr: Ternary Neural Network with accuracy close to or even higher than the full-precision one

Deep neural networks are widely used in machine learning applications. However, the deployment of large neural networks models can be difficult to deploy on mobile devices with limited power budgets. To solve this problem, we propose Trained Ternary Quantization (TTQ), a method that can reduce the precision of weights in neural networks to ternary values. This method has very little accuracy degradation and can even improve the accuracy of some models (32, 44, 56-layer ResNet) on CIFAR-10 and AlexNet on ImageNet. And our AlexNet model is trained from scratch, which means it’s as easy as to train normal full precision model. We highlight our trained quantization method that can learn both ternary values and ternary assignment. During inference, only ternary values (2-bit weights) and scaling factors are needed, therefore our models are nearly 16× smaller than full- precision models. Our ternary models can also be viewed as sparse binary weight networks, which can potentially be accelerated with custom circuit. Experiments on CIFAR-10 show that the ternary models obtained by trained quantization method outperform full-precision models of ResNet-32,44,56 by 0.04%, 0.16%, 0.36%, respectively. On ImageNet, our model outperforms full-precision AlexNet model by 0.3% of Top-1 accuracy and outperforms previous ternary models by 3%.
tl;dr: We introduce beta-VAE, a new state-of-the-art framework for automated discovery of interpretable factorised latent representations from raw image data in a completely unsupervised manner.

Learning an interpretable factorised representation of the independent data generative factors of the world without supervision is an important precursor for the development of artificial intelligence that is able to learn and reason in the same way that humans do. We introduce beta-VAE, a new state-of-the-art framework for automated discovery of interpretable factorised latent representations from raw image data in a completely unsupervised manner. Our approach is a modification of the variational autoencoder (VAE) framework. We introduce an adjustable hyperparameter beta that balances latent channel capacity and independence constraints with reconstruction accuracy. We demonstrate that beta-VAE with appropriately tuned
beta > 1 qualitatively outperforms VAE (beta = 1), as well as state of the art unsupervised (InfoGAN) and semi-supervised (DC-IGN) approaches to disentangled factor learning on a variety of datasets (celebA, faces and chairs). Furthermore, we devise a protocol to quantitatively compare the degree of disentanglement learnt by different models, and show that our approach also significantly outperforms all baselines quantitatively. Unlike InfoGAN, beta-VAE is stable to train, makes few assumptions about the data and relies on tuning a single hyperparameter, which can be directly optimised through a hyper parameter search using weakly labelled data or through heuristic visual inspection for purely unsupervised data.
tl;dr: A hardware accelerator for DNNs whose execution time for convolutional layers is proportional to the number of activation *bits* that are 1.

We quantify a source of ineffectual computations when processing the multiplications of the convolutional layers in Deep Neural Networks (DNNs) and propose Pragrmatic (PRA), an architecture that exploits it improving performance and energy efficiency.
The source of these ineffectual computations is best understood in the context of conventional multipliers which generate internally multiple terms, that is, products of the multiplicand and powers of two, which added together produce the final product. At runtime, many of these terms are zero as they are generated when the multiplicand is combined with the zero-bits of the multiplicator. While conventional bit-parallel multipliers calculate all terms in parallel to reduce individual product latency, PRA calculates only the non-zero terms resulting in a design whose execution time for convolutional layers is ideally proportional to the number of activation bits that are 1. Measurements demonstrate that for the convolutional layers on Convolutional Neural Networks and during inference, PRA improves performance by 4.3x over the DaDiaNao (DaDN) accelerator and by 4.5x when DaDN uses an 8-bit quantized representation. DaDN was reported to be 300x faster than commodity graphics processors.
182. Exponential Machines
tl;dr: A supervised machine learning algorithm with a polynomial decision function (like SVM with a polynomial kernel) that models exponentially many polynomial terms by factorizing the tensor of the parameters.

Modeling interactions between features improves the performance of machine learning solutions in many domains (e.g. recommender systems or sentiment analysis). In this paper, we introduce Exponential Machines (ExM), a predictor that models all interactions of every order. The key idea is to represent an exponentially large tensor of parameters in a factorized format called Tensor Train (TT). The Tensor Train format regularizes the model and lets you control the number of underlying parameters. To train the model, we develop a stochastic Riemannian optimization procedure, which allows us to fit tensors with 2^160 entries. We show that the model achieves state-of-the-art performance on synthetic data with high-order interactions and that it works on par with high-order factorization machines on a recommender system dataset MovieLens 100K.

Although Generative Adversarial Networks achieve state-of-the-art results on a
variety of generative tasks, they are regarded as highly unstable and prone to miss
modes. We argue that these bad behaviors of GANs are due to the very particular
functional shape of the trained discriminators in high dimensional spaces, which
can easily make training stuck or push probability mass in the wrong direction,
towards that of higher concentration than that of the data generating distribution.
We introduce several ways of regularizing the objective, which can dramatically
stabilize the training of GAN models. We also show that our regularizers can help
the fair distribution of probability mass across the modes of the data generating
distribution during the early phases of training, thus providing a unified solution
to the missing modes problem.

An intriguing property of deep neural networks is the existence of adversarial examples, which can transfer among different architectures. These transferable adversarial examples may severely hinder deep neural network-based applications. Previous works mostly study the transferability using small scale datasets. In this work, we are the first to conduct an extensive study of the transferability over large models and a large scale dataset, and we are also the first to study the transferability of targeted adversarial examples with their target labels. We study both non-targeted and targeted adversarial examples, and show that while transferable non-targeted adversarial examples are easy to find, targeted adversarial examples generated using existing approaches almost never transfer with their target labels. Therefore, we propose novel ensemble-based approaches to generating transferable adversarial examples. Using such approaches, we observe a large proportion of targeted adversarial examples that are able to transfer with their target labels for the first time. We also present some geometric studies to help understanding the transferable adversarial examples. Finally, we show that the adversarial examples generated using ensemble-based approaches can successfully attack Clarifai.com, which is a black-box image classification system.
tl;dr: Autoregressive text-to-image synthesis with controllable spatial structure.

We demonstrate improved text-to-image synthesis with controllable object locations using an extension of Pixel Convolutional Neural Networks (PixelCNN). In addition to conditioning on text, we show how the model can generate images conditioned on part keypoints and segmentation masks. The character-level text encoder and image generation network are jointly trained end-to-end via maximum likelihood. We establish quantitative baselines in terms of text and structure-conditional pixel log-likelihood for three data sets: Caltech-UCSD Birds (CUB), MPII Human Pose (MHP), and Common Objects in Context (MS-COCO).
tl;dr: We show constructively that deep networks can learn to represent manifold data efficiently

We consider the ability of deep neural networks to represent data that lies near a low-dimensional manifold in a high-dimensional space. We show that deep networks can efficiently extract the intrinsic, low-dimensional coordinates of such data. Specifically we show that the first two layers of a deep network can exactly embed points lying on a monotonic chain, a special type of piecewise linear manifold, mapping them to a low-dimensional Euclidean space. Remarkably, the network can do this using an almost optimal number of parameters. We also show that this network projects nearby points onto the manifold and then embeds them with little error. Experiments demonstrate that training with stochastic gradient descent can indeed find efficient representations similar to the one presented in this paper.

We propose the Neural Program Lattice (NPL), a neural network that learns to perform complex tasks by composing low-level programs to express high-level programs. Our starting point is the recent work on Neural Programmer-Interpreters (NPI), which can only learn from strong supervision that contains the whole hierarchy of low-level and high-level programs. NPLs remove this limitation by providing the ability to learn from weak supervision consisting only of sequences of low-level operations. We demonstrate the capability of NPL to learn to perform long-hand addition and arrange blocks in a grid-world environment. Experiments show that it performs on par with NPI while using weak supervision in place of most of the strong supervision, thus indicating its ability to infer the high-level program structure from examples containing only the low-level operations.
tl;dr: Learn a dynamics model and use it to make your agent boldly go where it has not gone before.

Exploration in complex domains is a key challenge in reinforcement learning, especially for tasks with very sparse rewards. Recent successes in deep reinforcement learning have been achieved mostly using simple heuristic exploration strategies such as $\epsilon$-greedy action selection or Gaussian control noise, but there are many tasks where these methods are insufficient to make any learning progress. Here, we consider more complex heuristics: efficient and scalable exploration strategies that maximize a notion of an agent's surprise about its experiences via intrinsic motivation. We propose to learn a model of the MDP transition probabilities concurrently with the policy, and to form intrinsic rewards that approximate the KL-divergence of the true transition probabilities from the learned model. One of our approximations results in using surprisal as intrinsic motivation, while the other gives the $k$-step learning progress. We show that our incentives enable agents to succeed in a wide range of environments with high-dimensional state spaces and very sparse rewards, including continuous control tasks and games in the Atari RAM domain, outperforming several other heuristic exploration techniques.
tl;dr: Sparse graphical model structure estimators make restrictive assumptions. We show that empirical risk minimization can yield SOTA estimators for edge prediction across a wide range of graph structure distributions.

We consider structure discovery of undirected graphical models from observational data. Inferring likely structures from few examples is a complex task often requiring the formulation of priors and sophisticated inference procedures. In the setting of Gaussian Graphical Models (GGMs) a popular estimator is a maximum likelihood objective with a penalization on the precision matrix. Adapting this estimator to capture domain-specific knowledge as priors or a new data likelihood requires great effort. In addition, structure recovery is an indirect consequence of the data-fit term. By contrast, it may be easier to generate training samples of data that arise from graphs with the desired structure properties. We propose here to leverage this latter source of information as training data to learn a function mapping from empirical covariance matrices to estimated graph structures. Learning this function brings two benefits: it implicitly models the desired structure or sparsity properties to form suitable priors, and it can be tailored to the specific problem of edge structure discovery, rather than maximizing data likelihood. We apply this framework to several real-world problems in structure discovery and show that it can be competitive to standard approaches such as graphical lasso, at a fraction of the execution speed. We use convolutional neural networks to parametrize our estimators due to the compositional structure of the problem. Experimentally, our learnable graph-discovery method trained on synthetic data generalizes well to different data: identifying relevant edges in real data, completely unknown at training time. We find that on genetics, brain imaging, and simulation data we obtain competitive(and generally superior) performance, compared with analytical methods.

Attention plays a critical role in human visual experience. Furthermore, it has recently been demonstrated that attention can also play an important role in the context of applying artificial neural networks to a variety of tasks from fields such as computer vision and NLP. In this work we show that, by properly defining attention for convolutional neural networks, we can actually use this type of information in order to significantly improve the performance of a student CNN network by forcing it to mimic the attention maps of a powerful teacher network. To that end, we propose several novel methods of transferring attention, showing consistent improvement across a variety of datasets and convolutional neural network architectures.
tl;dr: A new class of nonparametric activation functions for deep learning with theoretical guarantees for generalization error.

We provide a principled framework for nonparametrically learning activation functions in deep neural networks. Currently, state-of-the-art deep networks treat choice of activation function as a hyper-parameter before training. By allowing activation functions to be estimated as part of the training procedure, we expand the class of functions that each node in the network can learn. We also provide a theoretical justification for our choice of nonparametric activation functions and demonstrate that networks with our nonparametric activation functions generalize well. To demonstrate the power of our novel techniques, we test them on image recognition datasets and achieve up to a 15% relative increase in test performance compared to the baseline.
tl;dr: Methods to Detect When a Network Is Wrong

We consider the two related problems of detecting if an example is misclassified or out-of-distribution. We present a simple baseline that utilizes probabilities from softmax distributions. Correctly classified examples tend to have greater maximum softmax probabilities than erroneously classified and out-of-distribution examples, allowing for their detection. We assess performance by defining several tasks in computer vision, natural language processing, and automatic speech recognition, showing the effectiveness of this baseline across all. We then show the baseline can sometimes be surpassed, demonstrating the room for future research on these underexplored detection tasks.
tl;dr: This paper presents the first neural implementation of an abstract machine for an actual language, allowing programmers to inject prior procedural knowledge into neural architectures in a straightforward manner.

There are families of neural networks that can learn to compute any function, provided sufficient training data. However, given that in practice training data is scarce for all but a small set of problems, a core question is how to incorporate prior knowledge into a model. Here we consider the case of prior procedural knowledge, such as knowing the overall recursive structure of a sequence transduction program or the fact that a program will likely use arithmetic operations on real numbers to solve a task. To this end we present a differentiable interpreter for the programming language Forth. Through a neural implementation of the dual stack machine that underlies Forth, programmers can write program sketches with slots that can be filled with behaviour trained from program input-output data. As the program interpreter is end-to-end differentiable, we can optimize this behaviour directly through gradient descent techniques on user specified objectives, and also integrate the program into any larger neural computation graph. We show empirically that our interpreter is able to effectively leverage different levels of prior program structure and learn complex transduction tasks such as sequence sorting or addition with substantially less data and better generalisation over problem sizes. In addition, we introduce neural program optimisations based on symbolic computation and parallel branching that lead to significant speed improvements.
tl;dr: DCNN trained with multiple views of the same object can develop human-like perpetual similarity judgment that can transfer to novel objects

We develop a model of perceptual similarity judgment based on re-training a deep convolution neural network (DCNN) that learns to associate different views of each 3D object to capture the notion of object persistence and continuity in our visual experience. The re-training process effectively performs distance metric learning under the object persistency constraints, to modify the view-manifold of object representations. It reduces the effective distance between the representations of different views of the same object without compromising the distance between those of the views of different objects, resulting in the untangling of the view-manifolds between individual objects within the same category and across categories. This untangling enables the model to discriminate and recognize objects within the same category, independent of viewpoints. We found that this ability is not limited to the trained objects, but transfers to novel objects in both trained and untrained categories, as well as to a variety of completely novel artificial synthetic objects. This transfer in learning suggests the modification of distance metrics in view- manifolds is more general and abstract, likely at the levels of parts, and independent of the specific objects or categories experienced during training. Interestingly, the resulting transformation of feature representation in the deep networks is found to significantly better match human perceptual similarity judgment than AlexNet, suggesting that object persistence could be an important constraint in the development of perceptual similarity judgment in biological neural networks.
tl;dr: we explore a reinforcement learning setting for dialogue where the bot improves its abilities using reward-based or textual feedback

An important aspect of developing conversational agents is to give a bot the ability to improve through communicating with humans and to learn from the mistakes that it makes. Most research has focused on learning from fixed training sets of labeled data rather than interacting with a dialogue partner in an online fashion. In this paper we explore this direction in a reinforcement learning setting where the bot improves its question-answering ability from feedback a teacher gives following its generated responses. We build a simulator that tests various aspects of such learning in a synthetic environment, and introduce models that work in this regime. Finally, real experiments with Mechanical Turk validate the approach.
tl;dr: A Q-learning algorithm for automatically generating neural nets

At present, designing convolutional neural network (CNN) architectures requires both human expertise and labor. New architectures are handcrafted by careful experimentation or modified from a handful of existing networks. We introduce MetaQNN, a meta-modeling algorithm based on reinforcement learning to automatically generate high-performing CNN architectures for a given learning task. The learning agent is trained to sequentially choose CNN layers using $Q$-learning with an $\epsilon$-greedy exploration strategy and experience replay. The agent explores a large but finite space of possible architectures and iteratively discovers designs with improved performance on the learning task. On image classification benchmarks, the agent-designed networks (consisting of only standard convolution, pooling, and fully-connected layers) beat existing networks designed with the same layer types and are competitive against the state-of-the-art methods that use more complex layer types. We also outperform existing meta-modeling approaches for network design on image classification tasks.

The standard approach to supervised classification involves the minimization of a log-loss as an upper bound to the classification error. While this is a tight bound early on in the optimization, it overemphasizes the influence of incorrectly classified examples far from the decision boundary. Updating the upper bound during the optimization leads to improved classification rates while transforming the learning into a sequence of minimization problems. In addition, in the context where the classifier is part of a larger system, this modification makes it possible to link the performance of the classifier to that of the whole system, allowing the seamless introduction of external constraints.
tl;dr: We show that an RNN can learn to control the amount of computation it does at each time step, leading to better efficiency and performance as well as discovering time patterns of interest.

Recurrent neural networks (RNNs) have been used extensively and with increasing success to model various types of sequential data. Much of this progress has been achieved through devising recurrent units and architectures with the flexibility to capture complex statistics in the data, such as long range dependency or localized attention phenomena. However, while many sequential data (such as video, speech or language) can have highly variable information flow, most recurrent models still consume input features at a constant rate and perform a constant number of computations per time step, which can be detrimental to both speed and model capacity. In this paper, we explore a modification to existing recurrent units which allows them to learn to vary the amount of computation they perform at each step, without prior knowledge of the sequence's time structure. We show experimentally that not only do our models require fewer operations, they also lead to better performance overall on evaluation tasks.
tl;dr: Assign continuous vectors to logical and algebraic symbolic expressions in such a way that semantically equivalent, but syntactically diverse expressions are assigned to identical (or highly similar) continuous vectors.

The question of how procedural knowledge is represented and inferred is a fundamental problem in machine learning and artificial intelligence. Recent work on program induction has proposed neural architectures, based on abstractions like stacks, Turing machines, and interpreters, that operate on abstract computational machines or on execution traces. But the recursive abstraction that is central to procedural knowledge is perhaps most naturally represented by symbolic representations that have syntactic structure, such as logical expressions and source code. Combining abstract, symbolic reasoning with continuous neural reasoning is a grand challenge of representation learning. As a step in this direction, we propose a new architecture, called neural equivalence networks, for the problem of learning continuous semantic representations of mathematical and logical expressions. These networks are trained to represent semantic equivalence, even of expressions that are syntactically very different. The challenge is that semantic representations must be computed in a syntax-directed manner, because semantics is compositional, but at the same time, small changes in syntax can lead to very large changes in semantics, which can be difficult for continuous neural architectures. We perform an exhaustive evaluation on the task of checking equivalence on a highly diverse class of symbolic algebraic and boolean expression types, showing that our model significantly outperforms existing architectures.
tl;dr: Development of JavaScript-based matrix library and deep learning library which uses GPGPU. VGGNet is trained distributedly using web browsers.

Deep learning is increasingly attracting attention for processing big data.
Existing frameworks for deep learning must be set up to specialized computer systems. Gaining sufficient computing resources therefore entails high costs of deployment and maintenance.
In this work, we implement a matrix library and deep learning framework that uses JavaScript. It can run on web browsers operating on ordinary personal computers and smartphones.
Using JavaScript, deep learning can be accomplished in widely diverse environments without the necessity for software installation. Using GPGPU from WebCL framework, our framework can train large scale convolutional neural networks such as VGGNet and ResNet.
In the experiments, we demonstrate their practicality by training VGGNet in a distributed manner using web browsers as the client.
tl;dr: We embed a 3D model in the GAN framework to generate realistic, labeled data.

Deep Convolutional Neuronal Networks (DCNNs) are showing remarkable performance on many computer vision tasks. Due to their large parameter space, they require many labeled samples when trained in a supervised setting. The costs of annotating data manually can render the use of DCNNs infeasible. We present a novel framework called RenderGAN that can generate large amounts of realistic, labeled images by combining a 3D model and the Generative Adversarial Network framework. In our approach, image augmentations (e.g. lighting, background, and detail) are learned from unlabeled data such that the generated images are strikingly realistic while preserving the labels known from the 3D model. We apply the RenderGAN framework to generate images of barcode-like markers that are attached to honeybees. Training a DCNN on data generated by the RenderGAN yields considerably better performance than training it on various baselines.
tl;dr: We provide the first convergence result for rectifier neural networks and investigate implications for exploration in shattered landscapes.
Modern convolutional networks, incorporating rectifiers and max-pooling, are neither smooth nor convex. Standard guarantees therefore do not apply. Nevertheless, methods from convex optimization such as gradient descent and Adam are widely used as building blocks for deep learning algorithms. This paper provides the first convergence guarantee applicable to modern convnets. The guarantee matches a lower bound for convex nonsmooth functions. The key technical tool is the neural Taylor approximation -- a straightforward application of Taylor expansions to neural networks -- and the associated Taylor loss. Experiments on a range of optimizers, layers, and tasks provide evidence that the analysis accurately captures the dynamics of neural optimization.
The second half of the paper applies the Taylor approximation to isolate the main difficulty in training rectifier nets: that gradients are shattered. We investigate the hypothesis that, by exploring the space of activation configurations more thoroughly, adaptive optimizers such as RMSProp and Adam are able to converge to better solutions.
tl;dr: Gated Multimodal Units: a novel unit that learns to combine multiple modalities using multiplicative gates

This paper presents a novel model for multimodal learning based on gated neural networks. The Gated Multimodal Unit (GMU) model is intended to be used as an internal unit in a neural network architecture whose purpose is to find an intermediate representation based on a combination of data from different modalities. The GMU learns to decide how modalities influence the activation of the unit using multiplicative gates. It was evaluated on a multilabel scenario for genre classification of movies using the plot and the poster. The GMU improved the macro f-score performance of single-modality approaches and outperformed other fusion strategies, including mixture of experts models. Along with this work, the MM-IMDb dataset is released which, to the best of our knowledge, is the largest publicly available multimodal dataset for genre prediction on movies.

Most existing machine learning classifiers are highly vulnerable to adversarial examples.
An adversarial example is a sample of input data which has been modified
very slightly in a way that is intended to cause a machine learning classifier
to misclassify it.
In many cases, these modifications can be so subtle that a human observer does
not even notice the modification at all, yet the classifier still makes a mistake.
Adversarial examples pose security concerns
because they could be used to perform an attack on machine learning systems, even if the adversary has no
access to the underlying model.
Up to now, all previous work has assumed a threat model in which the adversary can
feed data directly into the machine learning classifier.
This is not always the case for systems operating in the physical world,
for example those which are using signals from cameras and other sensors as input.
This paper shows that even in such physical world scenarios, machine learning systems are vulnerable
to adversarial examples.
We demonstrate this by feeding adversarial images obtained from a cell-phone camera
to an ImageNet Inception classifier and measuring the classification accuracy of the system.
We find that a large fraction of adversarial examples are classified incorrectly
even when perceived through the camera.

Our world can be succinctly and compactly described as structured scenes of objects and relations. A typical room, for example, contains salient objects such as tables, chairs and books, and these objects typically relate to each other by virtue of their correlated features, such as position, function and shape. Humans exploit knowledge of objects and their relations for learning a wide spectrum of tasks, and more generally when learning the structure underlying observed data. In this work, we introduce relation networks (RNs) - a general purpose neural network architecture for object-relation reasoning. We show that RNs are capable of learning object relations from scene description data. Furthermore, we show that RNs can act as a bottleneck that induces the factorization of objects from entangled scene description inputs, and from distributed deep representations of scene images provided by a variational autoencoder. The model can also be used in conjunction with differentiable memory mechanisms for implicit relation discovery in one-shot learning tasks. Our results suggest that relation networks are a powerful architecture for solving a variety of problems that require object relation reasoning.
tl;dr: Parameter-sharing for permutation-equivariance and invariance with applications to point-cloud classification.

We introduce a simple permutation equivariant layer for deep learning with set structure. This type of layer, obtained by parameter-sharing, has a simple implementation and linear-time complexity in the size of each set. We use deep permutation-invariant networks to perform point-could classification and MNIST digit summation, where in both cases the output is invariant to permutations of the input. In a semi-supervised setting, where the goal is make predictions for each instance within a set, we demonstrate the usefulness of this type of layer in set-outlier detection as well as semi-supervised learning with clustering side-information.
tl;dr: We show a foveal sampling lattice similar to those observed in biology emerges from our model and task.

We describe a neural attention model with a learnable retinal sampling lattice. The model is trained on a visual search task requiring the classification of an object embedded in a visual scene amidst background distractors using the smallest number of fixations. We explore the tiling properties that emerge in the model's retinal sampling lattice after training. Specifically, we show that this lattice resembles the eccentricity dependent sampling lattice of the primate retina, with a high resolution region in the fovea surrounded by a low resolution periphery. Furthermore, we find conditions where these emergent properties are amplified or eliminated providing clues to their function.
tl;dr: We propose a reinforcement learning based teacher-student framework for filtering training data to boost SGD convergence.

Mini-batch based Stochastic Gradient Descent(SGD) has been widely used to train deep neural networks efficiently. In this paper, we design a general framework to automatically and adaptively select training data for SGD. The framework is based on neural networks and we call it \emph{\textbf{N}eural \textbf{D}ata \textbf{F}ilter} (\textbf{NDF}). In Neural Data Filter, the whole training process of the original neural network is monitored and supervised by a deep reinforcement network, which controls whether to filter some data in sequentially arrived mini-batches so as to maximize future accumulative reward (e.g., validation accuracy). The SGD process accompanied with NDF is able to use less data and converge faster while achieving comparable accuracy as the standard SGD trained on the full dataset. Our experiments show that NDF bootstraps SGD training for different neural network models including Multi Layer Perceptron Network and Recurrent Neural Network trained on various types of tasks including image classification and text understanding.
tl;dr: We propose a novel framework for training vision-based agent for First-Person Shooter (FPS) Game, Doom, using actor-critic model and curriculum training.

In this paper, we propose a novel framework for training vision-based agent for First-Person Shooter (FPS) Game, in particular Doom.
Our framework combines the state-of-the-art reinforcement learning approach (Asynchronous Advantage Actor-Critic (A3C) model) with curriculum learning. Our model is simple in design and only uses game states from the AI side, rather than using opponents' information. On a known map, our agent won 10 out of the 11 attended games and the champion of Track1 in ViZDoom AI Competition 2016 by a large margin, 35\% higher score than the second place.

Recent work has begun exploring neural acoustic word embeddings–fixed dimensional vector representations of arbitrary-length speech segments corresponding to words. Such embeddings are applicable to speech retrieval and recognition tasks, where reasoning about whole words may make it possible to avoid ambiguous sub-word representations. The main idea is to map acoustic sequences to fixed-dimensional vectors such that examples of the same word are mapped to similar vectors, while different-word examples are mapped to very different vectors. In this work we take a multi-view approach to learning acoustic word embeddings, in which we jointly learn to embed acoustic sequences and their corresponding character sequences. We use deep bidirectional LSTM embedding models and multi-view contrastive losses. We study the effect of different loss variants, including fixed-margin and cost-sensitive losses. Our acoustic word embeddings improve over previous approaches for the task of word discrimination. We also present results on other tasks that are enabled by the multi-view approach, including cross-view word discrimination and word similarity.
tl;dr: An interface for editing photos using generative image models.

The increasingly photorealistic sample quality of generative image models suggests their feasibility in applications beyond image generation. We present the Neural Photo Editor, an interface that leverages the power of generative neural networks to make large, semantically coherent changes to existing images. To tackle the challenge of achieving accurate reconstructions without loss of feature quality, we introduce the Introspective Adversarial Network,
a novel hybridization of the VAE and GAN. Our model efficiently captures long-range dependencies through use of a computational block based on weight-shared dilated convolutions, and improves generalization performance with Orthogonal Regularization, a novel weight regularization method. We validate our contributions on CelebA, SVHN, and CIFAR-100, and produce samples and reconstructions with high visual fidelity.
tl;dr: Agent watches another agent at a different camera angle completing the task and learns via raw pixels how to imitate.

Reinforcement learning (RL) makes it possible to train agents capable of achieving
sophisticated goals in complex and uncertain environments. A key difficulty in
reinforcement learning is specifying a reward function for the agent to optimize.
Traditionally, imitation learning in RL has been used to overcome this problem.
Unfortunately, hitherto imitation learning methods tend to require that demonstrations
are supplied in the first-person: the agent is provided with a sequence of
states and a specification of the actions that it should have taken. While powerful,
this kind of imitation learning is limited by the relatively hard problem of collecting
first-person demonstrations. Humans address this problem by learning from
third-person demonstrations: they observe other humans perform tasks, infer the
task, and accomplish the same task themselves.
In this paper, we present a method for unsupervised third-person imitation learning.
Here third-person refers to training an agent to correctly achieve a simple
goal in a simple environment when it is provided a demonstration of a teacher
achieving the same goal but from a different viewpoint; and unsupervised refers
to the fact that the agent receives only these third-person demonstrations, and is
not provided a correspondence between teacher states and student states. Our
methods primary insight is that recent advances from domain confusion can be
utilized to yield domain agnostic features which are crucial during the training
process. To validate our approach, we report successful experiments on learning
from third-person demonstrations in a pointmass domain, a reacher domain, and
inverted pendulum.
tl;dr: We provide theoretical, algorithmical and experimental results concerning the optimization landscape of deep neural networks

The loss surface of deep neural networks has recently attracted interest
in the optimization and machine learning communities as a prime example of
high-dimensional non-convex problem. Some insights were recently gained using spin glass
models and mean-field approximations, but at the expense of strongly simplifying the nonlinear nature of the model.
In this work, we do not make any such approximation and study conditions
on the data distribution and model architecture that prevent the existence
of bad local minima. Our theoretical work quantifies and formalizes two
important folklore facts: (i) the landscape of deep linear networks has a radically different topology
from that of deep half-rectified ones, and (ii) that the energy landscape
in the non-linear case is fundamentally controlled by the interplay between the smoothness of the data distribution and model over-parametrization. Our main theoretical contribution is to prove that half-rectified single layer networks are asymptotically connected, and we provide explicit bounds that reveal the aforementioned interplay.
The conditioning of gradient descent is the next challenge we address.
We study this question through the geometry of the level sets, and we introduce
an algorithm to efficiently estimate the regularity of such sets on large-scale networks.
Our empirical results show that these level sets remain connected throughout
all the learning phase, suggesting a near convex behavior, but they become
exponentially more curvy as the energy level decays, in accordance to what is observed in practice with
very low curvature attractors.

We introduce a design strategy for neural network macro-architecture based on self-similarity. Repeated application of a simple expansion rule generates deep networks whose structural layouts are precisely truncated fractals. These networks contain interacting subpaths of different lengths, but do not include any pass-through or residual connections; every internal signal is transformed by a filter and nonlinearity before being seen by subsequent layers. In experiments, fractal networks match the excellent performance of standard residual networks on both CIFAR and ImageNet classification tasks, thereby demonstrating that residual representations may not be fundamental to the success of extremely deep convolutional neural networks. Rather, the key may be the ability to transition, during training, from effectively shallow to deep. We note similarities with student-teacher behavior and develop drop-path, a natural extension of dropout, to regularize co-adaptation of subpaths in fractal architectures. Such regularization allows extraction of high-performance fixed-depth subnetworks. Additionally, fractal networks exhibit an anytime property: shallow subnetworks provide a quick answer, while deeper subnetworks, with higher latency, provide a more accurate answer.
tl;dr: Training neural network with noisy labels

The availability of large datsets has enabled neural networks to achieve impressive recognition results. However, the presence of inaccurate class labels is known to deteriorate the performance of even the best classifiers in a broad range of classification problems. Noisy labels also tend to be more harmful than noisy attributes. When the observed label is noisy, we can view the correct label as a latent random variable and model the noise processes by a communication channel with unknown parameters. Thus we can apply the EM algorithm to find the parameters of both the network and the noise and to estimate the correct label. In this study we present a neural-network approach that optimizes the same likelihood function as optimized by the EM algorithm. The noise is explicitly modeled by an additional softmax layer that connects the correct labels to the noisy ones. This scheme is then extended to the case where the noisy labels are dependent on the features in addition to the correct labels. Experimental results demonstrate that this approach outperforms previous methods.
tl;dr: We argue for domain-agnostic data augmentation in feature space by applying simple transformations to seq2seq context vectors.

Dataset augmentation, the practice of applying a wide array of domain-specific transformations to synthetically expand a training set, is a standard tool in supervised learning. While effective in tasks such as visual recognition, the set of transformations must be carefully designed, implemented, and tested for every new domain, limiting its re-use and generality. In this paper, we adopt a simpler, domain-agnostic approach to dataset augmentation. We start with existing data points and apply simple transformations such as adding noise, interpolating, or extrapolating between them. Our main insight is to perform the transformation not in input space, but in a learned feature space. A re-kindling of interest in unsupervised representation learning makes this technique timely and more effective. It is a simple proposal, but to-date one that has not been tested empirically. Working in the space of context vectors generated by sequence-to-sequence models, we demonstrate a technique that is effective for both static and sequential data.
tl;dr: We present a novel hierarchical RNN for generating pop music, where the layers and the structure of the hierarchy encode our prior knowledge about how pop music is composed.

We present a novel framework for generating pop music. Our model is a hierarchical Recurrent Neural Network, where the layers and the structure of the hierarchy encode our prior knowledge about how pop music is composed. In particular, the bottom layers generate the melody, while the higher levels produce the drums and chords. We conduct several human studies that show strong preference of our generated music over that produced by the recent method by Google. We additionally show two applications of our framework: neural dancing and karaoke, as well as neural story singing.
tl;dr: We propose Variational Recurrent Adversarial Deep Domain Adaptation approach to capture and transfer temporal latent dependencies in multivariate time-series data

We study the problem of learning domain invariant representations for time series data while transferring the complex temporal latent dependencies between the domains. Our model termed as Variational Recurrent Adversarial Deep Domain Adaptation (VRADA) is built atop a variational recurrent neural network (VRNN) and trains adversarially to capture complex temporal relationships that are domain-invariant. This is (as far as we know) the first to capture and transfer temporal latent dependencies in multivariate time-series data. Through experiments on real-world multivariate healthcare time-series datasets, we empirically demonstrate that learning temporal dependencies helps our model's ability to create domain-invariant representations, allowing our model to outperform current state-of-the-art deep domain adaptation approaches.
tl;dr: A differentiable functional programming language for learning programs from input-output examples.

We discuss a range of modeling choices that arise when constructing an end-to-end differentiable programming language suitable for learning programs from input-output examples. Taking cues from programming languages research, we study the effect of memory allocation schemes, immutable data, type systems, and built-in control-flow structures on the success rate of learning algorithms. We build a range of models leading up to a simple differentiable functional programming language. Our empirical evaluation shows that this language allows to learn far more programs than existing baselines.
tl;dr: We propose a model for evaluating dialogue responses that correlates significantly with human judgement at the utterance-level and system-level.

Automatically evaluating the quality of dialogue responses for unstructured domains is a challenging problem.
Unfortunately, existing automatic evaluation metrics are biased and correlate very poorly with human judgements of response quality (Liu et al., 2016). Yet having an accurate automatic evaluation procedure is crucial for dialogue research, as it allows rapid prototyping and testing of new models with fewer expensive human evaluations. In response to this challenge, we formulate automatic dialogue evaluation as a learning problem. We present an evaluation model (ADEM) that learns to predict human-like scores to input responses, using a new dataset of human response scores. We show that the ADEM model's predictions correlate significantly, and at level much higher than word-overlap metrics such as BLEU, with human judgements at both the utterance and system-level. We also show that ADEM can generalize to evaluating dialogue models unseen during training, an important step for automatic dialogue evaluation.
tl;dr: We wrote a framework to differentiate through physics and show that this makes training deep learned controllers for robotics remarkably fast and straightforward

One of the most important fields in robotics is the optimization of controllers. Currently, robots are often treated as a black box in this optimization process, which is the reason why derivative-free optimization methods such as evolutionary algorithms or reinforcement learning are omnipresent. When gradient-based methods are used, models are kept small or rely on finite difference approximations for the Jacobian. This method quickly grows expensive with increasing numbers of parameters, such as found in deep learning. We propose an implementation of a modern physics engine, which can differentiate control parameters. This engine is implemented for both CPU and GPU. Firstly, this paper shows how such an engine speeds up the optimization process, even for small problems. Furthermore, it explains why this is an alternative approach to deep Q-learning, for using deep learning in robotics. Finally, we argue that this is a big step for deep learning in robotics, as it opens up new possibilities to optimize robots, both in hardware and software.
tl;dr: an efficient analog of the universal approximation theorem for neural networks over the boolean hypercube

The universal approximation theorem for neural networks says that any reasonable function is well-approximated by a two-layer neural network with sigmoid gates but it does not provide good bounds on the number of hidden-layer nodes or the weights. However, robust concepts often have small neural networks in practice. We show an efficient analog of the universal approximation theorem on the boolean hypercube in this context.
We prove that any noise-stable boolean function on n boolean-valued input variables can be well-approximated by a two-layer linear threshold circuit with a small number of hidden-layer nodes and small weights, that depend only on the noise-stability and approximation parameters, and are independent of n. We also give a polynomial time learning algorithm that outputs a small two-layer linear threshold circuit that approximates such a given function. We also show weaker generalizations of this to noise-stable polynomial threshold functions and noise-stable boolean functions in general.

This paper builds off recent work from Kiperwasser & Goldberg (2016) using neural attention in a simple graph-based dependency parser. We use a larger but more thoroughly regularized parser than other recent BiLSTM-based approaches, with
biaffine classifiers to predict arcs and labels. Our parser gets state of the art or near state of the art performance on standard treebanks for six different languages, achieving 95.7% UAS and 94.1% LAS on the most popular English PTB dataset. This makes it the highest-performing graph-based parser on this benchmark—outperforming Kiperwasser & Goldberg (2016) by 1.8% and 2.2%—and comparable to the highest performing transition-based parser (Kuncoro et al., 2016), which achieves 95.8% UAS and 94.6% LAS. We also show which hyperparameter choices had a significant effect on parsing accuracy, allowing us to achieve large gains over other graph-based approaches.
224. Symmetry-Breaking Convergence Analysis of Certain Two-layered Neural Networks with ReLU nonlinearity
tl;dr: In this paper, we use dynamical system to analyze the nonlinear weight dynamics of two-layered bias-free ReLU networks.

In this paper, we use dynamical system to analyze the nonlinear weight dynamics of two-layered bias-free networks in the form of $g(x; w) = \sum_{j=1}^K \sigma(w_j \cdot x)$, where $\sigma(\cdot)$ is ReLU nonlinearity. We assume that the input $x$ follow Gaussian distribution. The network is trained using gradient descent to mimic the output of a teacher network of the same size with fixed parameters $w*$ using $l_2$ loss. We first show that when $K = 1$, the nonlinear dynamics can be written in close form, and converges to $w*$ with at least $(1-\epsilon)/2$ probability, if random weight initializations of proper standard derivation ($\sim 1/\sqrt{d}$) is used, verifying empirical practice. For networks with many ReLU nodes ($K \ge 2$), we apply our close form dynamics and prove that when the teacher parameters $\{w*_j\}_{j=1}^K$ forms orthonormal bases, (1) a symmetric weight initialization yields a convergence to a saddle point and (2) a certain symmetry-breaking weight initialization yields global convergence to $w*$ without local minima. To our knowledge, this is the first proof that shows global convergence in nonlinear neural network without unrealistic assumptions on the independence of ReLU activations. In addition, we also give a concise gradient update formulation for a multilayer ReLU network when it follows a teacher of the same size with $l_2$ loss. Simulations verify our theoretical analysis.
225. Fast Chirplet Transform to Enhance CNN Machine Listening - Validation on Animal calls and Speech
tl;dr: Proposing a chirplet transform in order to regulate the input of deep-CNN and possible extension to chirplet learning for deep learning bioacoustics

The scattering framework offers an optimal hierarchical convolutional decomposition according to its kernels. Convolutional Neural Net (CNN) can be seen asan optimal kernel decomposition, nevertheless it requires large amount of trainingdata to learn its kernels. We propose a trade-off between these two approaches: a Chirplet kernel as an efficient Q constant bioacoustic representation to pretrainCNN. First we motivate Chirplet bioinspired auditory representation. Second we give the first algorithm (and code) of a Fast Chirplet Transform (FCT). Third, we demonstrate the computation efficiency of FCT on large environmental data base: months of Orca recordings, and 1000 Birds species from the LifeClef challenge. Fourth, we validate FCT on the vowels subset of the Speech TIMIT dataset. The results show that FCT accelerates CNN when it pretrains low level layers: it reduces training duration by -28% for birds classification, and by -26% for vowels classification. Scores are also enhanced by FCT pretraining, with a relative gain of +7.8% of Mean Average Precision on birds, and +2.3% of vowel accuracy against raw audio CNN. We conclude on perspectives on tonotopic FCT deep machine listening, and inter-species bioacoustic transfer learning to generalise the representation of animal communication systems.
tl;dr: Extension of Normalization Propagation to the LSTM.

We propose a LSTM parametrization that preserves the means and variances of the hidden states and memory cells across time. While having training benefits similar to Recurrent Batch Normalization and Layer Normalization, it does not need to estimate statistics at each time step, therefore, requiring fewer computations overall. We also investigate the parametrization impact on the gradient flows and present a way of initializing the weights accordingly.
We evaluate our proposal on language modelling and image generative modelling tasks. We empirically show that it performs similarly or better than other recurrent normalization approaches, while being faster to execute.
tl;dr: Real robots learn new tasks from observing a few human demonstrations.

Reward function design and exploration time are arguably the biggest obstacles to the deployment of reinforcement learning (RL) agents in the real world. In many real-world tasks, designing a suitable reward function takes considerable manual engineering and often requires additional and potentially visible sensors to be installed just to measure whether the task has been executed successfully. Furthermore, many interesting tasks consist of multiple steps that must be executed in sequence. Even when the final outcome can be measured, it does not necessarily provide useful feedback on these implicit intermediate steps or sub-goals.
To address these issues, we propose leveraging the abstraction power of intermediate visual representations learned by deep models to quickly infer perceptual reward functions from small numbers of demonstrations. We present a method that is able to identify the key intermediate steps of a task from only a handful of demonstration sequences, and automatically identify the most discriminative features for identifying these steps. This method makes use of the features in a pre-trained deep model, but does not require any explicit sub-goal supervision. The resulting reward functions, which are dense and smooth, can then be used by an RL agent to learn to perform the task in real-world settings. To evaluate the learned reward functions, we present qualitative results on two real-world tasks and a quantitative evaluation against a human-designed reward function. We also demonstrate that our method can be used to learn a complex real-world door opening skill using a real robot, even when the demonstration used for reward learning is provided by a human using their own hand. To our knowledge, these are the first results showing that complex robotic manipulation skills can be learned directly and without supervised labels from a video of a human performing the task.
tl;dr: RL Tuner is a method for refining an LSTM trained on data by using RL to impose desired behaviors, while maintaining good predictive properties learned from data.

The approach of training sequence models using supervised learning and next-step prediction suffers from known failure modes. For example, it is notoriously difficult to ensure multi-step generated sequences have coherent global structure. We propose a novel sequence-learning approach in which we use a pre-trained Recurrent Neural Network (RNN) to supply part of the reward value in a Reinforcement Learning (RL) model. Thus, we can refine a sequence predictor by optimizing for some imposed reward functions, while maintaining good predictive properties learned from data. We propose efficient ways to solve this by augmenting deep Q-learning with a cross-entropy reward and deriving novel off-policy methods for RNNs from KL control. We explore the usefulness of our approach in the context of music generation. An LSTM is trained on a large corpus of songs to predict the next note in a musical sequence. This Note RNN is then refined using our method and rules of music theory. We show that by combining maximum likelihood (ML) and RL in this way, we can not only produce more pleasing melodies, but significantly reduce unwanted behaviors and failure modes of the RNN, while maintaining information learned from data.
tl;dr: We present the learning of analytical equation from data using a new forward network architecture.

In classical machine learning, regression is treated as a black box process of identifying a
suitable function from a hypothesis set without attempting to gain insight into the mechanism connecting inputs and outputs.
In the natural sciences, however, finding an interpretable function for a phenomenon is the prime goal as it allows to understand and generalize results. This paper proposes a novel type of function learning network, called equation learner (EQL), that can learn analytical expressions and is able to extrapolate to unseen domains. It is implemented as an end-to-end differentiable feed-forward network and allows for efficient gradient based training. Due to sparsity regularization concise interpretable expressions can be obtained. Often the true underlying source expression is identified.
tl;dr: We propose a kernel method that combats the curse of dimensionality with an exponential number of virtual training instances efficiently composed from transformed sub-regions of the original ones.

Convolutional neural networks (convnets) have achieved impressive results on recent computer vision benchmarks. While they benefit from multiple layers that encode nonlinear decision boundaries and a degree of translation invariance, training convnets is a lengthy procedure fraught with local optima. Alternatively, a kernel method that incorporates the compositionality and symmetry of convnets could learn similar nonlinear concepts yet with easier training and architecture selection. We propose compositional kernel machines (CKMs), which effectively create an exponential number of virtual training instances by composing transformed sub-regions of the original ones. Despite this, CKM discriminant functions can be computed efficiently using ideas from sum-product networks. The ability to compose virtual instances in this way gives CKMs invariance to translations and other symmetries, and combats the curse of dimensionality. Just as support vector machines (SVMs) provided a compelling alternative to multilayer perceptrons when they were introduced, CKMs could become an attractive approach for object recognition and other vision problems. In this paper we define CKMs, explore their properties, and present promising results on NORB datasets. Experiments show that CKMs can outperform SVMs and be competitive with convnets in a number of dimensions, by learning symmetries and compositional concepts from fewer samples without data augmentation.
tl;dr: Formulating CNN layerwise optimization as an SVM problem

We present a novel layerwise optimization algorithm for the learning objective of Piecewise-Linear Convolutional Neural Networks (PL-CNNs), a large class of convolutional neural networks. Specifically, PL-CNNs employ piecewise linear non-linearities such as the commonly used ReLU and max-pool, and an SVM classifier as the final layer. The key observation of our approach is that the prob- lem corresponding to the parameter estimation of a layer can be formulated as a difference-of-convex (DC) program, which happens to be a latent structured SVM. We optimize the DC program using the concave-convex procedure, which requires us to iteratively solve a structured SVM problem. This allows to design an opti- mization algorithm with an optimal learning rate that does not require any tuning. Using the MNIST, CIFAR and ImageNet data sets, we show that our approach always improves over the state of the art variants of backpropagation and scales to large data and large network settings.

Previous models for video captioning often use the output from a specific layer of a Convolutional Neural Network (CNN) as video representations, preventing them from modeling rich, varying context-dependent semantics in video descriptions. In this paper, we propose a new approach to generating adaptive spatiotemporal representations of videos for a captioning task. For this purpose, novel attention mechanisms with spatiotemporal alignment is employed to adaptively and sequentially focus on different layers of CNN features (levels of feature ``abstraction''), as well as local spatiotemporal regions of the feature maps at each layer. Our approach is evaluated on three benchmark datasets: YouTube2Text, M-VAD and MSR-VTT. Along with visualizing the results and how the model works, these experiments quantitatively demonstrate the effectiveness of the proposed adaptive spatiotemporal feature abstraction for translating videos to sentences with rich semantics.
tl;dr: A neural network that learns an approximation to a function by generating its own regression points

Most machine learning applications using neural networks seek to approximate some function g(x) by minimizing some cost criterion. In the simplest case, if one has access to pairs of the form (x, y) where y = g(x), the problem can be framed as a regression problem. Beyond this family of problems, we find many cases where the unavailability of data pairs makes this approach unfeasible. However, similar to what we find in the reinforcement learning literature, if we have some known properties of the function we are seeking to approximate, there is still hope to frame the problem as a regression problem. In this context, we present an algorithm that approximates the solution to a partial differential equation known as the Hamilton-Jacobi-Isaacs PDE and compare it to current state of the art tools. This PDE, which is found in the fields of control theory and robotics, is of particular importance in safety critical systems where guarantees of performance are a must.

Deep networks are successfully used as classification models yielding state-of-the-art results when trained on a large number of labeled samples. These models, however, are usually much less suited for semi-supervised problems because of their tendency to overfit easily when trained on small amounts of data. In this work we will explore a new training objective that is targeting a semi-supervised regime with only a small subset of labeled data. This criterion is based on a deep metric embedding over distance relations within the set of labeled samples, together with constraints over the embeddings of the unlabeled set. The final learned representations are discriminative in euclidean space, and hence can be used with subsequent nearest-neighbor classification using the labeled samples.
tl;dr: This paper describes the first online structure learning technique for continuous SPNs with Gaussian leaves.

Sum-product networks have recently emerged as an attractive representation due to their dual view as a special type of deep neural network with clear semantics and a special type of probabilistic graphical model for which inference is always tractable. Those properties follow from some conditions (i.e., completeness and decomposability) that must be respected by the structure of the network. As a result, it is not easy to specify a valid sum-product network by hand and therefore structure learning techniques are typically used in practice. This paper describes the first {\em online} structure learning technique for continuous SPNs with Gaussian leaves. We also introduce an accompanying new parameter learning technique.
tl;dr: Combines LSTM and multiplicative RNN architectures; achieves 1.19 bits/character on Hutter prize dataset with dynamic evaluation.

We introduce multiplicative LSTM (mLSTM), a novel recurrent neural network architecture for sequence modelling that combines the long short-term memory (LSTM) and multiplicative recurrent neural network architectures. mLSTM is characterised by its ability to have different recurrent transition functions for each possible input, which we argue makes it more expressive for autoregressive density estimation. We demonstrate empirically that mLSTM outperforms standard LSTM and its deep variants for a range of character level modelling tasks, and that this improvement increases with the complexity of the task. This model achieves a test error of 1.19 bits/character on the last 4 million characters of the Hutter prize dataset when combined with dynamic evaluation.
tl;dr: Combination of differentiable interpreters and neural networks for lifelong learning of a model composed of neural and source code functions

We introduce and develop solutions for the problem of Lifelong Perceptual Programming By Example (LPPBE). The problem is to induce a series of programs that require understanding perceptual data like images or text. LPPBE systems learn from weak supervision (input-output examples) and incrementally construct a shared library of components that grows and improves as more tasks are solved. Methodologically, we extend differentiable interpreters to operate on perceptual data and to share components across tasks. Empirically we show that this leads to a lifelong learning system that transfers knowledge to new tasks more effectively than baselines, and the performance on earlier tasks continues to improve even as the system learns on new, different tasks.
tl;dr: For sparse boolean inputs, Neural Networks operating on very short sketches can provably and empirically represent a large class of functions.

Data-independent methods for dimensionality reduction such as random projections, sketches, and feature hashing have become increasingly popular in recent years. These methods often seek to reduce dimensionality while preserving the hypothesis class, resulting in inherent lower bounds on the size of projected data. For example, preserving linear separability requires $\Omega(1/\gamma^2)$ dimensions, where $\gamma$ is the margin, and in the case of polynomial functions, the number of required dimensions has an exponential dependence on the polynomial degree.
Despite these limitations, we show that the dimensionality can be reduced further while maintaining performance guarantees, using improper learning with a slightly larger hypothesis class. In particular, we show that any sparse polynomial function of a sparse binary vector can be computed from a compact sketch by a single-layer neural network, where the sketch size has a logarithmic dependence on the polynomial degree.
A practical consequence is that networks trained on sketched data are compact, and therefore suitable for settings with memory and power constraints. We empirically show that our approach leads to networks with fewer parameters than related methods such as feature hashing, at equal or better performance.

Recently, the problem of local minima in very high dimensional non-convex optimization has been challenged and the problem of saddle points has been introduced. This paper introduces a dynamic type of normalization that forces the system to escape saddle points. Unlike other saddle point escaping algorithms, second order information is not utilized, and the system can be trained with an arbitrary gradient descent learner. The system drastically improves learning in a range of deep neural networks on various data-sets in comparison to non-CPN neural networks.
tl;dr: We propose a theoretical framework to explain and measure model robustness and harden DNN model against adversarial attacks.

Most machine learning classifiers, including deep neural networks, are vulnerable to adversarial examples. Such inputs are typically generated by adding small but purposeful modifications that lead to incorrect outputs while imperceptible to human eyes. The goal of this paper is not to introduce a single method, but to make theoretical steps toward fully understanding adversarial examples. By using concepts from topology, our theoretical analysis brings forth the key reasons why an adversarial example can fool a classifier ($f_1$) and adds its oracle ($f_2$, like human eyes) in such analysis.
By investigating the topological relationship between two (pseudo)metric spaces corresponding to predictor $f_1$ and oracle $f_2$, we develop necessary and sufficient conditions that can determine if $f_1$ is always robust (strong-robust) against adversarial examples according to $f_2$. Interestingly our theorems indicate that just one unnecessary feature can make $f_1$ not strong-robust, and the right feature representation learning is the key to getting a classifier that is both accurate and strong robust.
tl;dr: Using generated data from a next frame predictor model to make a supervised model generalize better to unseen distributions.

Humans learn a predictive model of the world and use this model to reason about future events and the consequences of actions. In contrast to most machine predictors, we exhibit an impressive ability to generalize to unseen scenarios and reason intelligently in these settings. One important aspect of this ability is physical intuition(Lake et al., 2016). In this work, we explore the potential of unsupervised learning to find features that promote better generalization to settings outside the supervised training distribution. Our task is predicting the stability of towers of square blocks. We demonstrate that an unsupervised model, trained to predict future frames of a video sequence of stable and unstable block configurations, can yield features that support extrapolating stability prediction to blocks configurations outside the training set distribution
tl;dr: Shift Aggregate Extract Networks for learning on social network data

The Shift Aggregate Extract Network SAEN is an architecture for learning representations on social network data.
SAEN decomposes input graphs into hierarchies made of multiple strata of objects.
Vector representations of each object are learnt by applying 'shift', 'aggregate' and 'extract' operations on the vector representations of its parts.
We propose an algorithm for domain compression which takes advantage of symmetries in hierarchical decompositions to reduce the memory usage and obtain significant speedups.
Our method is empirically evaluated on real world social network datasets, outperforming the current state of the art.
243. Perception Updating Networks: On architectural constraints for interpretable video generative models
tl;dr: Decoupled "what" and "where" variational statistical framework and equivalent multi-stream network

We investigate a neural network architecture and statistical framework that models frames in videos using principles inspired by computer graphics pipelines. The proposed model explicitly represents "sprites" or its percepts inferred from maximum likelihood of the scene and infers its movement independently of its content. We impose architectural constraints that forces resulting architecture to behave as a recurrent what-where prediction network.
244. Learning to Draw Samples: With Application to Amortized MLE for Generative Adversarial Learning

We propose a simple algorithm to train stochastic neural networks to draw samples from given target distributions for probabilistic inference. Our method is based on iteratively adjusting the neural network parameters so that the output changes along a Stein variational gradient that maximumly decreases the KL divergence with the target distribution. Our method works for any target distribution specified by their unnormalized density function, and can train any black-box architectures that are differentiable in terms of the parameters we want to adapt. As an application of our method, we propose an amortized MLE algorithm for training deep energy model, where a neural sampler is adaptively trained to approximate the likelihood function. Our method mimics an adversarial game between the deep energy model and the neural sampler, and obtains realistic-looking images competitive with the state-of-the-art results.
tl;dr: Learning multitask deep hierarchical policies with guidance from symbolic policy sketches

We describe a framework for multitask deep reinforcement learning guided by
policy sketches. Sketches annotate each task with a sequence of named subtasks,
providing high-level structural relationships among tasks, but not providing the
detailed guidance required by previous work on learning policy abstractions for
RL (e.g. intermediate rewards, subtask completion signals, or intrinsic motivations).
Our approach associates every subtask with its own modular subpolicy,
and jointly optimizes over full task-specific policies by tying parameters across
shared subpolicies. This optimization is accomplished via a simple decoupled
actor–critic training objective that facilitates learning common behaviors from
dissimilar reward functions. We evaluate the effectiveness of our approach on a
maze navigation game and a 2-D Minecraft-inspired crafting game. Both games
feature extremely sparse rewards that can be obtained only after completing a
number of high-level subgoals (e.g. escaping from a sequence of locked rooms or
collecting and combining various ingredients in the proper order). Experiments
illustrate two main advantages of our approach. First, we outperform standard
baselines that learn task-specific or shared monolithic policies. Second, our
method naturally induces a library of primitive behaviors that can be recombined
to rapidly acquire policies for new tasks.