tl;dr: We provide a fast, principled adversarial training procedure with computational and statistical performance guarantees.

Neural networks are vulnerable to adversarial examples and researchers have proposed many heuristic attack and defense mechanisms. We address this problem through the principled lens of distributionally robust optimization, which guarantees performance under adversarial input perturbations. By considering a Lagrangian penalty formulation of perturbing the underlying data distribution in a Wasserstein ball, we provide a training procedure that augments model parameter updates with worst-case perturbations of training data. For smooth losses, our procedure provably achieves moderate levels of robustness with little computational or statistical cost relative to empirical risk minimization. Furthermore, our statistical guarantees allow us to efficiently certify robustness for the population loss. For imperceptible perturbations, our method matches or outperforms heuristic approaches.
tl;dr: Inference of a mean field game (MFG) model of large population behavior via a synthesis of MFG and Markov decision processes.

We consider the problem of representing collective behavior of large populations and predicting the evolution of a population distribution over a discrete state space. A discrete time mean field game (MFG) is motivated as an interpretable model founded on game theory for understanding the aggregate effect of individual actions and predicting the temporal evolution of population distributions. We achieve a synthesis of MFG and Markov decision processes (MDP) by showing that a special MFG is reducible to an MDP. This enables us to broaden the scope of mean field game theory and infer MFG models of large real-world systems via deep inverse reinforcement learning. Our method learns both the reward function and forward dynamics of an MFG from real data, and we report the first empirical test of a mean field game model of a real-world social media population.

In this paper we investigate image classification with computational resource limits at test time. Two such settings are: 1. anytime classification, where the network’s prediction for a test example is progressively updated, facilitating the output of a prediction at any time; and 2. budgeted batch classification, where a fixed amount of computation is available to classify a set of examples that can be spent unevenly across “easier” and “harder” inputs. In contrast to most prior work, such as the popular Viola and Jones algorithm, our approach is based on convolutional neural networks. We train multiple classifiers with varying resource demands, which we adaptively apply during test time. To maximally re-use computation between the classifiers, we incorporate them as early-exits into a single deep convolutional neural network and inter-connect them with dense connectivity. To facilitate high quality classification early on, we use a two-dimensional multi-scale network architecture that maintains coarse and fine level features all-throughout the network. Experiments on three image-classification tasks demonstrate that our framework substantially improves the existing state-of-the-art in both settings.

It is widely believed that the success of deep convolutional networks is based on progressively discarding uninformative variability about the input with respect to the problem at hand. This is supported empirically by the difficulty of recovering images from their hidden representations, in most commonly used network architectures. In this paper we show via a one-to-one mapping that this loss of information is not a necessary condition to learn representations that generalize well on complicated problems, such as ImageNet. Via a cascade of homeomorphic layers, we build the $i$-RevNet, a network that can be fully inverted up to the final projection onto the classes, i.e. no information is discarded. Building an invertible architecture is difficult, for one, because the local inversion is ill-conditioned, we overcome this by providing an explicit inverse.
An analysis of i-RevNet’s learned representations suggests an alternative explanation for the success of deep networks by a progressive contraction and linear separation with depth. To shed light on the nature of the model learned by the $i$-RevNet we reconstruct linear interpolations between natural image representations.
tl;dr: To our knowledge, this is the first study to show how neural representations of space, including grid-like cells and border cells as observed in the brain, could emerge from training a recurrent neural network to perform navigation tasks.

Decades of research on the neural code underlying spatial navigation have revealed a diverse set of neural response properties. The Entorhinal Cortex (EC) of the mammalian brain contains a rich set of spatial correlates, including grid cells which encode space using tessellating patterns. However, the mechanisms and functional significance of these spatial representations remain largely mysterious. As a new way to understand these neural representations, we trained recurrent neural networks (RNNs) to perform navigation tasks in 2D arenas based on velocity inputs. Surprisingly, we find that grid-like spatial response patterns emerge in trained networks, along with units that exhibit other spatial correlates, including border cells and band-like cells. All these different functional types of neurons have been observed experimentally. The order of the emergence of grid-like and border cells is also consistent with observations from developmental studies. Together, our results suggest that grid cells, border cells and others as observed in EC may be a natural solution for representing space efficiently given the predominant recurrent connections in the neural circuits.
tl;dr: We investigate the convergence of popular optimization algorithms like Adam , RMSProp and propose new variants of these methods which provably converge to optimal solution in convex settings.

Several recently proposed stochastic optimization methods that have been successfully used in training deep networks such as RMSProp, Adam, Adadelta, Nadam are based on using gradient updates scaled by square roots of exponential moving averages of squared past gradients. In many applications, e.g. learning with large output spaces, it has been empirically observed that these algorithms fail to converge to an optimal solution (or a critical point in nonconvex settings). We show that one cause for such failures is the exponential moving average used in the algorithms. We provide an explicit example of a simple convex optimization setting where Adam does not converge to the optimal solution, and describe the precise problems with the previous analysis of Adam algorithm. Our analysis suggests that the convergence issues can be fixed by endowing such algorithms with ``long-term memory'' of past gradients, and propose new variants of the Adam algorithm which not only fix the convergence issues but often also lead to improved empirical performance.
tl;dr: An end-to-end trained deep neural network that leverages Gaussian Mixture Modeling to perform density estimation and unsupervised anomaly detection in a low-dimensional space learned by deep autoencoder.

Unsupervised anomaly detection on multi- or high-dimensional data is of great importance in both fundamental machine learning research and industrial applications, for which density estimation lies at the core. Although previous approaches based on dimensionality reduction followed by density estimation have made fruitful progress, they mainly suffer from decoupled model learning with inconsistent optimization goals and incapability of preserving essential information in the low-dimensional space. In this paper, we present a Deep Autoencoding Gaussian Mixture Model (DAGMM) for unsupervised anomaly detection. Our model utilizes a deep autoencoder to generate a low-dimensional representation and reconstruction error for each input data point, which is further fed into a Gaussian Mixture Model (GMM). Instead of using decoupled two-stage training and the standard Expectation-Maximization (EM) algorithm, DAGMM jointly optimizes the parameters of the deep autoencoder and the mixture model simultaneously in an end-to-end fashion, leveraging a separate estimation network to facilitate the parameter learning of the mixture model. The joint optimization, which well balances autoencoding reconstruction, density estimation of latent representation, and regularization, helps the autoencoder escape from less attractive local optima and further reduce reconstruction errors, avoiding the need of pre-training. Experimental results on several public benchmark datasets show that, DAGMM significantly outperforms state-of-the-art anomaly detection techniques, and achieves up to 14% improvement based on the standard F1 score.

Ability to continuously learn and adapt from limited experience in nonstationary environments is an important milestone on the path towards general intelligence. In this paper, we cast the problem of continuous adaptation into the learning-to-learn framework. We develop a simple gradient-based meta-learning algorithm suitable for adaptation in dynamically changing and adversarial scenarios. Additionally, we design a new multi-agent competitive environment, RoboSumo, and define iterated adaptation games for testing various aspects of continuous adaptation. We demonstrate that meta-learning enables significantly more efficient adaptation than reactive baselines in the few-shot regime. Our experiments with a population of agents that learn and compete suggest that meta-learners are the fittest.
tl;dr: We introduce the notion of mixed tensor decompositions, and use it to prove that interconnecting dilated convolutional networks boosts their expressive power.

The driving force behind deep networks is their ability to compactly represent rich classes of functions. The primary notion for formally reasoning about this phenomenon is expressive efficiency, which refers to a situation where one network must grow unfeasibly large in order to replicate functions of another. To date, expressive efficiency analyses focused on the architectural feature of depth, showing that deep networks are representationally superior to shallow ones. In this paper we study the expressive efficiency brought forth by connectivity, motivated by the observation that modern networks interconnect their layers in elaborate ways. We focus on dilated convolutional networks, a family of deep models delivering state of the art performance in sequence processing tasks. By introducing and analyzing the concept of mixed tensor decompositions, we prove that interconnecting dilated convolutional networks can lead to expressive efficiency. In particular, we show that even a single connection between intermediate layers can already lead to an almost quadratic gap, which in large-scale settings typically makes the difference between a model that is practical and one that is not. Empirical evaluation demonstrates how the expressive efficiency of connectivity, similarly to that of depth, translates into gains in accuracy. This leads us to believe that expressive efficiency may serve a key role in developing new tools for deep network design.
tl;dr: Proves that gating mechanisms provide invariance to time transformations. Introduces and tests a new initialization for LSTMs from this insight.

Successful recurrent models such as long short-term memories (LSTMs) and gated recurrent units (GRUs) use \emph{ad hoc} gating mechanisms. Empirically these models have been found to improve the learning of medium to long term temporal dependencies and to help with vanishing gradient issues.
We prove that learnable gates in a recurrent model formally provide \emph{quasi-invariance to general time transformations} in the input data. We recover part of the LSTM architecture from a simple axiomatic approach.
This result leads to a new way of initializing gate biases in LSTMs and GRUs. Experimentally, this new \emph{chrono initialization} is shown to greatly improve learning of long term dependencies, with minimal implementation effort.
11. Spherical CNNs
tl;dr: We introduce Spherical CNNs, a convolutional network for spherical signals, and apply it to 3D model recognition and molecular energy regression.

Convolutional Neural Networks (CNNs) have become the method of choice for learning problems involving 2D planar images. However, a number of problems of recent interest have created a demand for models that can analyze spherical images. Examples include omnidirectional vision for drones, robots, and autonomous cars, molecular regression problems, and global weather and climate modelling. A naive application of convolutional networks to a planar projection of the spherical signal is destined to fail, because the space-varying distortions introduced by such a projection will make translational weight sharing ineffective.
In this paper we introduce the building blocks for constructing spherical CNNs. We propose a definition for the spherical cross-correlation that is both expressive and rotation-equivariant. The spherical correlation satisfies a generalized Fourier theorem, which allows us to compute it efficiently using a generalized (non-commutative) Fast Fourier Transform (FFT) algorithm. We demonstrate the computational efficiency, numerical accuracy, and effectiveness of spherical CNNs applied to 3D model recognition and atomization energy regression.
tl;dr: Programs have structure that can be represented as graphs, and graph neural networks can learn to find bugs on such graphs

Learning tasks on source code (i.e., formal languages) have been considered recently, but most work has tried to transfer natural language methods and does not capitalize on the unique opportunities offered by code's known syntax. For example, long-range dependencies induced by using the same variable or function in distant locations are often not considered. We propose to use graphs to represent both the syntactic and semantic structure of code and use graph-based deep learning methods to learn to reason over program structures.
In this work, we present how to construct graphs from source code and how to scale Gated Graph Neural Networks training to such large graphs. We evaluate our method on two tasks: VarNaming, in which a network attempts to predict the name of a variable given its usage, and VarMisuse, in which the network learns to reason about selecting the correct variable that should be used at a given program location. Our comparison to methods that use less structured program representations shows the advantages of modeling known structure, and suggests that our models learn to infer meaningful names and to solve the VarMisuse task in many cases. Additionally, our testing showed that VarMisuse identifies a number of bugs in mature open-source projects.
tl;dr: We propose a new auto-encoder based on the Wasserstein distance, which improves on the sampling properties of VAE.

We propose the Wasserstein Auto-Encoder (WAE)---a new algorithm for building a generative model of the data distribution. WAE minimizes a penalized form of the Wasserstein distance between the model distribution and the target distribution, which leads to a different regularizer than the one used by the Variational Auto-Encoder (VAE).
This regularizer encourages the encoded training distribution to match the prior. We compare our algorithm with several other techniques and show that it is a generalization of adversarial auto-encoders (AAE). Our experiments show that WAE shares many of the properties of VAEs (stable training, encoder-decoder architecture, nice latent manifold structure) while generating samples of better quality.
tl;dr: We prove randomly initialized (stochastic) gradient descent learns a convolutional filter in polynomial time.

We analyze the convergence of (stochastic) gradient descent algorithm for learning a convolutional filter with Rectified Linear Unit (ReLU) activation function. Our analysis does not rely on any specific form of the input distribution and our proofs only use the definition of ReLU, in contrast with previous works that are restricted to standard Gaussian input. We show that (stochastic) gradient descent with random initialization can learn the convolutional filter in polynomial time and the convergence rate depends on the smoothness of the input distribution and the closeness of patches. To the best of our knowledge, this is the first recovery guarantee of gradient-based algorithms for convolutional filter on non-Gaussian input distributions. Our theory also justifies the two-stage learning rate strategy in deep neural networks. While our focus is theoretical, we also present experiments that justify our theoretical findings.
tl;dr: Agents can learn to imitate solely visual demonstrations (without actions) at test time after learning from their own experience without any form of supervision at training time.

The current dominant paradigm for imitation learning relies on strong supervision of expert actions to learn both 'what' and 'how' to imitate. We pursue an alternative paradigm wherein an agent first explores the world without any expert supervision and then distills its experience into a goal-conditioned skill policy with a novel forward consistency loss. In our framework, the role of the expert is only to communicate the goals (i.e., what to imitate) during inference. The learned policy is then employed to mimic the expert (i.e., how to imitate) after seeing just a sequence of images demonstrating the desired task. Our method is 'zero-shot' in the sense that the agent never has access to expert actions during training or for the task demonstration at inference. We evaluate our zero-shot imitator in two real-world settings: complex rope manipulation with a Baxter robot and navigation in previously unseen office environments with a TurtleBot. Through further experiments in VizDoom simulation, we provide evidence that better mechanisms for exploration lead to learning a more capable policy which in turn improves end task performance. Videos, models, and more details are available at https://pathak22.github.io/zeroshot-imitation/.
tl;dr: We propose a new recurrent memory architecture that can track common sense state changes of entities by simulating the causal effects of actions.

Understanding procedural language requires anticipating the causal effects of actions, even when they are not explicitly stated. In this work, we introduce Neural Process Networks to understand procedural text through (neural) simulation of action dynamics. Our model complements existing memory architectures with dynamic entity tracking by explicitly modeling actions as state transformers. The model updates the states of the entities by executing learned action operators. Empirical results demonstrate that our proposed model can reason about the unstated causal effects of actions, allowing it to provide more accurate contextual information for understanding and generating procedural text, all while offering more interpretable internal representations than existing alternatives.
tl;dr: We propose a new approach for generating adversarial examples based on spatial transformation, which produces perceptually realistic examples compared to existing attacks.

Recent studies show that widely used Deep neural networks (DNNs) are vulnerable to the carefully crafted adversarial examples.
Many advanced algorithms have been proposed to generate adversarial examples by leveraging the L_p distance for penalizing perturbations.
Different defense methods have also been explored to defend against such adversarial attacks.
While the effectiveness of L_p distance as a metric of perceptual quality remains an active research area, in this paper we will instead focus on a different type of perturbation, namely spatial transformation, as opposed to manipulating the pixel values directly as in prior works.
Perturbations generated through spatial transformation could result in large L_p distance measures, but our extensive experiments show that such spatially transformed adversarial examples are perceptually realistic and more difficult to defend against with existing defense systems. This potentially provides a new direction in adversarial example generation and the design of corresponding defenses.
We visualize the spatial transformation based perturbation for different examples and show that our technique
can produce realistic adversarial examples with smooth image deformation.
Finally, we visualize the attention of deep networks with different types of adversarial examples to better understand how these examples are interpreted.
tl;dr: We propose a novel weight normalization technique called spectral normalization to stabilize the training of the discriminator of GANs.

One of the challenges in the study of generative adversarial networks is the instability of its training.
In this paper, we propose a novel weight normalization technique called spectral normalization to stabilize the training of the discriminator.
Our new normalization technique is computationally light and easy to incorporate into existing implementations.
We tested the efficacy of spectral normalization on CIFAR10, STL-10, and ILSVRC2012 dataset, and we experimentally confirmed that spectrally normalized GANs (SN-GANs) is capable of generating images of better or equal quality relative to the previous training stabilization techniques.
tl;dr: We show that SGD learns two-layer over-parameterized neural networks with Leaky ReLU activations that provably generalize on linearly separable data.

Neural networks exhibit good generalization behavior in the
over-parameterized regime, where the number of network parameters
exceeds the number of observations. Nonetheless,
current generalization bounds for neural networks fail to explain this
phenomenon. In an attempt to bridge this gap, we study the problem of
learning a two-layer over-parameterized neural network, when the data is generated by a linearly separable function. In the case where the network has Leaky
ReLU activations, we provide both optimization and generalization guarantees for over-parameterized networks.
Specifically, we prove convergence rates of SGD to a global
minimum and provide generalization guarantees for this global minimum
that are independent of the network size.
Therefore, our result clearly shows that the use of SGD for optimization both finds a global minimum, and avoids overfitting despite the high capacity of the model. This is the first theoretical demonstration that SGD can avoid overfitting, when learning over-specified neural network classifiers.
tl;dr: SOTA on unsupervised domain adaptation by leveraging the cluster assumption.

Domain adaptation refers to the problem of leveraging labeled data in a source domain to learn an accurate model in a target domain where labels are scarce or unavailable. A recent approach for finding a common representation of the two domains is via domain adversarial training (Ganin & Lempitsky, 2015), which attempts to induce a feature extractor that matches the source and target feature distributions in some feature space. However, domain adversarial training faces two critical limitations: 1) if the feature extraction function has high-capacity, then feature distribution matching is a weak constraint, 2) in non-conservative domain adaptation (where no single classifier can perform well in both the source and target domains), training the model to do well on the source domain hurts performance on the target domain. In this paper, we address these issues through the lens of the cluster assumption, i.e., decision boundaries should not cross high-density data regions. We propose two novel and related models: 1) the Virtual Adversarial Domain Adaptation (VADA) model, which combines domain adversarial training with a penalty term that punishes the violation the cluster assumption; 2) the Decision-boundary Iterative Refinement Training with a Teacher (DIRT-T) model, which takes the VADA model as initialization and employs natural gradient steps to further minimize the cluster assumption violation. Extensive empirical results demonstrate that the combination of these two models significantly improve the state-of-the-art performance on the digit, traffic sign, and Wi-Fi recognition domain adaptation benchmarks.

This work details CipherGAN, an architecture inspired by CycleGAN used for inferring the underlying cipher mapping given banks of unpaired ciphertext and plaintext. We demonstrate that CipherGAN is capable of cracking language data enciphered using shift and Vigenere ciphers to a high degree of fidelity and for vocabularies much larger than previously achieved. We present how CycleGAN can be made compatible with discrete data and train in a stable way. We then prove that the technique used in CipherGAN avoids the common problem of uninformative discrimination associated with GANs applied to discrete data.
tl;dr: We propose a new unsupervised machine translation model that can learn without using parallel corpora; experimental results show impressive performance on multiple corpora and pairs of languages.

Machine translation has recently achieved impressive performance thanks to recent advances in deep learning and the availability of large-scale parallel corpora. There have been numerous attempts to extend these successes to low-resource language pairs, yet requiring tens of thousands of parallel sentences. In this work, we take this research direction to the extreme and investigate whether it is possible to learn to translate even without any parallel data. We propose a model that takes sentences from monolingual corpora in two different languages and maps them into the same latent space. By learning to reconstruct in both languages from this shared feature space, the model effectively learns to translate without using any labeled data. We demonstrate our model on two widely used datasets and two language pairs, reporting BLEU scores of 32.8 and 15.1 on the Multi30k and WMT English-French datasets, without using even a single parallel sentence at training time.

We formulate language modeling as a matrix factorization problem, and show that the expressiveness of Softmax-based models (including the majority of neural language models) is limited by a Softmax bottleneck. Given that natural language is highly context-dependent, this further implies that in practice Softmax with distributed word embeddings does not have enough capacity to model natural language. We propose a simple and effective method to address this issue, and improve the state-of-the-art perplexities on Penn Treebank and WikiText-2 to 47.69 and 40.68 respectively. The proposed method also excels on the large-scale 1B Word dataset, outperforming the baseline by over 5.6 points in perplexity.
tl;dr: Degenerate manifolds arising from the non-identifiability of the model slow down learning in deep networks; skip connections help by breaking degeneracies.

Skip connections made the training of very deep networks possible and have become an indispensable component in a variety of neural architectures. A completely satisfactory explanation for their success remains elusive. Here, we present a novel explanation for the benefits of skip connections in training very deep networks. The difficulty of training deep networks is partly due to the singularities caused by the non-identifiability of the model. Several such singularities have been identified in previous works: (i) overlap singularities caused by the permutation symmetry of nodes in a given layer, (ii) elimination singularities corresponding to the elimination, i.e. consistent deactivation, of nodes, (iii) singularities generated by the linear dependence of the nodes. These singularities cause degenerate manifolds in the loss landscape that slow down learning. We argue that skip connections eliminate these singularities by breaking the permutation symmetry of nodes, by reducing the possibility of node elimination and by making the nodes less linearly dependent. Moreover, for typical initializations, skip connections move the network away from the "ghosts" of these singularities and sculpt the landscape around them to alleviate the learning slow-down. These hypotheses are supported by evidence from simplified models, as well as from experiments with deep networks trained on real-world datasets.
tl;dr: In this paper, We propose a novel neural language model, called the Parsing-Reading-Predict Networks (PRPN), that can simultaneously induce the syntactic structure from unannotated sentences and leverage the inferred structure to learn a better language model.

We propose a neural language model capable of unsupervised syntactic structure induction. The model leverages the structure information to form better semantic representations and better language modeling. Standard recurrent neural networks are limited by their structure and fail to efficiently use syntactic information. On the other hand, tree-structured recursive networks usually require additional structural supervision at the cost of human expert annotation. In this paper, We propose a novel neural language model, called the Parsing-Reading-Predict Networks (PRPN), that can simultaneously induce the syntactic structure from unannotated sentences and leverage the inferred structure to learn a better language model. In our model, the gradient can be directly back-propagated from the language model loss into the neural parsing network. Experiments show that the proposed model can discover the underlying syntactic structure and achieve state-of-the-art performance on word/character-level language model tasks.

Contrary to most natural language processing research, which makes use of static datasets, humans learn language interactively, grounded in an environment. In this work we propose an interactive learning procedure called Mechanical Turker Descent (MTD) that trains agents to execute natural language commands grounded in a fantasy text adventure game. In MTD, Turkers compete to train better agents in the short term, and collaborate by sharing their agents' skills in the long term. This results in a gamified, engaging experience for the Turkers and a better quality teaching signal for the agents compared to static datasets, as the Turkers naturally adapt the training data to the agent's abilities.

A critical component to enabling intelligent reasoning in partially observable environments is memory. Despite this importance, Deep Reinforcement Learning (DRL) agents have so far used relatively simple memory architectures, with the main methods to overcome partial observability being either a temporal convolution over the past k frames or an LSTM layer. More recent work (Oh et al., 2016) has went beyond these architectures by using memory networks which can allow more sophisticated addressing schemes over the past k frames. But even these architectures are unsatisfactory due to the reason that they are limited to only remembering information from the last k frames. In this paper, we develop a memory system with an adaptable write operator that is customized to the sorts of 3D environments that DRL agents typically interact with. This architecture, called the Neural Map, uses a spatially structured 2D memory image to learn to store arbitrary information about the environment over long time lags. We demonstrate empirically that the Neural Map surpasses previous DRL memories on a set of challenging 2D and 3D maze environments and show that it is capable of generalizing to environments that were not seen during training.
tl;dr: We generate Wikipedia articles abstractively conditioned on source document text.

We show that generating English Wikipedia articles can be approached as a multi-
document summarization of source documents. We use extractive summarization
to coarsely identify salient information and a neural abstractive model to generate
the article. For the abstractive model, we introduce a decoder-only architecture
that can scalably attend to very long sequences, much longer than typical encoder-
decoder architectures used in sequence transduction. We show that this model can
generate fluent, coherent multi-sentence paragraphs and even whole Wikipedia
articles. When given reference documents, we show it can extract relevant factual
information as reflected in perplexity, ROUGE scores and human evaluations.
tl;dr: We show that knowledge transfer techniques can improve the accuracy of low precision networks and set new state-of-the-art accuracy for ternary and 4-bits precision.

Deep learning networks have achieved state-of-the-art accuracies on computer vision workloads like image classification and object detection. The performant systems, however, typically involve big models with numerous parameters. Once trained, a challenging aspect for such top performing models is deployment on resource constrained inference systems -- the models (often deep networks or wide networks or both) are compute and memory intensive. Low precision numerics and model compression using knowledge distillation are popular techniques to lower both the compute requirements and memory footprint of these deployed models. In this paper, we study the combination of these two techniques and show that the performance of low precision networks can be significantly improved by using knowledge distillation techniques. We call our approach Apprentice and show state-of-the-art accuracies using ternary precision and 4-bit precision for many variants of ResNet architecture on ImageNet dataset. We study three schemes in which one can apply knowledge distillation techniques to various stages of the train-and-deploy pipeline.
tl;dr: We give a method for generating type-safe programs in a Java-like language, given a small amount of syntactic information about the desired code.

We study the problem of generating source code in a strongly typed,
Java-like programming language, given a label (for example a set of
API calls or types) carrying a small amount of information about the
code that is desired. The generated programs are expected to respect a
`"realistic" relationship between programs and labels, as exemplified
by a corpus of labeled programs available during training.
Two challenges in such *conditional program generation* are that
the generated programs must satisfy a rich set of syntactic and
semantic constraints, and that source code contains many low-level
features that impede learning. We address these problems by training
a neural generator not on code but on *program sketches*, or
models of program syntax that abstract out names and operations that
do not generalize across programs. During generation, we infer a
posterior distribution over sketches, then concretize samples from
this distribution into type-safe programs using combinatorial
techniques. We implement our ideas in a system for generating
API-heavy Java code, and show that it can often predict the entire
body of a method given just a few API calls or data types that appear
in the method.
tl;dr: Prune and ReLU in Winograd domain for efficient convolutional neural network

Convolutional Neural Networks (CNNs) are computationally intensive, which limits their application on mobile devices. Their energy is dominated by the number of multiplies needed to perform the convolutions. Winograd’s minimal filtering algorithm (Lavin, 2015) and network pruning (Han et al., 2015) can reduce the operation count, but these two methods cannot be straightforwardly combined — applying the Winograd transform fills in the sparsity in both the weights and the activations. We propose two modifications to Winograd-based CNNs to enable these methods to exploit sparsity. First, we move the ReLU operation into the Winograd domain to increase the sparsity of the transformed activations. Second, we prune the weights in the Winograd domain to exploit static weight sparsity. For models on CIFAR-10, CIFAR-100 and ImageNet datasets, our method reduces the number of multiplications by 10.4x, 6.8x and 10.8x respectively with loss of accuracy less than 0.1%, outperforming previous baselines by 2.0x-3.0x. We also show that moving ReLU to the Winograd domain allows more aggressive pruning.
tl;dr: CharNMT is brittle

Character-based neural machine translation (NMT) models alleviate out-of-vocabulary issues, learn morphology, and move us closer to completely end-to-end translation systems. Unfortunately, they are also very brittle and easily falter when presented with noisy data. In this paper, we confront NMT models with synthetic and natural sources of noise. We find that state-of-the-art models fail to translate even moderately noisy texts that humans have no trouble comprehending. We explore two approaches to increase model robustness: structure-invariant word representations and robust training on noisy texts. We find that a model based on a character convolutional neural network is able to simultaneously learn representations robust to multiple kinds of noise.
tl;dr: The paper analyzes the optimization landscape of one-hidden-layer neural nets and designs a new objective that provably has no spurious local minimum.

We consider the problem of learning a one-hidden-layer neural network: we assume the input x is from Gaussian distribution and the label $y = a \sigma(Bx) + \xi$, where a is a nonnegative vector and $B$ is a full-rank weight matrix, and $\xi$ is a noise vector. We first give an analytic formula for the population risk of the standard squared loss and demonstrate that it implicitly attempts to decompose a sequence of low-rank tensors simultaneously.
Inspired by the formula, we design a non-convex objective function $G$ whose landscape is guaranteed to have the following properties:
1. All local minima of $G$ are also global minima.
2. All global minima of $G$ correspond to the ground truth parameters.
3. The value and gradient of $G$ can be estimated using samples.
With these properties, stochastic gradient descent on $G$ provably converges to the global minimum and learn the ground-truth parameters. We also prove finite sample complexity results and validate the results by simulations.
tl;dr: We learn feature maps invariant to translation, and equivariant to rotation and scale.

Convolutional neural networks (CNNs) are inherently equivariant to translation. Efforts to embed other forms of equivariance have concentrated solely on rotation. We expand the notion of equivariance in CNNs through the Polar Transformer Network (PTN). PTN combines ideas from the Spatial Transformer Network (STN) and canonical coordinate representations. The result is a network invariant to translation and equivariant to both rotation and scale. PTN is trained end-to-end and composed of three distinct stages: a polar origin predictor, the newly introduced polar transformer module and a classifier. PTN achieves state-of-the-art on rotated MNIST and the newly introduced SIM2MNIST dataset, an MNIST variation obtained by adding clutter and perturbing digits with translation, rotation and scaling. The ideas of PTN are extensible to 3D which we demonstrate through the Cylindrical Transformer Network.

We present a generalization bound for feedforward neural networks in terms of the product of the spectral norm of the layers and the Frobenius norm of the weights. The generalization bound is derived using a PAC-Bayes analysis.
tl;dr: How to learn GANs from noisy, distorted, partial observations

Generative models provide a way to model structure in complex distributions and have been shown to be useful for many tasks of practical interest. However, current techniques for training generative models require access to fully-observed samples. In many settings, it is expensive or even impossible to obtain fully-observed samples, but economical to obtain partial, noisy observations. We consider the task of learning an implicit generative model given only lossy measurements of samples from the distribution of interest. We show that the true underlying distribution can be provably recovered even in the presence of per-sample information loss for a class of measurement models. Based on this, we propose a new method of training Generative Adversarial Networks (GANs) which we call AmbientGAN. On three benchmark datasets, and for various measurement models, we demonstrate substantial qualitative and quantitative improvements. Generative models trained with our method can obtain $2$-$4$x higher inception scores than the baselines.
tl;dr: We show how we can use the successor representation to discover eigenoptions in stochastic domains, from raw pixels. Eigenoptions are options learned to navigate the latent dimensions of a learned representation.

Options in reinforcement learning allow agents to hierarchically decompose a task into subtasks, having the potential to speed up learning and planning. However, autonomously learning effective sets of options is still a major challenge in the field. In this paper we focus on the recently introduced idea of using representation learning methods to guide the option discovery process. Specifically, we look at eigenoptions, options obtained from representations that encode diffusive information flow in the environment. We extend the existing algorithms for eigenoption discovery to settings with stochastic transitions and in which handcrafted features are not available. We propose an algorithm that discovers eigenoptions while learning non-linear state representations from raw pixels. It exploits recent successes in the deep reinforcement learning literature and the equivalence between proto-value functions and the successor representation. We use traditional tabular domains to provide intuition about our approach and Atari 2600 games to demonstrate its potential.
tl;dr: We propose a neural module approach to continual learning using a unified visual environment with a large action space.

A core aspect of human intelligence is the ability to learn new tasks quickly and switch between them flexibly. Here, we describe a modular continual reinforcement learning paradigm inspired by these abilities. We first introduce a visual interaction environment that allows many types of tasks to be unified in a single framework. We then describe a reward map prediction scheme that learns new tasks robustly in the very large state and action spaces required by such an environment. We investigate how properties of module architecture influence efficiency of task learning, showing that a module motif incorporating specific design principles (e.g. early bottlenecks, low-order polynomial nonlinearities, and symmetry) significantly outperforms more standard neural network motifs, needing fewer training examples and fewer neurons to achieve high levels of performance. Finally, we present a meta-controller architecture for task switching based on a dynamic neural voting scheme, which allows new modules to use information learned from previously-seen tasks to substantially improve their own learning efficiency.
tl;dr: We propose and verify the effectiveness of learning to teach, a new framework to automatically guide machine learning process.

Teaching plays a very important role in our society, by spreading human knowledge and educating our next generations. A good teacher will select appropriate teaching materials, impact suitable methodologies, and set up targeted examinations, according to the learning behaviors of the students. In the field of artificial intelligence, however, one has not fully explored the role of teaching, and pays most attention to machine \emph{learning}. In this paper, we argue that equal attention, if not more, should be paid to teaching, and furthermore, an optimization framework (instead of heuristics) should be used to obtain good teaching strategies. We call this approach ``learning to teach''. In the approach, two intelligent agents interact with each other: a student model (which corresponds to the learner in traditional machine learning algorithms), and a teacher model (which determines the appropriate data, loss function, and hypothesis space to facilitate the training of the student model). The teacher model leverages the feedback from the student model to optimize its own teaching strategies by means of reinforcement learning, so as to achieve teacher-student co-evolution. To demonstrate the practical value of our proposed approach, we take the training of deep neural networks (DNN) as an example, and show that by using the learning to teach techniques, we are able to use much less training data and fewer iterations to achieve almost the same accuracy for different kinds of DNN models (e.g., multi-layer perceptron, convolutional neural networks and recurrent neural networks) under various machine learning tasks (e.g., image classification and text understanding).
tl;dr: We propose a new quantization method and apply it to quantize RNNs for both compression and acceleration

Recurrent neural networks have achieved excellent performance in many applications. However, on portable devices with limited resources, the models are often too large to deploy. For applications on the server with large scale concurrent requests, the latency during inference can also be very critical for costly computing resources. In this work, we address these problems by quantizing the network, both weights and activations, into multiple binary codes {-1,+1}. We formulate the quantization as an optimization problem. Under the key observation that once the quantization coefficients are fixed the binary codes can be derived efficiently by binary search tree, alternating minimization is then applied. We test the quantization for two well-known RNNs, i.e., long short term memory (LSTM) and gated recurrent unit (GRU), on the language models. Compared with the full-precision counter part, by 2-bit quantization we can achieve ~16x memory saving and ~6x real inference acceleration on CPUs, with only a reasonable loss in the accuracy. By 3-bit quantization, we can achieve almost no loss in the accuracy or even surpass the original model, with ~10.5x memory saving and ~3x real inference acceleration. Both results beat the exiting quantization works with large margins. We extend our alternating quantization to image classification tasks. In both RNNs and feedforward neural networks, the method also achieves excellent performance.
tl;dr: Existing momentum/acceleration schemes such as heavy ball method and Nesterov's acceleration employed with stochastic gradients do not improve over vanilla stochastic gradient descent, especially when employed with small batch sizes.

Momentum based stochastic gradient methods such as heavy ball (HB) and Nesterov's accelerated gradient descent (NAG) method are widely used in practice for training deep networks and other supervised learning models, as they often provide significant improvements over stochastic gradient descent (SGD). Rigorously speaking, fast gradient methods have provable improvements over gradient descent only for the deterministic case, where the gradients are exact. In the stochastic case, the popular explanations for their wide applicability is that when these fast gradient methods are applied in the stochastic case, they partially mimic their exact gradient counterparts, resulting in some practical gain. This work provides a counterpoint to this belief by proving that there exist simple problem instances where these methods cannot outperform SGD despite the best setting of its parameters. These negative problem instances are, in an informal sense, generic; they do not look like carefully constructed pathological instances. These results suggest (along with empirical evidence) that HB or NAG's practical performance gains are a by-product of minibatching.
Furthermore, this work provides a viable (and provable) alternative, which, on the same set of problem instances, significantly improves over HB, NAG, and SGD's performance. This algorithm, referred to as Accelerated Stochastic Gradient Descent (ASGD), is a simple to implement stochastic algorithm, based on a relatively less popular variant of Nesterov's Acceleration. Extensive empirical results in this paper show that ASGD has performance gains over HB, NAG, and SGD. The code for implementing the ASGD Algorithm can be found at https://github.com/rahulkidambi/AccSGD.
tl;dr: We introduce causal implicit generative models, which can sample from conditional and interventional distributions and also propose two new conditional GANs which we use for training them.

We introduce causal implicit generative models (CiGMs): models that allow sampling from not only the true observational but also the true interventional distributions. We show that adversarial training can be used to learn a CiGM, if the generator architecture is structured based on a given causal graph. We consider the application of conditional and interventional sampling of face images with binary feature labels, such as mustache, young. We preserve the dependency structure between the labels with a given causal graph. We devise a two-stage procedure for learning a CiGM over the labels and the image. First we train a CiGM over the binary labels using a Wasserstein GAN where the generator neural network is consistent with the causal graph between the labels. Later, we combine this with a conditional GAN to generate images conditioned on the binary labels. We propose two new conditional GAN architectures: CausalGAN and CausalBEGAN. We show that the optimal generator of the CausalGAN, given the labels, samples from the image distributions conditioned on these labels. The conditional GAN combined with a trained CiGM for the labels is then a CiGM over the labels and the generated image. We show that the proposed architectures can be used to sample from observational and interventional image distributions, even for interventions which do not naturally occur in the dataset.
tl;dr: We propose a light-weight enhancement for attention and a neural architecture, FusionNet, to achieve SotA on SQuAD and adversarial SQuAD.

This paper introduces a new neural structure called FusionNet, which extends existing attention approaches from three perspectives. First, it puts forward a novel concept of "History of Word" to characterize attention information from the lowest word-level embedding up to the highest semantic-level representation. Second, it identifies an attention scoring function that better utilizes the "history of word" concept. Third, it proposes a fully-aware multi-level attention mechanism to capture the complete information in one text (such as a question) and exploit it in its counterpart (such as context or passage) layer by layer. We apply FusionNet to the Stanford Question Answering Dataset (SQuAD) and it achieves the first position for both single and ensemble model on the official SQuAD leaderboard at the time of writing (Oct. 4th, 2017). Meanwhile, we verify the generalization of FusionNet with two adversarial SQuAD datasets and it sets up the new state-of-the-art on both datasets: on AddSent, FusionNet increases the best F1 metric from 46.6% to 51.4%; on AddOneSent, FusionNet boosts the best F1 metric from 56.0% to 60.7%.
tl;dr: User-level differential privacy for recurrent neural network language models is possible with a sufficiently large dataset.

We demonstrate that it is possible to train large recurrent language models with user-level differential privacy guarantees with only a negligible cost in predictive accuracy. Our work builds on recent advances in the training of deep networks on user-partitioned data and privacy accounting for stochastic gradient descent. In particular, we add user-level privacy protection to the federated averaging algorithm, which makes large step updates from user-level data. Our work demonstrates that given a dataset with a sufficiently large number of users (a requirement easily met by even small internet-scale datasets), achieving differential privacy comes at the cost of increased computation, rather than in decreased utility as in most prior work. We find that our private LSTM language models are quantitatively and qualitatively similar to un-noised models when trained on a large dataset.

Inspired by the principles of speed reading, we introduce Skim-RNN, a recurrent neural network (RNN) that dynamically decides to update only a small fraction of the hidden state for relatively unimportant input tokens. Skim-RNN gives a significant computational advantage over an RNN that always updates the entire hidden state. Skim-RNN uses the same input and output interfaces as a standard RNN and can be easily used instead of RNNs in existing models. In our experiments, we show that Skim-RNN can achieve significantly reduced computational cost without losing accuracy compared to standard RNNs across five different natural language tasks. In addition, we demonstrate that the trade-off between accuracy and speed of Skim-RNN can be dynamically controlled during inference time in a stable manner. Our analysis also shows that Skim-RNN running on a single CPU offers lower latency compared to standard RNNs on GPUs.
tl;dr: Without learning, it is impossible to explain a machine learning model's decisions.

DeConvNet, Guided BackProp, LRP, were invented to better understand deep neural networks. We show that these methods do not produce the theoretically correct explanation for a linear model. Yet they are used on multi-layer networks with millions of parameters. This is a cause for concern since linear models are simple neural networks. We argue that explanation methods for neural nets should work reliably in the limit of simplicity, the linear models. Based on our analysis of linear models we propose a generalization that yields two explanation techniques (PatternNet and PatternAttribution) that are theoretically sound for linear models and produce improved explanations for deep networks.
tl;dr: We apply training and inference with only low-bitwidth integers in DNNs

Researches on deep neural networks with discrete parameters and their deployment in embedded systems have been active and promising topics. Although previous works have successfully reduced precision in inference, transferring both training and inference processes to low-bitwidth integers has not been demonstrated simultaneously. In this work, we develop a new method termed as ``"WAGE" to discretize both training and inference, where weights (W), activations (A), gradients (G) and errors (E) among layers are shifted and linearly constrained to low-bitwidth integers. To perform pure discrete dataflow for fixed-point devices, we further replace batch normalization by a constant scaling layer and simplify other components that are arduous for integer implementation. Improved accuracies can be obtained on multiple datasets, which indicates that WAGE somehow acts as a type of regularization. Empirically, we demonstrate the potential to deploy training in hardware systems such as integer-based deep learning accelerators and neuromorphic chips with comparable accuracy and higher energy efficiency, which is crucial to future AI applications in variable scenarios with transfer and continual learning demands.
tl;dr: A distributed architecture for deep reinforcement learning at scale, using parallel data-generation to improve the state of the art on the Arcade Learning Environment benchmark in a fraction of the wall-clock training time of previous approaches.

We propose a distributed architecture for deep reinforcement learning at scale, that enables agents to learn effectively from orders of magnitude more data than previously possible. The algorithm decouples acting from learning: the actors interact with their own instances of the environment by selecting actions according to a shared neural network, and accumulate the resulting experience in a shared experience replay memory; the learner replays samples of experience and updates the neural network. The architecture relies on prioritized experience replay to focus only on the most significant data generated by the actors. Our architecture substantially improves the state of the art on the Arcade Learning Environment, achieving better final performance in a fraction of the wall-clock training time.
49. Relational Neural Expectation Maximization: Unsupervised Discovery of Objects and their Interactions
tl;dr: We introduce a novel approach to common-sense physical reasoning that learns to discover objects and model their physical interactions from raw visual images in a purely unsupervised fashion

Common-sense physical reasoning is an essential ingredient for any intelligent agent operating in the real-world. For example, it can be used to simulate the environment, or to infer the state of parts of the world that are currently unobserved. In order to match real-world conditions this causal knowledge must be learned without access to supervised data. To address this problem we present a novel method that learns to discover objects and model their physical interactions from raw visual images in a purely unsupervised fashion. It incorporates prior knowledge about the compositional nature of human perception to factor interactions between object-pairs and learn efficiently. On videos of bouncing balls we show the superior modelling capabilities of our method compared to other unsupervised neural approaches that do not incorporate such prior knowledge. We demonstrate its ability to handle occlusion and show that it can extrapolate learned knowledge to scenes with different numbers of objects.
tl;dr: A novel adversarial attack that can directly attack real-world black-box machine learning models without transfer.

Many machine learning algorithms are vulnerable to almost imperceptible perturbations of their inputs. So far it was unclear how much risk adversarial perturbations carry for the safety of real-world machine learning applications because most methods used to generate such perturbations rely either on detailed model information (gradient-based attacks) or on confidence scores such as class probabilities (score-based attacks), neither of which are available in most real-world scenarios. In many such cases one currently needs to retreat to transfer-based attacks which rely on cumbersome substitute models, need access to the training data and can be defended against. Here we emphasise the importance of attacks which solely rely on the final model decision. Such decision-based attacks are (1) applicable to real-world black-box models such as autonomous cars, (2) need less knowledge and are easier to apply than transfer-based attacks and (3) are more robust to simple defences than gradient- or score-based attacks. Previous attacks in this category were limited to simple models or simple datasets. Here we introduce the Boundary Attack, a decision-based attack that starts from a large adversarial perturbation and then seeks to reduce the perturbation while staying adversarial. The attack is conceptually simple, requires close to no hyperparameter tuning, does not rely on substitute models and is competitive with the best gradient-based attacks in standard computer vision tasks like ImageNet. We apply the attack on two black-box algorithms from Clarifai.com. The Boundary Attack in particular and the class of decision-based attacks in general open new avenues to study the robustness of machine learning models and raise new questions regarding the safety of deployed machine learning systems. An implementation of the attack is available as part of Foolbox (https://github.com/bethgelab/foolbox).
tl;dr: Domain guided augmentation of data provides a robust and stable method of domain generalization

We present CROSSGRAD , a method to use multi-domain training data to learn a classifier that generalizes to new domains. CROSSGRAD does not need an adaptation phase via labeled or unlabeled data, or domain features in the new domain. Most existing domain adaptation methods attempt to erase domain signals using techniques like domain adversarial training. In contrast, CROSSGRAD is free to use domain signals for predicting labels, if it can prevent overfitting on training domains. We conceptualize the task in a Bayesian setting, in which a sampling step is implemented as data augmentation, based on domain-guided perturbations of input instances. CROSSGRAD jointly trains a label and a domain classifier on examples perturbed by loss gradients of each other’s objectives. This enables us to directly perturb inputs, without separating and re-mixing domain signals while making various distributional assumptions. Empirical evaluation on three different applications where this setting is natural establishes that
(1) domain-guided perturbation provides consistently better generalization to unseen domains, compared to generic instance perturbation methods, and
(2) data augmentation is a more stable and accurate method than domain adversarial training.
tl;dr: General method to train expressive MCMC kernels parameterized with deep neural networks. Given a target distribution p, our method provides a fast-mixing sampler, able to efficiently explore the state space.

We present a general-purpose method to train Markov chain Monte Carlo kernels, parameterized by deep neural networks, that converge and mix quickly to their target distribution. Our method generalizes Hamiltonian Monte Carlo and is trained to maximize expected squared jumped distance, a proxy for mixing speed. We demonstrate large empirical gains on a collection of simple but challenging distributions, for instance achieving a 106x improvement in effective sample size in one case, and mixing when standard HMC makes no measurable progress in a second. Finally, we show quantitative and qualitative gains on a real-world task: latent-variable generative modeling. Python source code will be open-sourced with the camera-ready paper.
tl;dr: We demonstrate a certifiable, trainable, and scalable method for defending against adversarial examples.

While neural networks have achieved high accuracy on standard image classification benchmarks, their accuracy drops to nearly zero in the presence of small adversarial perturbations to test inputs. Defenses based on regularization and adversarial training have been proposed, but often followed by new, stronger attacks that defeat these defenses. Can we somehow end this arms race? In this work, we study this problem for neural networks with one hidden layer. We first propose a method based on a semidefinite relaxation that outputs a certificate that for a given network and test input, no attack can force the error to exceed a certain value. Second, as this certificate is differentiable, we jointly optimize it with the network parameters, providing an adaptive regularizer that encourages robustness against all attacks. On MNIST, our approach produces a network and a certificate that no that perturbs each pixel by at most $\epsilon = 0.1$ can cause more than $35\%$ test error.
tl;dr: A controlled study of the role of environments with respect to properties in emergent communication protocols.

The ability of algorithms to evolve or learn (compositional) communication protocols has traditionally been studied in the language evolution literature through the use of emergent communication tasks. Here we scale up this research by using contemporary deep learning methods and by training reinforcement-learning neural network agents on referential communication games. We extend previous work, in which agents were trained in symbolic environments, by developing agents which are able to learn from raw pixel data, a more challenging and realistic input representation. We find that the degree of structure found in the input data affects the nature of the emerged protocols, and thereby corroborate the hypothesis that structured compositional language is most likely to emerge when agents perceive the world as being structured.
tl;dr: A self-attention network for RNN/CNN-free sequence encoding with small memory consumption, highly parallelizable computation and state-of-the-art performance on several NLP tasks

Recurrent neural networks (RNN), convolutional neural networks (CNN) and self-attention networks (SAN) are commonly used to produce context-aware representations. RNN can capture long-range dependency but is hard to parallelize and not time-efficient. CNN focuses on local dependency but does not perform well on some tasks. SAN can model both such dependencies via highly parallelizable computation, but memory requirement grows rapidly in line with sequence length. In this paper, we propose a model, called "bi-directional block self-attention network (Bi-BloSAN)", for RNN/CNN-free sequence encoding. It requires as little memory as RNN but with all the merits of SAN. Bi-BloSAN splits the entire sequence into blocks, and applies an intra-block SAN to each block for modeling local context, then applies an inter-block SAN to the outputs for all blocks to capture long-range dependency. Thus, each SAN only needs to process a short sequence, and only a small amount of memory is required. Additionally, we use feature-level attention to handle the variation of contexts around the same word, and use forward/backward masks to encode temporal order information. On nine benchmark datasets for different NLP tasks, Bi-BloSAN achieves or improves upon state-of-the-art accuracy, and shows better efficiency-memory trade-off than existing RNN/CNN/SAN.

Policy gradient methods have achieved remarkable successes in solving challenging reinforcement learning problems. However, it still often suffers from the large variance issue on policy gradient estimation, which leads to poor sample efficiency during training. In this work, we propose a control variate method to effectively reduce variance for policy gradient methods. Motivated by the Stein’s identity, our method extends the previous control variate methods used in REINFORCE and advantage actor-critic by introducing more flexible and general action-dependent baseline functions. Empirical studies show that our method essentially improves the sample efficiency of the state-of-the-art policy gradient approaches.
tl;dr: We introduce contextual decompositions, an interpretation algorithm for LSTMs capable of extracting word, phrase and interaction-level importance score

The driving force behind the recent success of LSTMs has been their ability to learn complex and non-linear relationships. Consequently, our inability to describe these relationships has led to LSTMs being characterized as black boxes. To this end, we introduce contextual decomposition (CD), an interpretation algorithm for analysing individual predictions made by standard LSTMs, without any changes to the underlying model. By decomposing the output of a LSTM, CD captures the contributions of combinations of words or variables to the final prediction of an LSTM. On the task of sentiment analysis with the Yelp and SST data sets, we show that CD is able to reliably identify words and phrases of contrasting sentiment, and how they are combined to yield the LSTM's final prediction. Using the phrase-level labels in SST, we also demonstrate that CD is able to successfully extract positive and negative negations from an LSTM, something which has not previously been done.
tl;dr: An algorithm for training neural networks efficiently on temporally redundant data.

The vast majority of natural sensory data is temporally redundant. For instance, video frames or audio samples which are sampled at nearby points in time tend to have similar values. Typically, deep learning algorithms take no advantage of this redundancy to reduce computations. This can be an obscene waste of energy. We present a variant on backpropagation for neural networks in which computation scales with the rate of change of the data - not the rate at which we process the data. We do this by implementing a form of Predictive Coding wherein neurons communicate a combination of their state, and their temporal change in state, and quantize this signal using Sigma-Delta modulation. Intriguingly, this simple communication rule give rise to units that resemble biologically-inspired leaky integrate-and-fire neurons, and to a spike-timing-dependent weight-update similar to Spike-Timing Dependent Plasticity (STDP), a synaptic learning rule observed in the brain. We demonstrate that on MNIST, on a temporal variant of MNIST, and on Youtube-BB, a dataset with videos in the wild, our algorithm performs about as well as a standard deep network trained with backpropagation, despite only communicating discrete values between layers.

We present a method for reinforcement learning of closely related skills that are parameterized via a skill embedding space. We learn such skills by taking advantage of latent variables and exploiting a connection between reinforcement learning and variational inference. The main contribution of our work is an entropy-regularized policy gradient formulation for hierarchical policies, and an associated, data-efficient and robust off-policy gradient algorithm based on stochastic value gradients. We demonstrate the effectiveness of our method on several simulated robotic manipulation tasks. We find that our method allows for discovery of multiple solutions and is capable of learning the minimum number of distinct skills that are necessary to solve a given set of tasks. In addition, our results indicate that the hereby proposed technique can interpolate and/or sequence previously learned skills in order to accomplish more complex tasks, even in the presence of sparse rewards.
tl;dr: We learn deep networks of hard-threshold units by setting hidden-unit targets using combinatorial optimization and weights by convex optimization, resulting in improved performance on ImageNet.

As neural networks grow deeper and wider, learning networks with hard-threshold activations is becoming increasingly important, both for network quantization, which can drastically reduce time and energy requirements, and for creating large integrated systems of deep networks, which may have non-differentiable components and must avoid vanishing and exploding gradients for effective learning. However, since gradient descent is not applicable to hard-threshold functions, it is not clear how to learn them in a principled way. We address this problem by observing that setting targets for hard-threshold hidden units in order to minimize loss is a discrete optimization problem, and can be solved as such. The discrete optimization goal is to find a set of targets such that each unit, including the output, has a linearly separable problem to solve. Given these targets, the network decomposes into individual perceptrons, which can then be learned with standard convex approaches. Based on this, we develop a recursive mini-batch algorithm for learning deep hard-threshold networks that includes the popular but poorly justified straight-through estimator as a special case. Empirically, we show that our algorithm improves classification accuracy in a number of settings, including for AlexNet and ResNet-18 on ImageNet, when compared to the straight-through estimator.
tl;dr: "Active Neural Localizer", a fully differentiable neural network that learns to localize efficiently using deep reinforcement learning.

Localization is the problem of estimating the location of an autonomous agent from an observation and a map of the environment. Traditional methods of localization, which filter the belief based on the observations, are sub-optimal in the number of steps required, as they do not decide the actions taken by the agent. We propose "Active Neural Localizer", a fully differentiable neural network that learns to localize efficiently. The proposed model incorporates ideas of traditional filtering-based localization methods, by using a structured belief of the state with multiplicative interactions to propagate belief, and combines it with a policy model to minimize the number of steps required for localization. Active Neural Localizer is trained end-to-end with reinforcement learning. We use a variety of simulation environments for our experiments which include random 2D mazes, random mazes in the Doom game engine and a photo-realistic environment in the Unreal game engine. The results on the 2D environments show the effectiveness of the learned policy in an idealistic setting while results on the 3D environments demonstrate the model's capability of learning the policy and perceptual model jointly from raw-pixel based RGB observations. We also show that a model trained on random textures in the Doom environment generalizes well to a photo-realistic office space environment in the Unreal engine.
tl;dr: We propose the use of optimistic mirror decent to address cycling problems in the training of GANs. We also introduce the Optimistic Adam algorithm

We address the issue of limit cycling behavior in training Generative Adversarial Networks and propose the use of Optimistic Mirror Decent (OMD) for training Wasserstein GANs. Recent theoretical results have shown that optimistic mirror decent (OMD) can enjoy faster regret rates in the context of zero-sum games. WGANs is exactly a context of solving a zero-sum game with simultaneous no-regret dynamics. Moreover, we show that optimistic mirror decent addresses the limit cycling problem in training WGANs. We formally show that in the case of bi-linear zero-sum games the last iterate of OMD dynamics converges to an equilibrium, in contrast to GD dynamics which are bound to cycle. We also portray the huge qualitative difference between GD and OMD dynamics with toy examples, even when GD is modified with many adaptations proposed in the recent literature, such as gradient penalty or momentum. We apply OMD WGAN training to a bioinformatics problem of generating DNA sequences. We observe that models trained with OMD achieve consistently smaller KL divergence with respect to the true underlying distribution, than models trained with GD variants. Finally, we introduce a new algorithm, Optimistic Adam, which is an optimistic variant of Adam. We apply it to WGAN training on CIFAR10 and observe improved performance in terms of inception score as compared to Adam.
tl;dr: We construct a Kronecker factored Laplace approximation for neural networks that leads to an efficient matrix normal distribution over the weights.

We leverage recent insights from second-order optimisation for neural networks to construct a Kronecker factored Laplace approximation to the posterior over the weights of a trained network. Our approximation requires no modification of the training procedure, enabling practitioners to estimate the uncertainty of their models currently used in production without having to retrain them. We extensively compare our method to using Dropout and a diagonal Laplace approximation for estimating the uncertainty of a network. We demonstrate that our Kronecker factored method leads to better uncertainty estimates on out-of-distribution data and is more robust to simple adversarial attacks. Our approach only requires calculating two square curvature factor matrices for each layer. Their size is equal to the respective square of the input and output size of the layer, making the method efficient both computationally and in terms of memory usage. We illustrate its scalability by applying it to a state-of-the-art convolutional network architecture.
tl;dr: We show that it is possible to fastly approximate Wasserstein distances computation by finding an appropriate embedding where Euclidean distance emulates the Wasserstein distance

The Wasserstein distance received a lot of attention recently in the community of machine learning, especially for its principled way of comparing distributions. It has found numerous applications in several hard problems, such as domain adaptation, dimensionality reduction or generative models. However, its use is still limited by a heavy computational cost. Our goal is to alleviate this problem by providing an approximation mechanism that allows to break its inherent complexity. It relies on the search of an embedding where the Euclidean distance mimics the Wasserstein distance. We show that such an embedding can be found with a siamese architecture associated with a decoder network that allows to move from the embedding space back to the original input space. Once this embedding has been found, computing optimization problems in the Wasserstein space (e.g. barycenters, principal directions or even archetypes) can be conducted extremely fast. Numerical experiments supporting this idea are conducted on image datasets, and show the wide potential benefits of our method.
tl;dr: Obtains state-of-the-art accuracy for quantized, shallow nets by leveraging distillation.

Deep neural networks (DNNs) continue to make significant advances, solving tasks from image classification to translation or reinforcement learning. One aspect of the field receiving considerable attention is efficiently executing deep models in resource-constrained environments, such as mobile or embedded devices. This paper focuses on this problem, and proposes two new compression methods, which jointly leverage weight quantization and distillation of larger teacher networks into smaller student networks. The first method we propose is called quantized distillation and leverages distillation during the training process, by incorporating distillation loss, expressed with respect to the teacher, into the training of a student network whose weights are quantized to a limited set of levels. The second method, differentiable quantization, optimizes the location of quantization points through stochastic gradient descent, to better fit the behavior of the teacher model. We validate both methods through experiments on convolutional and recurrent architectures. We show that quantized shallow students can reach similar accuracy levels to full-precision teacher models, while providing order of magnitude compression, and inference speedup that is linear in the depth reduction. In sum, our results enable DNNs for resource-constrained environments to leverage architecture and accuracy advances developed on more powerful devices.
tl;dr: Unsupervised learning for reinforcement learning using an automatic curriculum of self-play

We describe a simple scheme that allows an agent to learn about its environment in an unsupervised manner. Our scheme pits two versions of the same agent, Alice and Bob, against one another. Alice proposes a task for Bob to complete; and then Bob attempts to complete the task. In this work we will focus on two kinds of environments: (nearly) reversible environments and environments that can be reset. Alice will "propose" the task by doing a sequence of actions and then Bob must undo or repeat them, respectively. Via an appropriate reward structure, Alice and Bob automatically generate a curriculum of exploration, enabling unsupervised training of the agent. When Bob is deployed on an RL task within the environment, this unsupervised training reduces the number of supervised episodes needed to learn, and in some cases converges to a higher reward.
tl;dr: We present a general method for unbiased estimation of gradients of black-box functions of random variables. We apply this method to discrete variational inference and reinforcement learning.

Gradient-based optimization is the foundation of deep learning and reinforcement learning.
Even when the mechanism being optimized is unknown or not differentiable, optimization using high-variance or biased gradient estimates is still often the best strategy. We introduce a general framework for learning low-variance, unbiased gradient estimators for black-box functions of random variables, based on gradients of a learned function.
These estimators can be jointly trained with model parameters or policies, and are applicable in both discrete and continuous settings. We give unbiased, adaptive analogs of state-of-the-art reinforcement learning methods such as advantage actor-critic. We also demonstrate this framework for training discrete latent-variable models.
tl;dr: We propose a novel deep network architecture that can dynamically decide its network capacity as it trains on a lifelong learning scenario.

We propose a novel deep network architecture for lifelong learning which we refer to as Dynamically Expandable Network (DEN), that can dynamically decide its network capacity as it trains on a sequence of tasks, to learn a compact overlapping knowledge sharing structure among tasks. DEN is efficiently trained in an online manner by performing selective retraining, dynamically expands network capacity upon arrival of each task with only the necessary number of units, and effectively prevents semantic drift by splitting/duplicating units and timestamping them. We validate DEN on multiple public datasets in lifelong learning scenarios on multiple public datasets, on which it not only significantly outperforms existing lifelong learning methods for deep networks, but also achieves the same level of performance as the batch model with substantially fewer number of parameters.
tl;dr: A learnable clustering objective to facilitate transfer learning across domains and tasks

This paper introduces a novel method to perform transfer learning across domains and tasks, formulating it as a problem of learning to cluster. The key insight is that, in addition to features, we can transfer similarity information and this is sufficient to learn a similarity function and clustering network to perform both domain adaptation and cross-task transfer learning. We begin by reducing categorical information to pairwise constraints, which only considers whether two instances belong to the same class or not (pairwise semantic similarity). This similarity is category-agnostic and can be learned from data in the source domain using a similarity network. We then present two novel approaches for performing transfer learning using this similarity function. First, for unsupervised domain adaptation, we design a new loss function to regularize classification with a constrained clustering loss, hence learning a clustering network with the transferred similarity metric generating the training inputs. Second, for cross-task learning (i.e., unsupervised clustering with unseen categories), we propose a framework to reconstruct and estimate the number of semantic clusters, again using the clustering network. Since the similarity network is noisy, the key is to use a robust clustering algorithm, and we show that our formulation is more robust than the alternative constrained and unconstrained clustering approaches. Using this method, we first show state of the art results for the challenging cross-task problem, applied on Omniglot and ImageNet. Our results show that we can reconstruct semantic clusters with high accuracy. We then evaluate the performance of cross-domain transfer using images from the Office-31 and SVHN-MNIST tasks and present top accuracy on both datasets. Our approach doesn't explicitly deal with domain discrepancy. If we combine with a domain adaptation loss, it shows further improvement.

Motivated by recent work on deep neural network (DNN)-based image compression methods showing potential improvements in image quality, savings in storage, and bandwidth reduction, we propose to perform image understanding tasks such as classification and segmentation directly on the compressed representations produced by these compression methods. Since the encoders and decoders in DNN-based compression methods are neural networks with feature-maps as internal representations of the images, we directly integrate these with architectures for image understanding. This bypasses decoding of the compressed representation into RGB space and reduces computational cost. Our study shows that accuracies comparable to networks that operate on compressed RGB images can be achieved while reducing the computational complexity up to $2\times$. Furthermore, we show that synergies are obtained by jointly training compression networks with classification networks on the compressed representations, improving image quality, classification accuracy, and segmentation performance. We find that inference from compressed representations is particularly advantageous compared to inference from compressed RGB images for aggressive compression rates.
tl;dr: We propose an agent that sits between the user and a black box question-answering system and which learns to reformulate questions to elicit the best possible answers

We frame Question Answering (QA) as a Reinforcement Learning task, an approach that we call Active Question Answering.
We propose an agent that sits between the user and a black box QA system and learns to reformulate questions to elicit the best possible answers. The agent probes the system with, potentially many, natural language reformulations of an initial question and aggregates the returned evidence to yield the best answer.
The reformulation system is trained end-to-end to maximize answer quality using policy gradient. We evaluate on SearchQA, a dataset of complex questions extracted from Jeopardy!. The agent outperforms a state-of-the-art base model, playing the role of the environment, and other benchmarks.
We also analyze the language that the agent has learned while interacting with the question answering system. We find that successful question reformulations look quite different from natural language paraphrases. The agent is able to discover non-trivial reformulation strategies that resemble classic information retrieval techniques such as term re-weighting (tf-idf) and stemming.
tl;dr: A new method for gradient-descent inference of permutations, with applications to latent matching inference and supervised learning of permutations with neural networks

Permutations and matchings are core building blocks in a variety of latent variable models, as they allow us to align, canonicalize, and sort data. Learning in such models is difficult, however, because exact marginalization over these combinatorial objects is intractable. In response, this paper introduces a collection of new methods for end-to-end learning in such models that approximate discrete maximum-weight matching using the continuous Sinkhorn operator. Sinkhorn iteration is attractive because it functions as a simple, easy-to-implement analog of the softmax operator. With this, we can define the Gumbel-Sinkhorn method, an extension of the Gumbel-Softmax method (Jang et al. 2016, Maddison2016 et al. 2016) to distributions over latent matchings. We demonstrate the effectiveness of our method by outperforming competitive baselines on a range of qualitatively different tasks: sorting numbers, solving jigsaw puzzles, and identifying neural signals in worms.
tl;dr: The paper proposes a new output layer for deep networks that permits the use of logged contextual bandit feedback for training.

We propose a new output layer for deep neural networks that permits the use of logged contextual bandit feedback for training. Such contextual bandit feedback can be available in huge quantities (e.g., logs of search engines, recommender systems) at little cost, opening up a path for training deep networks on orders of magnitude more data. To this effect, we propose a Counterfactual Risk Minimization (CRM) approach for training deep networks using an equivariant empirical risk estimator with variance regularization, BanditNet, and show how the resulting objective can be decomposed in a way that allows Stochastic Gradient Descent (SGD) training. We empirically demonstrate the effectiveness of the method by showing how deep networks -- ResNets in particular -- can be trained for object recognition without conventionally labeled images.
tl;dr: We propose a variational message-passing algorithm for models that contain both the deep model and probabilistic graphical model.

Recent efforts on combining deep models with probabilistic graphical models are promising in providing flexible models that are also easy to interpret. We propose a variational message-passing algorithm for variational inference in such models. We make three contributions. First, we propose structured inference networks that incorporate the structure of the graphical model in the inference network of variational auto-encoders (VAE). Second, we establish conditions under which such inference networks enable fast amortized inference similar to VAE. Finally, we derive a variational message passing algorithm to perform efficient natural-gradient inference while retaining the efficiency of the amortized inference. By simultaneously enabling structured, amortized, and natural-gradient inference for deep structured models, our method simplifies and generalizes existing methods.
tl;dr: We introduce generative networks that do not require to be learned with a discriminator or an encoder; they are obtained by inverting a special embedding operator defined by a wavelet Scattering transform.

Generative Adversarial Nets (GANs) and Variational Auto-Encoders (VAEs) provide impressive image generations from Gaussian white noise, but the underlying mathematics are not well understood. We compute deep convolutional network generators by inverting a fixed embedding operator. Therefore, they do not require to be optimized with a discriminator or an encoder. The embedding is Lipschitz continuous to deformations so that generators transform linear interpolations between input white noise vectors into deformations between output images. This embedding is computed with a wavelet Scattering transform. Numerical experiments demonstrate that the resulting Scattering generators have similar properties as GANs or VAEs, without learning a discriminative network or an encoder.
tl;dr: A summarization model combining a new intra-attention and reinforcement learning method to increase summary ROUGE scores and quality for long sequences.

Attentional, RNN-based encoder-decoder models for abstractive summarization have achieved good performance on short input and output sequences. For longer documents and summaries however these models often include repetitive and incoherent phrases. We introduce a neural network model with a novel intra-attention that attends over the input and continuously generated output separately, and a new training method that combines standard supervised word prediction and reinforcement learning (RL).
Models trained only with supervised learning often exhibit "exposure bias" - they assume ground truth is provided at each step during training.
However, when standard word prediction is combined with the global sequence prediction training of RL the resulting summaries become more readable.
We evaluate this model on the CNN/Daily Mail and New York Times datasets. Our model obtains a 41.16 ROUGE-1 score on the CNN/Daily Mail dataset, an improvement over previous state-of-the-art models. Human evaluation also shows that our model produces higher quality summaries.
tl;dr: Action-dependent baselines can be bias-free and yield greater variance reduction than state-only dependent baselines for policy gradient methods.

Policy gradient methods have enjoyed great success in deep reinforcement learning but suffer from high variance of gradient estimates. The high variance problem is particularly exasperated in problems with long horizons or high-dimensional action spaces. To mitigate this issue, we derive a bias-free action-dependent baseline for variance reduction which fully exploits the structural form of the stochastic policy itself and does not make any additional assumptions about the MDP. We demonstrate and quantify the benefit of the action-dependent baseline through both theoretical analysis as well as numerical results, including an analysis of the suboptimality of the optimal state-dependent baseline. The result is a computationally efficient policy gradient algorithm, which scales to high-dimensional control problems, as demonstrated by a synthetic 2000-dimensional target matching task. Our experimental results indicate that action-dependent baselines allow for faster learning on standard reinforcement learning benchmarks and high-dimensional hand manipulation and synthetic tasks. Finally, we show that the general idea of including additional information in baselines for improved variance reduction can be extended to partially observed and multi-agent tasks.
tl;dr: Effective regularization and optimization strategies for LSTM-based language models achieves SOTA on PTB and WT2.

In this paper, we consider the specific problem of word-level language modeling and investigate strategies for regularizing and optimizing LSTM-based models. We propose the weight-dropped LSTM, which uses DropConnect on hidden-to-hidden weights, as a form of recurrent regularization. Further, we introduce NT-ASGD, a non-monotonically triggered (NT) variant of the averaged stochastic gradient method (ASGD), wherein the averaging trigger is determined using a NT condition as opposed to being tuned by the user. Using these and other regularization strategies, our ASGD Weight-Dropped LSTM (AWD-LSTM) achieves state-of-the-art word level perplexities on two data sets: 57.3 on Penn Treebank and 65.8 on WikiText-2. In exploring the effectiveness of a neural cache in conjunction with our proposed model, we achieve an even lower state-of-the-art perplexity of 52.8 on Penn Treebank and 52.0 on WikiText-2. We also explore the viability of the proposed regularization and optimization strategies in the context of the quasi-recurrent neural network (QRNN) and demonstrate comparable performance to the AWD-LSTM counterpart. The code for reproducing the results is open sourced and is available at https://github.com/salesforce/awd-lstm-lm.
tl;dr: We investigate the bias in the short-horizon meta-optimization objective.

Careful tuning of the learning rate, or even schedules thereof, can be crucial to effective neural net training. There has been much recent interest in gradient-based meta-optimization, where one tunes hyperparameters, or even learns an optimizer, in order to minimize the expected loss when the training procedure is unrolled. But because the training procedure must be unrolled thousands of times, the meta-objective must be defined with an orders-of-magnitude shorter time horizon than is typical for neural net training. We show that such short-horizon meta-objectives cause a serious bias towards small step sizes, an effect we term short-horizon bias. We introduce a toy problem, a noisy quadratic cost function, on which we analyze short-horizon bias by deriving and comparing the optimal schedules for short and long time horizons. We then run meta-optimization experiments (both offline and online) on standard benchmark datasets, showing that meta-optimization chooses too small a learning rate by multiple orders of magnitude, even when run with a moderately long time horizon (100 steps) typical of work in the area. We believe short-horizon bias is a fundamental problem that needs to be addressed if meta-optimization is to scale to practical neural net training regimes.
tl;dr: We propose a variant of the backpropagation algorithm, in which gradients are shielded by conceptors against degradation of previously learned tasks.

Catastrophic interference has been a major roadblock in the research of continual learning. Here we propose a variant of the back-propagation algorithm, "Conceptor-Aided Backprop" (CAB), in which gradients are shielded by conceptors against degradation of previously learned tasks. Conceptors have their origin in reservoir computing, where they have been previously shown to overcome catastrophic forgetting. CAB extends these results to deep feedforward networks. On the disjoint and permuted MNIST tasks, CAB outperforms two other methods for coping with catastrophic interference that have recently been proposed.
tl;dr: Self-ensembling based algorithm for visual domain adaptation, state of the art results, won VisDA-2017 image classification domain adaptation challenge.

This paper explores the use of self-ensembling for visual domain adaptation problems. Our technique is derived from the mean teacher variant (Tarvainen et. al 2017) of temporal ensembling (Laine et al. 2017), a technique that achieved state of the art results in the area of semi-supervised learning. We introduce a number of modifications to their approach for challenging domain adaptation scenarios and evaluate its effectiveness. Our approach achieves state of the art results in a variety of benchmarks, including our winning entry in the VISDA-2017 visual domain adaptation challenge. In small image benchmarks, our algorithm not only outperforms prior art, but can also achieve accuracy that is close to that of a classifier trained in a supervised fashion.
tl;dr: A new unsupervised deep domain adaptation technique which efficiently unifies correlation alignment and entropy minimization

In this work, we face the problem of unsupervised domain adaptation with a novel deep learning approach which leverages our finding that entropy minimization is induced by the optimal alignment of second order statistics between source and target domains. We formally demonstrate this hypothesis and, aiming at achieving an optimal alignment in practical cases, we adopt a more principled strategy which, differently from the current Euclidean approaches, deploys alignment along geodesics. Our pipeline can be implemented by adding to the standard classification loss (on the labeled source domain), a source-to-target regularizer that is weighted in an unsupervised and data-driven fashion. We provide extensive experiments to assess the superiority of our framework on standard domain and modality adaptation benchmarks.

Our understanding of reinforcement learning (RL) has been shaped by theoretical and empirical results that were obtained decades ago using tabular representations and linear function approximators. These results suggest that RL methods that use temporal differencing (TD) are superior to direct Monte Carlo estimation (MC). How do these results hold up in deep RL, which deals with perceptually complex environments and deep nonlinear models? In this paper, we re-examine the role of TD in modern deep RL, using specially designed environments that control for specific factors that affect performance, such as reward sparsity, reward delay, and the perceptual complexity of the task. When comparing TD with infinite-horizon MC, we are able to reproduce classic results in modern settings. Yet we also find that finite-horizon MC is not inferior to TD, even when rewards are sparse or delayed. This makes MC a viable alternative to TD in deep RL.
tl;dr: We characterize the dimensional properties of adversarial subspaces in the neighborhood of adversarial examples via the use of Local Intrinsic Dimensionality (LID).

Deep Neural Networks (DNNs) have recently been shown to be vulnerable against adversarial examples, which are carefully crafted instances that can mislead DNNs to make errors during prediction. To better understand such attacks, a characterization is needed of the properties of regions (the so-called `adversarial subspaces') in which adversarial examples lie. We tackle this challenge by characterizing the dimensional properties of adversarial regions, via the use of Local Intrinsic Dimensionality (LID). LID assesses the space-filling capability of the region surrounding a reference example, based on the distance distribution of the example to its neighbors. We first provide explanations about how adversarial perturbation can affect the LID characteristic of adversarial regions, and then show empirically that LID characteristics can facilitate the distinction of adversarial examples generated using state-of-the-art attacks. As a proof-of-concept, we show that a potential application of LID is to distinguish adversarial examples, and the preliminary results show that it can outperform several state-of-the-art detection measures by large margins for five attack strategies considered in this paper across three benchmark datasets. Our analysis of the LID characteristic for adversarial regions not only motivates new directions of effective adversarial defense, but also opens up more challenges for developing new attacks to better understand the vulnerabilities of DNNs.
tl;dr: A new approach to conditional generation by constraining the latent space of an unconditional generative model.

Deep generative neural networks have proven effective at both conditional and unconditional modeling of complex data distributions. Conditional generation enables interactive control, but creating new controls often requires expensive retraining. In this paper, we develop a method to condition generation without retraining the model. By post-hoc learning latent constraints, value functions identify regions in latent space that generate outputs with desired attributes, we can conditionally sample from these regions with gradient-based optimization or amortized actor functions. Combining attribute constraints with a universal “realism” constraint, which enforces similarity to the data distribution, we generate realistic conditional images from an unconditional variational autoencoder. Further, using gradient-based optimization, we demonstrate identity-preserving transformations that make the minimal adjustment in latent space to modify the attributes of an image. Finally, with discrete sequences of musical notes, we demonstrate zero-shot conditional generation, learning latent constraints in the absence of labeled data or a differentiable reward function.

Inspired by previous work on emergent communication in referential games, we propose a novel multi-modal, multi-step referential game, where the sender and receiver have access to distinct modalities of an object, and their information exchange is bidirectional and of arbitrary duration. The multi-modal multi-step setting allows agents to develop an internal communication significantly closer to natural language, in that they share a single set of messages, and that the length of the conversation may vary according to the difficulty of the task. We examine these properties empirically using a dataset consisting of images and textual descriptions of mammals, where the agents are tasked with identifying the correct object. Our experiments indicate that a robust and efficient communication protocol emerges, where gradual information exchange informs better predictions and higher communication bandwidth improves generalization.

Deep residual networks (ResNets) and their variants are widely used in many computer vision applications and natural language processing tasks. However, the theoretical principles for designing and training ResNets are still not fully understood. Recently, several points of view have emerged to try to interpret ResNet theoretically, such as unraveled view, unrolled iterative estimation and dynamical systems view. In this paper, we adopt the dynamical systems point of view, and analyze the lesioning properties of ResNet both theoretically and experimentally. Based on these analyses, we additionally propose a novel method for accelerating ResNet training. We apply the proposed method to train ResNets and Wide ResNets for three image classification benchmarks, reducing training time by more than 40\% with superior or on-par accuracy.
88. HexaConv
tl;dr: We introduce G-HexaConv, a group equivariant convolutional neural network on hexagonal lattices.

The effectiveness of Convolutional Neural Networks stems in large part from their ability to exploit the translation invariance that is inherent in many learning problems. Recently, it was shown that CNNs can exploit other invariances, such as rotation invariance, by using group convolutions instead of planar convolutions. However, for reasons of performance and ease of implementation, it has been necessary to limit the group convolution to transformations that can be applied to the filters without interpolation. Thus, for images with square pixels, only integer translations, rotations by multiples of 90 degrees, and reflections are admissible.
Whereas the square tiling provides a 4-fold rotational symmetry, a hexagonal tiling of the plane has a 6-fold rotational symmetry. In this paper we show how one can efficiently implement planar convolution and group convolution over hexagonal lattices, by re-using existing highly optimized convolution routines. We find that, due to the reduced anisotropy of hexagonal filters, planar HexaConv provides better accuracy than planar convolution with square filters, given a fixed parameter budget. Furthermore, we find that the increased degree of symmetry of the hexagonal grid increases the effectiveness of group convolutions, by allowing for more parameter sharing. We show that our method significantly outperforms conventional CNNs on the AID aerial scene classification dataset, even outperforming ImageNet pre-trained models.

We describe an end-to-end trainable model for image compression based on variational autoencoders. The model incorporates a hyperprior to effectively capture spatial dependencies in the latent representation. This hyperprior relates to side information, a concept universal to virtually all modern image codecs, but largely unexplored in image compression using artificial neural networks (ANNs). Unlike existing autoencoder compression methods, our model trains a complex prior jointly with the underlying autoencoder. We demonstrate that this model leads to state-of-the-art image compression when measuring visual quality using the popular MS-SSIM index, and yields rate--distortion performance surpassing published ANN-based methods when evaluated using a more traditional metric based on squared error (PSNR). Furthermore, we provide a qualitative comparison of models trained for different distortion metrics.

For every prediction we might wish to make, we must decide what to observe (what source of information) and when to observe it. Because making observations is costly, this decision must trade off the value of information against the cost of observation. Making observations (sensing) should be an active choice. To solve the problem of active sensing we develop a novel deep learning architecture: Deep Sensing. At training time, Deep Sensing learns how to issue predictions at various cost-performance points. To do this, it creates multiple representations at various performance levels associated with different measurement rates (costs). This requires learning how to estimate the value of real measurements vs. inferred measurements, which in turn requires learning how to infer missing (unobserved) measurements. To infer missing measurements, we develop a Multi-directional Recurrent Neural Network (M-RNN). An M-RNN differs from a bi-directional RNN in that it sequentially operates across streams in addition to within streams, and because the timing of inputs into the hidden layers is both lagged and advanced. At runtime, the operator prescribes a performance level or a cost constraint, and Deep Sensing determines what measurements to take and what to infer from those measurements, and then issues predictions. To demonstrate the power of our method, we apply it to two real-world medical datasets with significantly improved performance.
tl;dr: We find that deep networks which generalize poorly are more reliant on single directions than those that generalize well, and evaluate the impact of dropout and batch normalization, as well as class selectivity on single direction reliance.
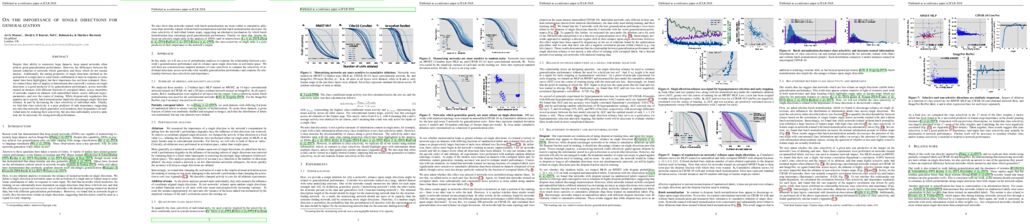
Despite their ability to memorize large datasets, deep neural networks often achieve good generalization performance. However, the differences between the learned solutions of networks which generalize and those which do not remain unclear. Additionally, the tuning properties of single directions (defined as the activation of a single unit or some linear combination of units in response to some input) have been highlighted, but their importance has not been evaluated. Here, we connect these lines of inquiry to demonstrate that a network’s reliance on single directions is a good predictor of its generalization performance, across networks trained on datasets with different fractions of corrupted labels, across ensembles of networks trained on datasets with unmodified labels, across different hyper- parameters, and over the course of training. While dropout only regularizes this quantity up to a point, batch normalization implicitly discourages single direction reliance, in part by decreasing the class selectivity of individual units. Finally, we find that class selectivity is a poor predictor of task importance, suggesting not only that networks which generalize well minimize their dependence on individual units by reducing their selectivity, but also that individually selective units may not be necessary for strong network performance.

Adversarial perturbations of normal images are usually imperceptible to humans, but they can seriously confuse state-of-the-art machine learning models. What makes them so special in the eyes of image classifiers? In this paper, we show empirically that adversarial examples mainly lie in the low probability regions of the training distribution, regardless of attack types and targeted models. Using statistical hypothesis testing, we find that modern neural density models are surprisingly good at detecting imperceptible image perturbations. Based on this discovery, we devised PixelDefend, a new approach that purifies a maliciously perturbed image by moving it back towards the distribution seen in the training data. The purified image is then run through an unmodified classifier, making our method agnostic to both the classifier and the attacking method. As a result, PixelDefend can be used to protect already deployed models and be combined with other model-specific defenses. Experiments show that our method greatly improves resilience across a wide variety of state-of-the-art attacking methods, increasing accuracy on the strongest attack from 63% to 84% for Fashion MNIST and from 32% to 70% for CIFAR-10.
tl;dr: We investigate alternative to traditional pixel image modelling approaches, and propose a generative model for vector images.

We present sketch-rnn, a recurrent neural network able to construct stroke-based drawings of common objects. The model is trained on a dataset of human-drawn images representing many different classes. We outline a framework for conditional and unconditional sketch generation, and describe new robust training methods for generating coherent sketch drawings in a vector format.

The graph convolutional networks (GCN) recently proposed by Kipf and Welling are an effective graph model for semi-supervised learning. Such a model, however, is transductive in nature because parameters are learned through convolutions with both training and test data. Moreover, the recursive neighborhood expansion across layers poses time and memory challenges for training with large, dense graphs. To relax the requirement of simultaneous availability of test data, we interpret graph convolutions as integral transforms of embedding functions under probability measures. Such an interpretation allows for the use of Monte Carlo approaches to consistently estimate the integrals, which in turn leads to a batched training scheme as we propose in this work---FastGCN. Enhanced with importance sampling, FastGCN not only is efficient for training but also generalizes well for inference. We show a comprehensive set of experiments to demonstrate its effectiveness compared with GCN and related models. In particular, training is orders of magnitude more efficient while predictions remain comparably accurate.
tl;dr: routing networks: a new kind of neural network which learns to adaptively route its input for multi-task learning

Multi-task learning (MTL) with neural networks leverages commonalities in tasks to improve performance, but often suffers from task interference which reduces the benefits of transfer. To address this issue we introduce the routing network paradigm, a novel neural network and training algorithm. A routing network is a kind of self-organizing neural network consisting of two components: a router and a set of one or more function blocks. A function block may be any neural network – for example a fully-connected or a convolutional layer. Given an input the router makes a routing decision, choosing a function block to apply and passing the output back to the router recursively, terminating when a fixed recursion depth is reached. In this way the routing network dynamically composes different function blocks for each input. We employ a collaborative multi-agent reinforcement learning (MARL) approach to jointly train the router and function blocks. We evaluate our model against cross-stitch networks and shared-layer baselines on multi-task settings of the MNIST, mini-imagenet, and CIFAR-100 datasets. Our experiments demonstrate a significant improvement in accuracy, with sharper convergence. In addition, routing networks have nearly constant per-task training cost while cross-stitch networks scale linearly with the number of tasks. On CIFAR100 (20 tasks) we obtain cross-stitch performance levels with an 85% average reduction in training time.
tl;dr: We have proposed using the recent GrOWL regularizer for simultaneous parameter sparsity and tying in DNN learning.

Deep neural networks (DNNs) usually contain millions, maybe billions, of parameters/weights, making both storage and computation very expensive. This has motivated a large body of work to reduce the complexity of the neural network by using sparsity-inducing regularizers. Another well-known approach for controlling the complexity of DNNs is parameter sharing/tying, where certain sets of weights are forced to share a common value. Some forms of weight sharing are hard-wired to express certain in- variances, with a notable example being the shift-invariance of convolutional layers. However, there may be other groups of weights that may be tied together during the learning process, thus further re- ducing the complexity of the network. In this paper, we adopt a recently proposed sparsity-inducing regularizer, named GrOWL (group ordered weighted l1), which encourages sparsity and, simulta- neously, learns which groups of parameters should share a common value. GrOWL has been proven effective in linear regression, being able to identify and cope with strongly correlated covariates. Unlike standard sparsity-inducing regularizers (e.g., l1 a.k.a. Lasso), GrOWL not only eliminates unimportant neurons by setting all the corresponding weights to zero, but also explicitly identifies strongly correlated neurons by tying the corresponding weights to a common value. This ability of GrOWL motivates the following two-stage procedure: (i) use GrOWL regularization in the training process to simultaneously identify significant neurons and groups of parameter that should be tied together; (ii) retrain the network, enforcing the structure that was unveiled in the previous phase, i.e., keeping only the significant neurons and enforcing the learned tying structure. We evaluate the proposed approach on several benchmark datasets, showing that it can dramatically compress the network with slight or even no loss on generalization performance.

We propose to study the problem of few-shot learning with the prism of inference on a partially observed graphical model, constructed from a collection of input images whose label can be either observed or not. By assimilating generic message-passing inference algorithms with their neural-network counterparts, we define a graph neural network architecture that generalizes several of the recently proposed few-shot learning models. Besides providing improved numerical performance, our framework is easily extended to variants of few-shot learning, such as semi-supervised or active learning, demonstrating the ability of graph-based models to operate well on ‘relational’ tasks.
tl;dr: We approach to the problem of active learning as a core-set selection problem and show that this approach is especially useful in the batch active learning setting which is crucial when training CNNs.

Convolutional neural networks (CNNs) have been successfully applied to many recognition and learning tasks using a universal recipe; training a deep model on a very large dataset of supervised examples. However, this approach is rather restrictive in practice since collecting a large set of labeled images is very expensive. One way to ease this problem is coming up with smart ways for choosing images to be labelled from a very large collection (i.e. active learning).
Our empirical study suggests that many of the active learning heuristics in the literature are not effective when applied to CNNs when applied in batch setting. Inspired by these limitations, we define the problem of active learning as core-set selection, i.e. choosing set of points such that a model learned over the selected subset is competitive for the remaining data points. We further present a theoretical result characterizing the performance of any selected subset using the geometry of the datapoints. As an active learning algorithm, we choose the subset which is expected to yield best result according to our characterization. Our experiments show that the proposed method significantly outperforms existing approaches in image classification experiments by a large margin.
tl;dr: We propose an novel learning method for deep sound recognition named BC learning.

Deep learning methods have achieved high performance in sound recognition tasks. Deciding how to feed the training data is important for further performance improvement. We propose a novel learning method for deep sound recognition: Between-Class learning (BC learning). Our strategy is to learn a discriminative feature space by recognizing the between-class sounds as between-class sounds. We generate between-class sounds by mixing two sounds belonging to different classes with a random ratio. We then input the mixed sound to the model and train the model to output the mixing ratio. The advantages of BC learning are not limited only to the increase in variation of the training data; BC learning leads to an enlargement of Fisher’s criterion in the feature space and a regularization of the positional relationship among the feature distributions of the classes. The experimental results show that BC learning improves the performance on various sound recognition networks, datasets, and data augmentation schemes, in which BC learning proves to be always beneficial. Furthermore, we construct a new deep sound recognition network (EnvNet-v2) and train it with BC learning. As a result, we achieved a performance surpasses the human level.
tl;dr: The paper introduces a method of training generative recurrent networks that helps to plan ahead. We run a second RNN in a reverse direction and make a soft constraint between cotemporal forward and backward states.

We propose a simple technique for encouraging generative RNNs to plan ahead. We train a ``backward'' recurrent network to generate a given sequence in reverse order, and we encourage states of the forward model to predict cotemporal states of the backward model. The backward network is used only during training, and plays no role during sampling or inference. We hypothesize that our approach eases modeling of long-term dependencies by implicitly forcing the forward states to hold information about the longer-term future (as contained in the backward states). We show empirically that our approach achieves 9% relative improvement for a speech recognition task, and achieves significant improvement on a COCO caption generation task.
tl;dr: Stochastic variational video prediction in real-world settings.

Predicting the future in real-world settings, particularly from raw sensory observations such as images, is exceptionally challenging. Real-world events can be stochastic and unpredictable, and the high dimensionality and complexity of natural images requires the predictive model to build an intricate understanding of the natural world. Many existing methods tackle this problem by making simplifying assumptions about the environment. One common assumption is that the outcome is deterministic and there is only one plausible future. This can lead to low-quality predictions in real-world settings with stochastic dynamics. In this paper, we develop a stochastic variational video prediction (SV2P) method that predicts a different possible future for each sample of its latent variables. To the best of our knowledge, our model is the first to provide effective stochastic multi-frame prediction for real-world video. We demonstrate the capability of the proposed method in predicting detailed future frames of videos on multiple real-world datasets, both action-free and action-conditioned. We find that our proposed method produces substantially improved video predictions when compared to the same model without stochasticity, and to other stochastic video prediction methods. Our SV2P implementation will be open sourced upon publication.
tl;dr: A VAE-variant which can create diverse images corresponding to novel concrete or abstract "concepts" described using attribute vectors.

It is easy for people to imagine what a man with pink hair looks like, even if they have never seen such a person before. We call the ability to create images of novel semantic concepts visually grounded imagination. In this paper, we show how we can modify variational auto-encoders to perform this task. Our method uses a novel training objective, and a novel product-of-experts inference network, which can handle partially specified (abstract) concepts in a principled and efficient way. We also propose a set of easy-to-compute evaluation metrics that capture our intuitive notions of what it means to have good visual imagination, namely correctness, coverage, and compositionality (the 3 C’s). Finally, we perform a detailed comparison of our method with two existing joint image-attribute VAE methods (the JMVAE method of Suzuki et al., 2017 and the BiVCCA method of Wang et al., 2016) by applying them to two datasets: the MNIST-with-attributes dataset (which we introduce here), and the CelebA dataset (Liu et al., 2015).
tl;dr: We propose the first attack-independent robustness metric, a.k.a CLEVER, that can be applied to any neural network classifier.

The robustness of neural networks to adversarial examples has received great attention due to security implications. Despite various attack approaches to crafting visually imperceptible adversarial examples, little has been developed towards a comprehensive measure of robustness. In this paper, we provide theoretical justification for converting robustness analysis into a local Lipschitz constant estimation problem, and propose to use the Extreme Value Theory for efficient evaluation. Our analysis yields a novel robustness metric called CLEVER, which is short for Cross Lipschitz Extreme Value for nEtwork Robustness. The proposed CLEVER score is attack-agnostic and is computationally feasible for large neural networks. Experimental results on various networks, including ResNet, Inception-v3 and MobileNet, show that (i) CLEVER is aligned with the robustness indication measured by the $\ell_2$ and $\ell_\infty$ norms of adversarial examples from powerful attacks, and (ii) defended networks using defensive distillation or bounded ReLU indeed give better CLEVER scores. To the best of our knowledge, CLEVER is the first attack-independent robustness metric that can be applied to any neural network classifiers.
tl;dr: We introduce the DCN+ with deep residual coattention and mixed-objective RL, which achieves state of the art performance on the Stanford Question Answering Dataset.

Traditional models for question answering optimize using cross entropy loss, which encourages exact answers at the cost of penalizing nearby or overlapping answers that are sometimes equally accurate. We propose a mixed objective that combines cross entropy loss with self-critical policy learning, using rewards derived from word overlap to solve the misalignment between evaluation metric and optimization objective. In addition to the mixed objective, we introduce a deep residual coattention encoder that is inspired by recent work in deep self-attention and residual networks. Our proposals improve model performance across question types and input lengths, especially for long questions that requires the ability to capture long-term dependencies. On the Stanford Question Answering Dataset, our model achieves state of the art results with 75.1% exact match accuracy and 83.1% F1, while the ensemble obtains 78.9% exact match accuracy and 86.0% F1.
tl;dr: An online and linear-time attention mechanism that performs soft attention over adaptively-located chunks of the input sequence.

Sequence-to-sequence models with soft attention have been successfully applied to a wide variety of problems, but their decoding process incurs a quadratic time and space cost and is inapplicable to real-time sequence transduction. To address these issues, we propose Monotonic Chunkwise Attention (MoChA), which adaptively splits the input sequence into small chunks over which soft attention is computed. We show that models utilizing MoChA can be trained efficiently with standard backpropagation while allowing online and linear-time decoding at test time. When applied to online speech recognition, we obtain state-of-the-art results and match the performance of a model using an offline soft attention mechanism. In document summarization experiments where we do not expect monotonic alignments, we show significantly improved performance compared to a baseline monotonic attention-based model.
tl;dr: Compressing the word embeddings over 94% without hurting the performance.

Natural language processing (NLP) models often require a massive number of parameters for word embeddings, resulting in a large storage or memory footprint. Deploying neural NLP models to mobile devices requires compressing the word embeddings without any significant sacrifices in performance. For this purpose, we propose to construct the embeddings with few basis vectors. For each word, the composition of basis vectors is determined by a hash code. To maximize the compression rate, we adopt the multi-codebook quantization approach instead of binary coding scheme. Each code is composed of multiple discrete numbers, such as (3, 2, 1, 8), where the value of each component is limited to a fixed range. We propose to directly learn the discrete codes in an end-to-end neural network by applying the Gumbel-softmax trick. Experiments show the compression rate achieves 98% in a sentiment analysis task and 94% ~ 99% in machine translation tasks without performance loss. In both tasks, the proposed method can improve the model performance by slightly lowering the compression rate. Compared to other approaches such as character-level segmentation, the proposed method is language-independent and does not require modifications to the network architecture.
tl;dr: We quantize and prune neural network weights using variational Bayesian inference with a multi-modal, sparsity inducing prior.

In this paper, the preparation of a neural network for pruning and few-bit quantization is formulated as a variational inference problem. To this end, a quantizing prior that leads to a multi-modal, sparse posterior distribution over weights, is introduced and a differentiable Kullback-Leibler divergence approximation for this prior is derived. After training with Variational Network Quantization, weights can be replaced by deterministic quantization values with small to negligible loss of task accuracy (including pruning by setting weights to 0). The method does not require fine-tuning after quantization. Results are shown for ternary quantization on LeNet-5 (MNIST) and DenseNet (CIFAR-10).
tl;dr: Introduces an online, unbiased and easily implementable gradient estimate for recurrent models.

The novel \emph{Unbiased Online Recurrent Optimization} (UORO) algorithm allows for online learning of general recurrent computational graphs such as recurrent network models. It works in a streaming fashion and avoids backtracking through past activations and inputs. UORO is computationally as costly as \emph{Truncated Backpropagation Through Time} (truncated BPTT), a widespread algorithm for online learning of recurrent networks \cite{jaeger2002tutorial}. UORO is a modification of \emph{NoBackTrack} \cite{DBLP:journals/corr/OllivierC15} that bypasses the need for model sparsity and makes implementation easy in current deep learning frameworks, even for complex models. Like NoBackTrack, UORO provides unbiased gradient estimates; unbiasedness is the core hypothesis in stochastic gradient descent theory, without which convergence to a local optimum is not guaranteed. On the contrary, truncated BPTT does not provide this property, leading to possible divergence. On synthetic tasks where truncated BPTT is shown to diverge, UORO converges. For instance, when a parameter has a positive short-term but negative long-term influence, truncated BPTT diverges unless the truncation span is very significantly longer than the intrinsic temporal range of the interactions, while UORO performs well thanks to the unbiasedness of its gradients.
tl;dr: Pixel-wise nearest neighbors used for generating multiple images from incomplete priors such as a low-res images, surface normals, edges etc.

We present a simple nearest-neighbor (NN) approach that synthesizes high-frequency photorealistic images from an ``incomplete'' signal such as a low-resolution image, a surface normal map, or edges. Current state-of-the-art deep generative models designed for such conditional image synthesis lack two important things: (1) they are unable to generate a large set of diverse outputs, due to the mode collapse problem. (2) they are not interpretable, making it difficult to control the synthesized output. We demonstrate that NN approaches potentially address such limitations, but suffer in accuracy on small datasets. We design a simple pipeline that combines the best of both worlds: the first stage uses a convolutional neural network (CNN) to map the input to a (overly-smoothed) image, and the second stage uses a pixel-wise nearest neighbor method to map the smoothed output to multiple high-quality, high-frequency outputs in a controllable manner. Importantly, pixel-wise matching allows our method to compose novel high-frequency content by cutting-and-pasting pixels from different training exemplars. We demonstrate our approach for various input modalities, and for various domains ranging from human faces, pets, shoes, and handbags.
tl;dr: Smooth Loss Function for Top-k Error Minimization

The top-$k$ error is a common measure of performance in machine learning and computer vision. In practice, top-$k$ classification is typically performed with deep neural networks trained with the cross-entropy loss. Theoretical results indeed suggest that cross-entropy is an optimal learning objective for such a task in the limit of infinite data. In the context of limited and noisy data however, the use of a loss function that is specifically designed for top-$k$ classification can bring significant improvements.
Our empirical evidence suggests that the loss function must be smooth and have non-sparse gradients in order to work well with deep neural networks. Consequently, we introduce a family of smoothed loss functions that are suited to top-$k$ optimization via deep learning. The widely used cross-entropy is a special case of our family. Evaluating our smooth loss functions is computationally challenging: a na{\"i}ve algorithm would require $\mathcal{O}(\binom{n}{k})$ operations, where $n$ is the number of classes. Thanks to a connection to polynomial algebra and a divide-and-conquer approach, we provide an algorithm with a time complexity of $\mathcal{O}(k n)$. Furthermore, we present a novel approximation to obtain fast and stable algorithms on GPUs with single floating point precision. We compare the performance of the cross-entropy loss and our margin-based losses in various regimes of noise and data size, for the predominant use case of $k=5$. Our investigation reveals that our loss is more robust to noise and overfitting than cross-entropy.
tl;dr: Reactor combines multiple algorithmic and architectural contributions to produce an agent with higher sample-efficiency than Prioritized Dueling DQN while giving better run-time performance than A3C.

In this work we present a new agent architecture, called Reactor, which combines multiple algorithmic and architectural contributions to produce an agent with higher sample-efficiency than Prioritized Dueling DQN (Wang et al., 2016) and Categorical DQN (Bellemare et al., 2017), while giving better run-time performance than A3C (Mnih et al., 2016). Our first contribution is a new policy evaluation algorithm called Distributional Retrace, which brings multi-step off-policy updates to the distributional reinforcement learning setting. The same approach can be used to convert several classes of multi-step policy evaluation algorithms designed for expected value evaluation into distributional ones. Next, we introduce the β-leaveone-out policy gradient algorithm which improves the trade-off between variance and bias by using action values as a baseline. Our final algorithmic contribution is a new prioritized replay algorithm for sequences, which exploits the temporal locality of neighboring observations for more efficient replay prioritization. Using the Atari 2600 benchmarks, we show that each of these innovations contribute to both the sample efficiency and final agent performance. Finally, we demonstrate that Reactor reaches state-of-the-art performance after 200 million frames and less than a day of training.
tl;dr: A method to transform DNA sequences into 2D images using space-filling Hilbert Curves to enhance the strengths of CNNs

The folding structure of the DNA molecule combined with helper molecules, also referred to as the chromatin, is highly relevant for the functional properties of DNA. The chromatin structure is largely determined by the underlying primary DNA sequence, though the interaction is not yet fully understood. In this paper we develop a convolutional neural network that takes an image-representation of primary DNA sequence as its input, and predicts key determinants of chromatin structure. The method is developed such that it is capable of detecting interactions between distal elements in the DNA sequence, which are known to be highly relevant. Our experiments show that the method outperforms several existing methods both in terms of prediction accuracy and training time.
tl;dr: A hyperparameter tuning algorithm using discrete Fourier analysis and compressed sensing

We give a simple, fast algorithm for hyperparameter optimization inspired by techniques from the analysis of Boolean functions. We focus on the high-dimensional regime where the canonical example is training a neural network with a large number of hyperparameters. The algorithm --- an iterative application of compressed sensing techniques for orthogonal polynomials --- requires only uniform sampling of the hyperparameters and is thus easily parallelizable.
Experiments for training deep neural networks on Cifar-10 show that compared to state-of-the-art tools (e.g., Hyperband and Spearmint), our algorithm finds significantly improved solutions, in some cases better than what is attainable by hand-tuning. In terms of overall running time (i.e., time required to sample various settings of hyperparameters plus additional computation time), we are at least an order of magnitude faster than Hyperband and Bayesian Optimization. We also outperform Random Search $8\times$.
Our method is inspired by provably-efficient algorithms for learning decision trees using the discrete Fourier transform. We obtain improved sample-complexty bounds for learning decision trees while matching state-of-the-art bounds on running time (polynomial and quasipolynomial, respectively).

We consider the problem of detecting out-of-distribution images in neural networks. We propose ODIN, a simple and effective method that does not require any change to a pre-trained neural network. Our method is based on the observation that using temperature scaling and adding small perturbations to the input can separate the softmax score distributions of in- and out-of-distribution images, allowing for more effective detection. We show in a series of experiments that ODIN is compatible with diverse network architectures and datasets. It consistently outperforms the baseline approach by a large margin, establishing a new state-of-the-art performance on this task. For example, ODIN reduces the false positive rate from the baseline 34.7% to 4.3% on the DenseNet (applied to CIFAR-10 and Tiny-ImageNet) when the true positive rate is 95%.
tl;dr: We detect statistical interactions captured by a feedforward multilayer neural network by directly interpreting its learned weights.

Interpreting neural networks is a crucial and challenging task in machine learning. In this paper, we develop a novel framework for detecting statistical interactions captured by a feedforward multilayer neural network by directly interpreting its learned weights. Depending on the desired interactions, our method can achieve significantly better or similar interaction detection performance compared to the state-of-the-art without searching an exponential solution space of possible interactions. We obtain this accuracy and efficiency by observing that interactions between input features are created by the non-additive effect of nonlinear activation functions, and that interacting paths are encoded in weight matrices. We demonstrate the performance of our method and the importance of discovered interactions via experimental results on both synthetic datasets and real-world application datasets.
tl;dr: Natural language GAN for filling in the blank

Neural text generation models are often autoregressive language models or seq2seq models. Neural autoregressive and seq2seq models that generate text by sampling words sequentially, with each word conditioned on the previous model, are state-of-the-art for several machine translation and summarization benchmarks. These benchmarks are often defined by validation perplexity even though this is not a direct measure of sample quality. Language models are typically trained via maximum likelihood and most often with teacher forcing. Teacher forcing is well-suited to optimizing perplexity but can result in poor sample quality because generating text requires conditioning on sequences of words that were never observed at training time. We propose to improve sample quality using Generative Adversarial Network (GANs), which explicitly train the generator to produce high quality samples and have shown a lot of success in image generation. GANs were originally to designed to output differentiable values, so discrete language generation is challenging for them. We introduce an actor-critic conditional GAN that fills in missing text conditioned on the surrounding context. We show qualitatively and quantitatively, evidence that this produces more realistic text samples compared to a maximum likelihood trained model.

Structured prediction energy networks (SPENs; Belanger & McCallum 2016) use neural network architectures to define energy functions that can capture arbitrary dependencies among parts of structured outputs. Prior work used gradient descent for inference, relaxing the structured output to a set of continuous variables and then optimizing the energy with respect to them. We replace this use of gradient descent with a neural network trained to approximate structured argmax inference. This
“inference network” outputs continuous values that we treat as the output structure. We develop large-margin training criteria for joint training of the structured energy function and inference network. On multi-label classification we report speed-ups
of 10-60x compared to (Belanger et al., 2017) while also improving accuracy. For sequence labeling with simple structured energies, our approach performs comparably to exact inference while being much faster at test time. We then demonstrate improved accuracy by augmenting the energy with a “label language model” that scores entire output label sequences, showing it can improve handling of long-distance dependencies in part-of-speech tagging. Finally, we show how inference networks can replace dynamic programming for test-time inference in conditional random fields, suggestive for their general use for fast inference in structured settings.
tl;dr: Learning optimal mapping with deepNN between distributions along with theoretical guarantees.

This paper presents a novel two-step approach for the fundamental problem of learning an optimal map from one distribution to another. First, we learn an optimal transport (OT) plan, which can be thought as a one-to-many map between the two distributions. To that end, we propose a stochastic dual approach of regularized OT, and show empirically that it scales better than a recent related approach when the amount of samples is very large. Second, we estimate a Monge map as a deep neural network learned by approximating the barycentric projection of the previously-obtained OT plan. This parameterization allows generalization of the mapping outside the support of the input measure. We prove two theoretical stability results of regularized OT which show that our estimations converge to the OT and Monge map between the underlying continuous measures. We showcase our proposed approach on two applications: domain adaptation and generative modeling.
119. Deep Learning and Quantum Entanglement: Fundamental Connections with Implications to Network Design
tl;dr: Employing quantum entanglement measures for quantifying correlations in deep learning, and using the connection to fit the deep network's architecture to correlations in the data.

Formal understanding of the inductive bias behind deep convolutional networks, i.e. the relation between the network's architectural features and the functions it is able to model, is limited. In this work, we establish a fundamental connection between the fields of quantum physics and deep learning, and use it for obtaining novel theoretical observations regarding the inductive bias of convolutional networks. Specifically, we show a structural equivalence between the function realized by a convolutional arithmetic circuit (ConvAC) and a quantum many-body wave function, which facilitates the use of quantum entanglement measures as quantifiers of a deep network's expressive ability to model correlations. Furthermore, the construction of a deep ConvAC in terms of a quantum Tensor Network is enabled. This allows us to perform a graph-theoretic analysis of a convolutional network, tying its expressiveness to a min-cut in its underlying graph. We demonstrate a practical outcome in the form of a direct control over the inductive bias via the number of channels (width) of each layer. We empirically validate our findings on standard convolutional networks which involve ReLU activations and max pooling. The description of a deep convolutional network in well-defined graph-theoretic tools and the structural connection to quantum entanglement, are two interdisciplinary bridges that are brought forth by this work.
120. Sobolev GAN
tl;dr: We define a new Integral Probability Metric (Sobolev IPM) and show how it can be used for training GANs for text generation and semi-supervised learning.

We propose a new Integral Probability Metric (IPM) between distributions: the Sobolev IPM. The Sobolev IPM compares the mean discrepancy of two distributions for functions (critic) restricted to a Sobolev ball defined with respect to a dominant measure mu. We show that the Sobolev IPM compares two distributions in high dimensions based on weighted conditional Cumulative Distribution Functions (CDF) of each coordinate on a leave one out basis. The Dominant measure mu plays a crucial role as it defines the support on which conditional CDFs are compared. Sobolev IPM can be seen as an extension of the one dimensional Von-Mises Cramer statistics to high dimensional distributions. We show how Sobolev IPM can be used to train Generative Adversarial Networks (GANs). We then exploit the intrinsic conditioning implied by Sobolev IPM in text generation. Finally we show that a variant of Sobolev GAN achieves competitive results in semi-supervised learning on CIFAR-10, thanks to the smoothness enforced on the critic by Sobolev GAN which relates to Laplacian regularization.
tl;dr: using graph neural network to model structural information of the agents to improve policy and transferability

We address the problem of learning structured policies for continuous control. In traditional reinforcement learning, policies of agents are learned by MLPs which take the concatenation of all observations from the environment as input for predicting actions. In this work, we propose NerveNet to explicitly model the structure of an agent, which naturally takes the form of a graph. Specifically, serving as the agent's policy network, NerveNet first propagates information over the structure of the agent and then predict actions for different parts of the agent. In the experiments, we first show that our NerveNet is comparable to state-of-the-art methods on standard MuJoCo environments. We further propose our customized reinforcement learning environments for benchmarking two types of structure transfer learning tasks, i.e., size and disability transfer. We demonstrate that policies learned by NerveNet are significantly better than policies learned by other models and are able to transfer even in a zero-shot setting.
tl;dr: A specific gradient-based meta-learning algorithm, MAML, is equivalent to an inference procedure in a hierarchical Bayesian model. We use this connection to improve MAML via methods from approximate inference and curvature estimation.

Meta-learning allows an intelligent agent to leverage prior learning episodes as a basis for quickly improving performance on a novel task. Bayesian hierarchical modeling provides a theoretical framework for formalizing meta-learning as inference for a set of parameters that are shared across tasks. Here, we reformulate the model-agnostic meta-learning algorithm (MAML) of Finn et al. (2017) as a method for probabilistic inference in a hierarchical Bayesian model. In contrast to prior methods for meta-learning via hierarchical Bayes, MAML is naturally applicable to complex function approximators through its use of a scalable gradient descent procedure for posterior inference. Furthermore, the identification of MAML as hierarchical Bayes provides a way to understand the algorithm’s operation as a meta-learning procedure, as well as an opportunity to make use of computational strategies for efficient inference. We use this opportunity to propose an improvement to the MAML algorithm that makes use of techniques from approximate inference and curvature estimation.
tl;dr: In this paper we propose a hierarchical architecture representation in which doing random or evolutionary architecture search yields highly competitive results using fewer computational resources than the prior art.

We explore efficient neural architecture search methods and show that a simple yet powerful evolutionary algorithm can discover new architectures with excellent performance. Our approach combines a novel hierarchical genetic representation scheme that imitates the modularized design pattern commonly adopted by human experts, and an expressive search space that supports complex topologies. Our algorithm efficiently discovers architectures that outperform a large number of manually designed models for image classification, obtaining top-1 error of 3.6% on CIFAR-10 and 20.3% when transferred to ImageNet, which is competitive with the best existing neural architecture search approaches. We also present results using random search, achieving 0.3% less top-1 accuracy on CIFAR-10 and 0.1% less on ImageNet whilst reducing the search time from 36 hours down to 1 hour.
tl;dr: We perform counting for visual question answering; our model produces interpretable outputs by counting directly from detected objects.

Questions that require counting a variety of objects in images remain a major challenge in visual question answering (VQA). The most common approaches to VQA involve either classifying answers based on fixed length representations of both the image and question or summing fractional counts estimated from each section of the image. In contrast, we treat counting as a sequential decision process and force our model to make discrete choices of what to count. Specifically, the model sequentially selects from detected objects and learns interactions between objects that influence subsequent selections. A distinction of our approach is its intuitive and interpretable output, as discrete counts are automatically grounded in the image. Furthermore, our method outperforms the state of the art architecture for VQA on multiple metrics that evaluate counting.

Increasing the size of a neural network typically improves accuracy but also increases the memory and compute requirements for training the model. We introduce methodology for training deep neural networks using half-precision floating point numbers, without losing model accuracy or having to modify hyper-parameters. This nearly halves memory requirements and, on recent GPUs, speeds up arithmetic. Weights, activations, and gradients are stored in IEEE half-precision format. Since this format has a narrower range than single-precision we propose three techniques for preventing the loss of critical information. Firstly, we recommend maintaining a single-precision copy of weights that accumulates the gradients after each optimizer step (this copy is rounded to half-precision for the forward- and back-propagation). Secondly, we propose loss-scaling to preserve gradient values with small magnitudes. Thirdly, we use half-precision arithmetic that accumulates into single-precision outputs, which are converted to half-precision before storing to memory. We demonstrate that the proposed methodology works across a wide variety of tasks and modern large scale (exceeding 100 million parameters) model architectures, trained on large datasets.
tl;dr: We propose a primal-dual subgradient method for training GANs and this method effectively alleviates mode collapse.

We relate the minimax game of generative adversarial networks (GANs) to finding the saddle points of the Lagrangian function for a convex optimization problem, where the discriminator outputs and the distribution of generator outputs play the roles of primal variables and dual variables, respectively. This formulation shows the connection between the standard GAN training process and the primal-dual subgradient methods for convex optimization. The inherent connection does not only provide a theoretical convergence proof for training GANs in the function space, but also inspires a novel objective function for training. The modified objective function forces the distribution of generator outputs to be updated along the direction according to the primal-dual subgradient methods. A toy example shows that the proposed method is able to resolve mode collapse, which in this case cannot be avoided by the standard GAN or Wasserstein GAN. Experiments on both Gaussian mixture synthetic data and real-world image datasets demonstrate the performance of the proposed method on generating diverse samples.
tl;dr: We train in random subspaces of parameter space to measure how many dimensions are really needed to find a solution.

Many recently trained neural networks employ large numbers of parameters to achieve good performance. One may intuitively use the number of parameters required as a rough gauge of the difficulty of a problem. But how accurate are such notions? How many parameters are really needed? In this paper we attempt to answer this question by training networks not in their native parameter space, but instead in a smaller, randomly oriented subspace. We slowly increase the dimension of this subspace, note at which dimension solutions first appear, and define this to be the intrinsic dimension of the objective landscape. The approach is simple to implement, computationally tractable, and produces several suggestive conclusions. Many problems have smaller intrinsic dimensions than one might suspect, and the intrinsic dimension for a given dataset varies little across a family of models with vastly different sizes. This latter result has the profound implication that once a parameter space is large enough to solve a problem, extra parameters serve directly to increase the dimensionality of the solution manifold. Intrinsic dimension allows some quantitative comparison of problem difficulty across supervised, reinforcement, and other types of learning where we conclude, for example, that solving the inverted pendulum problem is 100 times easier than classifying digits from MNIST, and playing Atari Pong from pixels is about as hard as classifying CIFAR-10. In addition to providing new cartography of the objective landscapes wandered by parameterized models, the method is a simple technique for constructively obtaining an upper bound on the minimum description length of a solution. A byproduct of this construction is a simple approach for compressing networks, in some cases by more than 100 times.
tl;dr: A framework for learning high-quality sentence representations efficiently.

In this work we propose a simple and efficient framework for learning sentence representations from unlabelled data. Drawing inspiration from the distributional hypothesis and recent work on learning sentence representations, we reformulate the problem of predicting the context in which a sentence appears as a classification problem. Given a sentence and the context in which it appears, a classifier distinguishes context sentences from other contrastive sentences based on their vector representations. This allows us to efficiently learn different types of encoding functions, and we show that the model learns high-quality sentence representations. We demonstrate that our sentence representations outperform state-of-the-art unsupervised and supervised representation learning methods on several downstream NLP tasks that involve understanding sentence semantics while achieving an order of magnitude speedup in training time.
tl;dr: A unified statistical view of the broad class of deep generative models

Deep generative models have achieved impressive success in recent years. Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), as powerful frameworks for deep generative model learning, have largely been considered as two distinct paradigms and received extensive independent studies respectively. This paper aims to establish formal connections between GANs and VAEs through a new formulation of them. We interpret sample generation in GANs as performing posterior inference, and show that GANs and VAEs involve minimizing KL divergences of respective posterior and inference distributions with opposite directions, extending the two learning phases of classic wake-sleep algorithm, respectively. The unified view provides a powerful tool to analyze a diverse set of existing model variants, and enables to transfer techniques across research lines in a principled way. For example, we apply the importance weighting method in VAE literatures for improved GAN learning, and enhance VAEs with an adversarial mechanism that leverages generated samples. Experiments show generality and effectiveness of the transfered techniques.
tl;dr: Defense-GAN uses a Generative Adversarial Network to defend against white-box and black-box attacks in classification models.

In recent years, deep neural network approaches have been widely adopted for machine learning tasks, including classification. However, they were shown to be vulnerable to adversarial perturbations: carefully crafted small perturbations can cause misclassification of legitimate images. We propose Defense-GAN, a new framework leveraging the expressive capability of generative models to defend deep neural networks against such attacks. Defense-GAN is trained to model the distribution of unperturbed images. At inference time, it finds a close output to a given image which does not contain the adversarial changes. This output is then fed to the classifier. Our proposed method can be used with any classification model and does not modify the classifier structure or training procedure. It can also be used as a defense against any attack as it does not assume knowledge of the process for generating the adversarial examples. We empirically show that Defense-GAN is consistently effective against different attack methods and improves on existing defense strategies.

In this paper, we propose a novel unsupervised clustering approach exploiting the hidden information that is indirectly introduced through a pseudo classification objective. Specifically, we randomly assign a pseudo parent-class label to each observation which is then modified by applying the domain specific transformation associated with the assigned label. Generated pseudo observation-label pairs are subsequently used to train a neural network with Auto-clustering Output Layer (ACOL) that introduces multiple softmax nodes for each pseudo parent-class. Due to the unsupervised objective based on Graph-based Activity Regularization (GAR) terms, softmax duplicates of each parent-class are specialized as the hidden information captured through the help of domain specific transformations is propagated during training. Ultimately we obtain a k-means friendly latent representation. Furthermore, we demonstrate how the chosen transformation type impacts performance and helps propagate the latent information that is useful in revealing unknown clusters. Our results show state-of-the-art performance for unsupervised clustering tasks on MNIST, SVHN and USPS datasets, with the highest accuracies reported to date in the literature.
tl;dr: A technique for accelerating neural architecture selection by approximating the weights of each candidate architecture instead of training them individually.

Designing architectures for deep neural networks requires expert knowledge and substantial computation time. We propose a technique to accelerate architecture selection by learning an auxiliary HyperNet that generates the weights of a main model conditioned on that model's architecture. By comparing the relative validation performance of networks with HyperNet-generated weights, we can effectively search over a wide range of architectures at the cost of a single training run. To facilitate this search, we develop a flexible mechanism based on memory read-writes that allows us to define a wide range of network connectivity patterns, with ResNet, DenseNet, and FractalNet blocks as special cases. We validate our method (SMASH) on CIFAR-10 and CIFAR-100, STL-10, ModelNet10, and Imagenet32x32, achieving competitive performance with similarly-sized hand-designed networks.
tl;dr: We propose a method that can make use of the multiple passages information for open-domain QA.

Very recently, it comes to be a popular approach for answering open-domain questions by first searching question-related passages, then applying reading comprehension models to extract answers. Existing works usually extract answers from single passages independently, thus not fully make use of the multiple searched passages, especially for the some questions requiring several evidences, which can appear in different passages, to be answered. The above observations raise the problem of evidence aggregation from multiple passages. In this paper, we deal with this problem as answer re-ranking. Specifically, based on the answer candidates generated from the existing state-of-the-art QA model, we propose two different re-ranking methods, strength-based and coverage-based re-rankers, which make use of the aggregated evidences from different passages to help entail the ground-truth answer for the question. Our model achieved state-of-the-arts on three public open-domain QA datasets, Quasar-T, SearchQA and the open-domain version of TriviaQA, with about 8\% improvement on the former two datasets.
tl;dr: We introduced a novel gradient estimator using Stein's method, and compared with other methods on learning implicit models for approximate inference and image generation.

Implicit models, which allow for the generation of samples but not for point-wise evaluation of probabilities, are omnipresent in real-world problems tackled by machine learning and a hot topic of current research. Some examples include data simulators that are widely used in engineering and scientific research, generative adversarial networks (GANs) for image synthesis, and hot-off-the-press approximate inference techniques relying on implicit distributions. The majority of existing approaches to learning implicit models rely on approximating the intractable distribution or optimisation objective for gradient-based optimisation, which is liable to produce inaccurate updates and thus poor models. This paper alleviates the need for such approximations by proposing the \emph{Stein gradient estimator}, which directly estimates the score function of the implicitly defined distribution. The efficacy of the proposed estimator is empirically demonstrated by examples that include meta-learning for approximate inference and entropy regularised GANs that provide improved sample diversity.
tl;dr: We solve the sparse rewards problem on web UI tasks using exploration guided by demonstrations

Reinforcement learning (RL) agents improve through trial-and-error, but when reward is sparse and the agent cannot discover successful action sequences, learning stagnates. This has been a notable problem in training deep RL agents to perform web-based tasks, such as booking flights or replying to emails, where a single mistake can ruin the entire sequence of actions. A common remedy is to "warm-start" the agent by pre-training it to mimic expert demonstrations, but this is prone to overfitting. Instead, we propose to constrain exploration using demonstrations. From each demonstration, we induce high-level "workflows" which constrain the allowable actions at each time step to be similar to those in the demonstration (e.g., "Step 1: click on a textbox; Step 2: enter some text"). Our exploration policy then learns to identify successful workflows and samples actions that satisfy these workflows. Workflows prune out bad exploration directions and accelerate the agent’s ability to discover rewards. We use our approach to train a novel neural policy designed to handle the semi-structured nature of websites, and evaluate on a suite of web tasks, including the recent World of Bits benchmark. We achieve new state-of-the-art results, and show that workflow-guided exploration improves sample efficiency over behavioral cloning by more than 100x.
tl;dr: Parameter space noise allows reinforcement learning algorithms to explore by perturbing parameters instead of actions, often leading to significantly improved exploration performance.

Deep reinforcement learning (RL) methods generally engage in exploratory behavior through noise injection in the action space. An alternative is to add noise directly to the agent's parameters, which can lead to more consistent exploration and a richer set of behaviors. Methods such as evolutionary strategies use parameter perturbations, but discard all temporal structure in the process and require significantly more samples. Combining parameter noise with traditional RL methods allows to combine the best of both worlds. We demonstrate that both off- and on-policy methods benefit from this approach through experimental comparison of DQN, DDPG, and TRPO on high-dimensional discrete action environments as well as continuous control tasks.
tl;dr: We introduce SeaRNN, a novel algorithm for RNN training, inspired by the learning to search approach to structured prediction, in order to avoid the limitations of MLE training.

We propose SEARNN, a novel training algorithm for recurrent neural networks (RNNs) inspired by the "learning to search" (L2S) approach to structured prediction. RNNs have been widely successful in structured prediction applications such as machine translation or parsing, and are commonly trained using maximum likelihood estimation (MLE). Unfortunately, this training loss is not always an appropriate surrogate for the test error: by only maximizing the ground truth probability, it fails to exploit the wealth of information offered by structured losses. Further, it introduces discrepancies between training and predicting (such as exposure bias) that may hurt test performance. Instead, SEARNN leverages test-alike search space exploration to introduce global-local losses that are closer to the test error. We first demonstrate improved performance over MLE on two different tasks: OCR and spelling correction. Then, we propose a subsampling strategy to enable SEARNN to scale to large vocabulary sizes. This allows us to validate the benefits of our approach on a machine translation task.
tl;dr: A new approach for learning a model from noisy crowdsourced annotations.

Supervised learning depends on annotated examples, which are taken to be the ground truth. But these labels often come from noisy crowdsourcing platforms, like Amazon Mechanical Turk. Practitioners typically collect multiple labels per example and aggregate the results to mitigate noise (the classic crowdsourcing problem). Given a fixed annotation budget and unlimited unlabeled data, redundant annotation comes at the expense of fewer labeled examples. This raises two fundamental questions: (1) How can we best learn from noisy workers? (2) How should we allocate our labeling budget to maximize the performance of a classifier? We propose a new algorithm for jointly modeling labels and worker quality from noisy crowd-sourced data. The alternating minimization proceeds in rounds, estimating worker quality from disagreement with the current model and then updating the model by optimizing a loss function that accounts for the current estimate of worker quality. Unlike previous approaches, even with only one annotation per example, our algorithm can estimate worker quality. We establish a generalization error bound for models learned with our algorithm and establish theoretically that it's better to label many examples once (vs less multiply) when worker quality exceeds a threshold. Experiments conducted on both ImageNet (with simulated noisy workers) and MS-COCO (using the real crowdsourced labels) confirm our algorithm's benefits.
tl;dr: We propose a novel Intrinsically Motivated Goal Exploration architecture with unsupervised learning of goal space representations, and evaluate how various implementations enable the discovery of a diversity of policies.

Intrinsically motivated goal exploration algorithms enable machines to discover repertoires of policies that produce a diversity of effects in complex environments. These exploration algorithms have been shown to allow real world robots to acquire skills such as tool use in high-dimensional continuous state and action spaces. However, they have so far assumed that self-generated goals are sampled in a specifically engineered feature space, limiting their autonomy. In this work, we propose an approach using deep representation learning algorithms to learn an adequate goal space. This is a developmental 2-stage approach: first, in a perceptual learning stage, deep learning algorithms use passive raw sensor observations of world changes to learn a corresponding latent space; then goal exploration happens in a second stage by sampling goals in this latent space. We present experiments with a simulated robot arm interacting with an object, and we show that exploration algorithms using such learned representations can closely match, and even sometimes improve, the performance obtained using engineered representations.
tl;dr: Show that LSTMs are as good or better than recent innovations for LM and that model evaluation is often unreliable.

Ongoing innovations in recurrent neural network architectures have provided a steady influx of apparently state-of-the-art results on language modelling benchmarks. However, these have been evaluated using differing codebases and limited computational resources, which represent uncontrolled sources of experimental variation. We reevaluate several popular architectures and regularisation methods with large-scale automatic black-box hyperparameter tuning and arrive at the somewhat surprising conclusion that standard LSTM architectures, when properly regularised, outperform more recent models. We establish a new state of the art on the Penn Treebank and Wikitext-2 corpora, as well as strong baselines on the Hutter Prize dataset.
tl;dr: We use the theory of compressed sensing to prove that LSTMs can do at least as well on linear text classification as Bag-of-n-Grams.

Low-dimensional vector embeddings, computed using LSTMs or simpler techniques, are a popular approach for capturing the “meaning” of text and a form of unsupervised learning useful for downstream tasks. However, their power is not theoretically understood. The current paper derives formal understanding by looking at the subcase of linear embedding schemes. Using the theory of compressed sensing we show that representations combining the constituent word vectors are essentially information-preserving linear measurements of Bag-of-n-Grams (BonG) representations of text. This leads to a new theoretical result about LSTMs: low-dimensional embeddings derived from a low-memory LSTM are provably at least as powerful on classification tasks, up to small error, as a linear classifier over BonG vectors, a result that extensive empirical work has thus far been unable to show. Our experiments support these theoretical findings and establish strong, simple, and unsupervised baselines on standard benchmarks that in some cases are state of the art among word-level methods. We also show a surprising new property of embeddings such as GloVe and word2vec: they form a good sensing matrix for text that is more efficient than random matrices, the standard sparse recovery tool, which may explain why they lead to better representations in practice.
tl;dr: We present a new adversarial method for adapting neural representations based on a critic that detects non-discriminative features.

We present a domain adaptation method for transferring neural representations from label-rich source domains to unlabeled target domains. Recent adversarial methods proposed for this task learn to align features across domains by ``fooling'' a special domain classifier network. However, a drawback of this approach is that the domain classifier simply labels the generated features as in-domain or not, without considering the boundaries between classes. This means that ambiguous target features can be generated near class boundaries, reducing target classification accuracy. We propose a novel approach, Adversarial Dropout Regularization (ADR), which encourages the generator to output more discriminative features for the target domain. Our key idea is to replace the traditional domain critic with a critic that detects non-discriminative features by using dropout on the classifier network. The generator then learns to avoid these areas of the feature space and thus creates better features. We apply our ADR approach to the problem of unsupervised domain adaptation for image classification and semantic segmentation tasks, and demonstrate significant improvements over the state of the art.
tl;dr: A loss-aware weight quantization algorithm that directly considers its effect on the loss is proposed.

The huge size of deep networks hinders their use in small computing devices. In this paper, we consider compressing the network by weight quantization. We extend a recently proposed loss-aware weight binarization scheme to ternarization, with possibly different scaling parameters for the positive and negative weights, and m-bit (where m > 2) quantization. Experiments on feedforward and recurrent neural networks show that the proposed scheme outperforms state-of-the-art weight quantization algorithms, and is as accurate (or even more accurate) than the full-precision network.

Deep neural networks have excelled on a wide range of problems, from vision to language and game playing. Neural networks very gradually incorporate information into weights as they process data, requiring very low learning rates. If the training distribution shifts, the network is slow to adapt, and when it does adapt, it typically performs badly on the training distribution before the shift. Our method, Memory-based Parameter Adaptation, stores examples in memory and then uses a context-based lookup to directly modify the weights of a neural network. Much higher learning rates can be used for this local adaptation, reneging the need for many iterations over similar data before good predictions can be made. As our method is memory-based, it alleviates several shortcomings of neural networks, such as catastrophic forgetting, fast, stable acquisition of new knowledge, learning with an imbalanced class labels, and fast learning during evaluation. We demonstrate this on a range of supervised tasks: large-scale image classification and language modelling.

We introduce a general method for improving the convergence rate of gradient-based optimizers that is easy to implement and works well in practice. We demonstrate the effectiveness of the method in a range of optimization problems by applying it to stochastic gradient descent, stochastic gradient descent with Nesterov momentum, and Adam, showing that it significantly reduces the need for the manual tuning of the initial learning rate for these commonly used algorithms. Our method works by dynamically updating the learning rate during optimization using the gradient with respect to the learning rate of the update rule itself. Computing this "hypergradient" needs little additional computation, requires only one extra copy of the original gradient to be stored in memory, and relies upon nothing more than what is provided by reverse-mode automatic differentiation.
tl;dr: Neural phrase-based machine translation with linear decoding time

In this paper, we present Neural Phrase-based Machine Translation (NPMT). Our method explicitly models the phrase structures in output sequences using Sleep-WAke Networks (SWAN), a recently proposed segmentation-based sequence modeling method. To mitigate the monotonic alignment requirement of SWAN, we introduce a new layer to perform (soft) local reordering of input sequences. Different from existing neural machine translation (NMT) approaches, NPMT does not use attention-based decoding mechanisms. Instead, it directly outputs phrases in a sequential order and can decode in linear time. Our experiments show that NPMT achieves superior performances on IWSLT 2014 German-English/English-German and IWSLT 2015 English-Vietnamese machine translation tasks compared with strong NMT baselines. We also observe that our method produces meaningful phrases in output languages.
tl;dr: We present a novel architecture, based on dynamic memory, attention and composition for the task of machine reasoning.

We present Compositional Attention Networks, a novel fully differentiable neural network architecture, designed to facilitate explicit and expressive reasoning. While many types of neural networks are effective at learning and generalizing from massive quantities of data, this model moves away from monolithic black-box architectures towards a design that provides a strong prior for iterative reasoning, enabling it to support explainable and structured learning, as well as generalization from a modest amount of data. The model builds on the great success of existing recurrent cells such as LSTMs: It sequences a single recurrent Memory, Attention, and Control (MAC) cell, and by careful design imposes structural constraints on the operation of each cell and the interactions between them, incorporating explicit control and soft attention mechanisms into their interfaces. We demonstrate the model's strength and robustness on the challenging CLEVR dataset for visual reasoning, achieving a new state-of-the-art 98.9% accuracy, halving the error rate of the previous best model. More importantly, we show that the new model is more computationally efficient, data-efficient, and requires an order of magnitude less time and/or data to achieve good results.
tl;dr: state-of-the-art computational performance implementation of binary neural networks

There are many applications scenarios for which the computational
performance and memory footprint of the prediction phase of Deep
Neural Networks (DNNs) need to be optimized. Binary Deep Neural
Networks (BDNNs) have been shown to be an effective way of achieving
this objective. In this paper, we show how Convolutional Neural
Networks (CNNs) can be implemented using binary
representations. Espresso is a compact, yet powerful
library written in C/CUDA that features all the functionalities
required for the forward propagation of CNNs, in a binary file less
than 400KB, without any external dependencies. Although it is mainly
designed to take advantage of massive GPU parallelism, Espresso also
provides an equivalent CPU implementation for CNNs. Espresso
provides special convolutional and dense layers for BCNNs,
leveraging bit-packing and bit-wise computations
for efficient execution. These techniques provide a speed-up of
matrix-multiplication routines, and at the same time, reduce memory
usage when storing parameters and activations. We experimentally
show that Espresso is significantly faster than existing
implementations of optimized binary neural networks (~ 2
orders of magnitude). Espresso is released under the Apache 2.0
license and is available at http://github.com/organization/project.
tl;dr: Understand how class labels help GAN training. Propose a new evaluation metric for generative models.

Class labels have been empirically shown useful in improving the sample quality of generative adversarial nets (GANs). In this paper, we mathematically study the properties of the current variants of GANs that make use of class label information. With class aware gradient and cross-entropy decomposition, we reveal how class labels and associated losses influence GAN's training. Based on that, we propose Activation Maximization Generative Adversarial Networks (AM-GAN) as an advanced solution. Comprehensive experiments have been conducted to validate our analysis and evaluate the effectiveness of our solution, where AM-GAN outperforms other strong baselines and achieves state-of-the-art Inception Score (8.91) on CIFAR-10. In addition, we demonstrate that, with the Inception ImageNet classifier, Inception Score mainly tracks the diversity of the generator, and there is, however, no reliable evidence that it can reflect the true sample quality. We thus propose a new metric, called AM Score, to provide more accurate estimation on the sample quality. Our proposed model also outperforms the baseline methods in the new metric.
tl;dr: We provide necessary and sufficient analytical forms for the critical points of the square loss functions for various neural networks, and exploit the analytical forms to characterize the landscape properties for the loss functions of these neural networks.

Due to the success of deep learning to solving a variety of challenging machine learning tasks, there is a rising interest in understanding loss functions for training neural networks from a theoretical aspect. Particularly, the properties of critical points and the landscape around them are of importance to determine the convergence performance of optimization algorithms. In this paper, we provide a necessary and sufficient characterization of the analytical forms for the critical points (as well as global minimizers) of the square loss functions for linear neural networks. We show that the analytical forms of the critical points characterize the values of the corresponding loss functions as well as the necessary and sufficient conditions to achieve global minimum. Furthermore, we exploit the analytical forms of the critical points to characterize the landscape properties for the loss functions of linear neural networks and shallow ReLU networks. One particular conclusion is that: While the loss function of linear networks has no spurious local minimum, the loss function of one-hidden-layer nonlinear networks with ReLU activation function does have local minimum that is not global minimum.
tl;dr: We introduce flipout, an efficient method for decorrelating the gradients computed by stochastic neural net weights within a mini-batch by implicitly sampling pseudo-independent weight perturbations for each example.

Stochastic neural net weights are used in a variety of contexts, including regularization, Bayesian neural nets, exploration in reinforcement learning, and evolution strategies. Unfortunately, due to the large number of weights, all the examples in a mini-batch typically share the same weight perturbation, thereby limiting the variance reduction effect of large mini-batches. We introduce flipout, an efficient method for decorrelating the gradients within a mini-batch by implicitly sampling pseudo-independent weight perturbations for each example. Empirically, flipout achieves the ideal linear variance reduction for fully connected networks, convolutional networks, and RNNs. We find significant speedups in training neural networks with multiplicative Gaussian perturbations. We show that flipout is effective at regularizing LSTMs, and outperforms previous methods. Flipout also enables us to vectorize evolution strategies: in our experiments, a single GPU with flipout can handle the same throughput as at least 40 CPU cores using existing methods, equivalent to a factor-of-4 cost reduction on Amazon Web Services.
tl;dr: Four existing backpropagation-based attribution methods are fundamentally similar. How to assess it?

Understanding the flow of information in Deep Neural Networks (DNNs) is a challenging problem that has gain increasing attention over the last few years. While several methods have been proposed to explain network predictions, there have been only a few attempts to compare them from a theoretical perspective. What is more, no exhaustive empirical comparison has been performed in the past. In this work we analyze four gradient-based attribution methods and formally prove conditions of equivalence and approximation between them. By reformulating two of these methods, we construct a unified framework which enables a direct comparison, as well as an easier implementation. Finally, we propose a novel evaluation metric, called Sensitivity-n and test the gradient-based attribution methods alongside with a simple perturbation-based attribution method on several datasets in the domains of image and text classification, using various network architectures.
tl;dr: Pooling is achieved using wavelets instead of traditional neighborhood approaches (max, average, etc).

Convolutional Neural Networks continuously advance the progress of 2D and 3D image and object classification. The steadfast usage of this algorithm requires constant evaluation and upgrading of foundational concepts to maintain progress. Network regularization techniques typically focus on convolutional layer operations, while leaving pooling layer operations without suitable options. We introduce Wavelet Pooling as another alternative to traditional neighborhood pooling. This method decomposes features into a second level decomposition, and discards the first-level subbands to reduce feature dimensions. This method addresses the overfitting problem encountered by max pooling, while reducing features in a more structurally compact manner than pooling via neighborhood regions. Experimental results on four benchmark classification datasets demonstrate our proposed method outperforms or performs comparatively with methods like max, mean, mixed, and stochastic pooling.
tl;dr: Aligning languages without the Rosetta Stone: with no parallel data, we construct bilingual dictionaries using adversarial training, cross-domain local scaling, and an accurate proxy criterion for cross-validation.

State-of-the-art methods for learning cross-lingual word embeddings have relied on bilingual dictionaries or parallel corpora. Recent studies showed that the need for parallel data supervision can be alleviated with character-level information. While these methods showed encouraging results, they are not on par with their supervised counterparts and are limited to pairs of languages sharing a common alphabet. In this work, we show that we can build a bilingual dictionary between two languages without using any parallel corpora, by aligning monolingual word embedding spaces in an unsupervised way. Without using any character information, our model even outperforms existing supervised methods on cross-lingual tasks for some language pairs. Our experiments demonstrate that our method works very well also for distant language pairs, like English-Russian or English-Chinese. We finally describe experiments on the English-Esperanto low-resource language pair, on which there only exists a limited amount of parallel data, to show the potential impact of our method in fully unsupervised machine translation. Our code, embeddings and dictionaries are publicly available.
tl;dr: Variational inference is biased, let's debias it.

The importance-weighted autoencoder (IWAE) approach of Burda et al. defines a sequence of increasingly tighter bounds on the marginal likelihood of latent variable models. Recently, Cremer et al. reinterpreted the IWAE bounds as ordinary variational evidence lower bounds (ELBO) applied to increasingly accurate variational distributions. In this work, we provide yet another perspective on the IWAE bounds. We interpret each IWAE bound as a biased estimator of the true marginal likelihood where for the bound defined on $K$ samples we show the bias to be of order O(1/K). In our theoretical analysis of the IWAE objective we derive asymptotic bias and variance expressions. Based on this analysis we develop jackknife variational inference (JVI),
a family of bias-reduced estimators reducing the bias to $O(K^{-(m+1)})$ for any given m < K while retaining computational efficiency. Finally, we demonstrate that JVI leads to improved evidence estimates in variational autoencoders. We also report first results on applying JVI to learning variational autoencoders.
Our implementation is available at https://github.com/Microsoft/jackknife-variational-inference

Real-valued word representations have transformed NLP applications; popular examples are word2vec and GloVe, recognized for their ability to capture linguistic regularities. In this paper, we demonstrate a {\em very simple}, and yet counter-intuitive, postprocessing technique -- eliminate the common mean vector and a few top dominating directions from the word vectors -- that renders off-the-shelf representations {\em even stronger}. The postprocessing is empirically validated on a variety of lexical-level intrinsic tasks (word similarity, concept categorization, word analogy) and sentence-level tasks (semantic textural similarity and text classification) on multiple datasets and with a variety of representation methods and hyperparameter choices in multiple languages; in each case, the processed representations are consistently better than the original ones.
tl;dr: Deep Model-Based RL that works well.

Model-free reinforcement learning (RL) methods are succeeding in a growing number of tasks, aided by recent advances in deep learning. However, they tend to suffer from high sample complexity, which hinders their use in real-world domains. Alternatively, model-based reinforcement learning promises to reduce sample complexity, but tends to require careful tuning and to date have succeeded mainly in restrictive domains where simple models are sufficient for learning. In this paper, we analyze the behavior of vanilla model-based reinforcement learning methods when deep neural networks are used to learn both the model and the policy, and show that the learned policy tends to exploit regions where insufficient data is available for the model to be learned, causing instability in training. To overcome this issue, we propose to use an ensemble of models to maintain the model uncertainty and regularize the learning process. We further show that the use of likelihood ratio derivatives yields much more stable learning than backpropagation through time. Altogether, our approach Model-Ensemble Trust-Region Policy Optimization (ME-TRPO) significantly reduces the sample complexity compared to model-free deep RL methods on challenging continuous control benchmark tasks.

Model compression is significant for the wide adoption of Recurrent Neural Networks (RNNs) in both user devices possessing limited resources and business clusters requiring quick responses to large-scale service requests. This work aims to learn structurally-sparse Long Short-Term Memory (LSTM) by reducing the sizes of basic structures within LSTM units, including input updates, gates, hidden states, cell states and outputs. Independently reducing the sizes of basic structures can result in inconsistent dimensions among them, and consequently, end up with invalid LSTM units. To overcome the problem, we propose Intrinsic Sparse Structures (ISS) in LSTMs. Removing a component of ISS will simultaneously decrease the sizes of all basic structures by one and thereby always maintain the dimension consistency. By learning ISS within LSTM units, the obtained LSTMs remain regular while having much smaller basic structures. Based on group Lasso regularization, our method achieves 10.59x speedup without losing any perplexity of a language modeling of Penn TreeBank dataset. It is also successfully evaluated through a compact model with only 2.69M weights for machine Question Answering of SQuAD dataset. Our approach is successfully extended to non- LSTM RNNs, like Recurrent Highway Networks (RHNs). Our source code is available.
tl;dr: Dynamic model that learns divide and conquer strategies by weak supervision.

We consider the learning of algorithmic tasks by mere observation of input-output
pairs. Rather than studying this as a black-box discrete regression problem with
no assumption whatsoever on the input-output mapping, we concentrate on tasks
that are amenable to the principle of divide and conquer, and study what are its
implications in terms of learning.
This principle creates a powerful inductive bias that we leverage with neural
architectures that are defined recursively and dynamically, by learning two scale-
invariant atomic operations: how to split a given input into smaller sets, and how
to merge two partially solved tasks into a larger partial solution. Our model can be
trained in weakly supervised environments, namely by just observing input-output
pairs, and in even weaker environments, using a non-differentiable reward signal.
Moreover, thanks to the dynamic aspect of our architecture, we can incorporate
the computational complexity as a regularization term that can be optimized by
backpropagation. We demonstrate the flexibility and efficiency of the Divide-
and-Conquer Network on several combinatorial and geometric tasks: convex hull,
clustering, knapsack and euclidean TSP. Thanks to the dynamic programming
nature of our model, we show significant improvements in terms of generalization
error and computational complexity.
tl;dr: use parallel scan to parallelize linear recurrent neural nets. train model on length 1 million dependency

Recurrent neural networks (RNNs) are widely used to model sequential data but
their non-linear dependencies between sequence elements prevent parallelizing
training over sequence length. We show the training of RNNs with only linear
sequential dependencies can be parallelized over the sequence length using the
parallel scan algorithm, leading to rapid training on long sequences even with
small minibatch size. We develop a parallel linear recurrence CUDA kernel and
show that it can be applied to immediately speed up training and inference of
several state of the art RNN architectures by up to 9x. We abstract recent work
on linear RNNs into a new framework of linear surrogate RNNs and develop a
linear surrogate model for the long short-term memory unit, the GILR-LSTM, that
utilizes parallel linear recurrence. We extend sequence learning to new
extremely long sequence regimes that were previously out of reach by
successfully training a GILR-LSTM on a synthetic sequence classification task
with a one million timestep dependency.
tl;dr: A toy dataset based on critical percolation in a planar graph provides an analytical window to the training dynamics of deep neural networks

In this paper we approach two relevant deep learning topics: i) tackling of graph structured input data and ii) a better understanding and analysis of deep networks and related learning algorithms. With this in mind we focus on the topological classification of reachability in a particular subset of planar graphs (Mazes). Doing so, we are able to model the topology of data while staying in Euclidean space, thus allowing its processing with standard CNN architectures. We suggest a suitable architecture for this problem and show that it can express a perfect solution to the classification task. The shape of the cost function around this solution is also derived and, remarkably, does not depend on the size of the maze in the large maze limit. Responsible for this behavior are rare events in the dataset which strongly regulate the shape of the cost function near this global minimum. We further identify an obstacle to learning in the form of poorly performing local minima in which the network chooses to ignore some of the inputs. We further support our claims with training experiments and numerical analysis of the cost function on networks with up to $128$ layers.
tl;dr: We propose a method that infers the time-varying data quality level for spatiotemporal forecasting without explicitly assigned labels.

Spatiotemporal forecasting has become an increasingly important prediction task in machine learning and statistics due to its vast applications, such as climate modeling, traffic prediction, video caching predictions, and so on. While numerous studies have been conducted, most existing works assume that the data from different sources or across different locations are equally reliable. Due to cost, accessibility, or other factors, it is inevitable that the data quality could vary, which introduces significant biases into the model and leads to unreliable prediction results. The problem could be exacerbated in black-box prediction models, such as deep neural networks. In this paper, we propose a novel solution that can automatically infer data quality levels of different sources through local variations of spatiotemporal signals without explicit labels. Furthermore, we integrate the estimate of data quality level with graph convolutional networks to exploit their efficient structures. We evaluate our proposed method on forecasting temperatures in Los Angeles.
tl;dr: We analyze how the degree of overlaps between the receptive fields of a convolutional network affects its expressive power.

Expressive efficiency refers to the relation between two architectures A and B, whereby any function realized by B could be replicated by A, but there exists functions realized by A, which cannot be replicated by B unless its size grows significantly larger. For example, it is known that deep networks are exponentially efficient with respect to shallow networks, in the sense that a shallow network must grow exponentially large in order to approximate the functions represented by a deep network of polynomial size. In this work, we extend the study of expressive efficiency to the attribute of network connectivity and in particular to the effect of "overlaps" in the convolutional process, i.e., when the stride of the convolution is smaller than its filter size (receptive field).
To theoretically analyze this aspect of network's design, we focus on a well-established surrogate for ConvNets called Convolutional Arithmetic Circuits (ConvACs), and then demonstrate empirically that our results hold for standard ConvNets as well. Specifically, our analysis shows that having overlapping local receptive fields, and more broadly denser connectivity, results in an exponential increase in the expressive capacity of neural networks. Moreover, while denser connectivity can increase the expressive capacity, we show that the most common types of modern architectures already exhibit exponential increase in expressivity, without relying on fully-connected layers.

While most machine translation systems to date are trained on large parallel corpora, humans learn language in a different way: by being grounded in an environment and interacting with other humans. In this work, we propose a communication game where two agents, native speakers of their own respective languages, jointly learn to solve a visual referential task. We find that the ability to understand and translate a foreign language emerges as a means to achieve shared goals. The emergent translation is interactive and multimodal, and crucially does not require parallel corpora, but only monolingual, independent text and corresponding images. Our proposed translation model achieves this by grounding the source and target languages into a shared visual modality, and outperforms several baselines on both word-level and sentence-level translation tasks. Furthermore, we show that agents in a multilingual community learn to translate better and faster than in a bilingual communication setting.
tl;dr: Our hypothesis is that given two domains, the lowest complexity mapping that has a low discrepancy approximates the target mapping.

We discuss the feasibility of the following learning problem: given unmatched samples from two domains and nothing else, learn a mapping between the two, which preserves semantics. Due to the lack of paired samples and without any definition of the semantic information, the problem might seem ill-posed. Specifically, in typical cases, it seems possible to build infinitely many alternative mappings from every target mapping. This apparent ambiguity stands in sharp contrast to the recent empirical success in solving this problem.
We identify the abstract notion of aligning two domains in a semantic way with concrete terms of minimal relative complexity. A theoretical framework for measuring the complexity of compositions of functions is developed in order to show that it is reasonable to expect the minimal complexity mapping to be unique. The measured complexity used is directly related to the depth of the neural networks being learned and a semantically aligned mapping could then be captured simply by learning using architectures that are not much bigger than the minimal architecture.
Various predictions are made based on the hypothesis that semantic alignment can be captured by the minimal mapping. These are verified extensively. In addition, a new mapping algorithm is proposed and shown to lead to better mapping results.
tl;dr: We present a novel algorithm for solving reinforcement learning and bandit structured prediction problems with very sparse loss feedback.

We consider reinforcement learning and bandit structured prediction problems with very sparse loss feedback: only at the end of an episode. We introduce a novel algorithm, RESIDUAL LOSS PREDICTION (RESLOPE), that solves such problems by automatically learning an internal representation of a denser reward function. RESLOPE operates as a reduction to contextual bandits, using its learned loss representation to solve the credit assignment problem, and a contextual bandit oracle to trade-off exploration and exploitation. RESLOPE enjoys a no-regret reduction-style theoretical guarantee and outperforms state of the art reinforcement learning algorithms in both MDP environments and bandit structured prediction settings.

Deep generative models have been successfully used to learn representations for high-dimensional discrete spaces by representing discrete objects as sequences and employing powerful sequence-based deep models. Unfortunately, these sequence-based models often produce invalid sequences: sequences which do not represent any underlying discrete structure; invalid sequences hinder the utility of such models. As a step towards solving this problem, we propose to learn a deep recurrent validator model, which can estimate whether a partial sequence can function as the beginning of a full, valid sequence. This validator provides insight as to how individual sequence elements influence the validity of the overall sequence, and can be used to constrain sequence based models to generate valid sequences — and thus faithfully model discrete objects. Our approach is inspired by reinforcement learning, where an oracle which can evaluate validity of complete sequences provides a sparse reward signal. We demonstrate its effectiveness as a generative model of Python 3 source code for mathematical expressions, and in improving the ability of a variational autoencoder trained on SMILES strings to decode valid molecular structures.
tl;dr: This paper proposes a new feed-forward network, call PDE-Net, to learn PDEs from data.

Partial differential equations (PDEs) play a prominent role in many disciplines such as applied mathematics, physics, chemistry, material science, computer science, etc. PDEs are commonly derived based on physical laws or empirical observations. However, the governing equations for many complex systems in modern applications are still not fully known. With the rapid development of sensors, computational power, and data storage in the past decade, huge quantities of data can be easily collected and efficiently stored. Such vast quantity of data offers new opportunities for data-driven discovery of hidden physical laws. Inspired by the latest development of neural network designs in deep learning, we propose a new feed-forward deep network, called PDE-Net, to fulfill two objectives at the same time: to accurately predict dynamics of complex systems and to uncover the underlying hidden PDE models. The basic idea of the proposed PDE-Net is to learn differential operators by learning convolution kernels (filters), and apply neural networks or other machine learning methods to approximate the unknown nonlinear responses. Comparing with existing approaches, which either assume the form of the nonlinear response is known or fix certain finite difference approximations of differential operators, our approach has the most flexibility by learning both differential operators and the nonlinear responses. A special feature of the proposed PDE-Net is that all filters are properly constrained, which enables us to easily identify the governing PDE models while still maintaining the expressive and predictive power of the network. These constrains are carefully designed by fully exploiting the relation between the orders of differential operators and the orders of sum rules of filters (an important concept originated from wavelet theory). We also discuss relations of the PDE-Net with some existing networks in computer vision such as Network-In-Network (NIN) and Residual Neural Network (ResNet). Numerical experiments show that the PDE-Net has the potential to uncover the hidden PDE of the observed dynamics, and predict the dynamical behavior for a relatively long time, even in a noisy environment.

We consider the problem of training generative models with a Generative Adversarial Network (GAN). Although GANs can accurately model complex distributions, they are known to be difficult to train due to instabilities caused by a difficult minimax optimization problem. In this paper, we view the problem of training GANs as finding a mixed strategy in a zero-sum game. Building on ideas from online learning we propose a novel training method named Chekhov GAN. On the theory side, we show that our method provably converges to an equilibrium for semi-shallow GAN architectures, i.e. architectures where the discriminator is a one-layer network and the generator is arbitrary. On the practical side, we develop an efficient heuristic guided by our theoretical results, which we apply to commonly used deep GAN architectures.
On several real-world tasks our approach exhibits improved stability and performance compared to standard GAN training.
tl;dr: we find 99.9% of the gradient exchange in distributed SGD is redundant; we reduce the communication bandwidth by two orders of magnitude without losing accuracy.

Large-scale distributed training requires significant communication bandwidth for gradient exchange that limits the scalability of multi-node training, and requires expensive high-bandwidth network infrastructure. The situation gets even worse with distributed training on mobile devices (federated learning), which suffers from higher latency, lower throughput, and intermittent poor connections. In this paper, we find 99.9% of the gradient exchange in distributed SGD is redundant, and propose Deep Gradient Compression (DGC) to greatly reduce the communication bandwidth. To preserve accuracy during compression, DGC employs four methods: momentum correction, local gradient clipping, momentum factor masking, and warm-up training. We have applied Deep Gradient Compression to image classification, speech recognition, and language modeling with multiple datasets including Cifar10, ImageNet, Penn Treebank, and Librispeech Corpus. On these scenarios, Deep Gradient Compression achieves a gradient compression ratio from 270x to 600x without losing accuracy, cutting the gradient size of ResNet-50 from 97MB to 0.35MB, and for DeepSpeech from 488MB to 0.74MB. Deep gradient compression enables large-scale distributed training on inexpensive commodity 1Gbps Ethernet and facilitates distributed training on mobile.

In recent years, deep learning techniques have been developed to improve the performance of program synthesis from input-output examples. Albeit its significant progress, the programs that can be synthesized by state-of-the-art approaches are still simple in terms of their complexity. In this work, we move a significant step forward along this direction by proposing a new class of challenging tasks in the domain of program synthesis from input-output examples: learning a context-free parser from pairs of input programs and their parse trees. We show that this class of tasks are much more challenging than previously studied tasks, and the test accuracy of existing approaches is almost 0%.
We tackle the challenges by developing three novel techniques inspired by three novel observations, which reveal the key ingredients of using deep learning to synthesize a complex program. First, the use of a non-differentiable machine is the key to effectively restrict the search space. Thus our proposed approach learns a neural program operating a domain-specific non-differentiable machine. Second, recursion is the key to achieve generalizability. Thus, we bake-in the notion of recursion in the design of our non-differentiable machine. Third, reinforcement learning is the key to learn how to operate the non-differentiable machine, but it is also hard to train the model effectively with existing reinforcement learning algorithms from a cold boot. We develop a novel two-phase reinforcement learning-based search algorithm to overcome this issue. In our evaluation, we show that using our novel approach, neural parsing programs can be learned to achieve 100% test accuracy on test inputs that are 500x longer than the training samples.
tl;dr: We propose a variational inference based approach for encouraging the inference of disentangled latents. We also propose a new metric for quantifying disentanglement.

Disentangled representations, where the higher level data generative factors are reflected in disjoint latent dimensions, offer several benefits such as ease of deriving invariant representations, transferability to other tasks, interpretability, etc. We consider the problem of unsupervised learning of disentangled representations from large pool of unlabeled observations, and propose a variational inference based approach to infer disentangled latent factors. We introduce a regularizer on the expectation of the approximate posterior over observed data that encourages the disentanglement. We also propose a new disentanglement metric which is better aligned with the qualitative disentanglement observed in the decoder's output. We empirically observe significant improvement over existing methods in terms of both disentanglement and data likelihood (reconstruction quality).
tl;dr: A new way of learning semantic program embedding

Neural program embeddings have shown much promise recently for a variety of program analysis tasks, including program synthesis, program repair, code completion, and fault localization. However, most existing program embeddings are based on syntactic features of programs, such as token sequences or abstract syntax trees. Unlike images and text, a program has well-defined semantics that can be difficult to capture by only considering its syntax (i.e. syntactically similar programs can exhibit vastly different run-time behavior), which makes syntax-based program embeddings fundamentally limited. We propose a novel semantic program embedding that is learned from program execution traces. Our key insight is that program states expressed as sequential tuples of live variable values not only capture program semantics more precisely, but also offer a more natural fit for Recurrent Neural Networks to model. We evaluate different syntactic and semantic program embeddings on the task of classifying the types of errors that students make in their submissions to an introductory programming class and on the CodeHunt education platform. Our evaluation results show that the semantic program embeddings significantly outperform the syntactic program embeddings based on token sequences and abstract syntax trees. In addition, we augment a search-based program repair system with predictions made from our semantic embedding and demonstrate significantly improved search efficiency.
tl;dr: We develop an agent that we call the Distributional Deterministic Deep Policy Gradient algorithm, which achieves state of the art performance on a number of challenging continuous control problems.

This work adopts the very successful distributional perspective on reinforcement learning and adapts it to the continuous control setting. We combine this within a distributed framework for off-policy learning in order to develop what we call the Distributed Distributional Deep Deterministic Policy Gradient algorithm, D4PG. We also combine this technique with a number of additional, simple improvements such as the use of N-step returns and prioritized experience replay. Experimentally we examine the contribution of each of these individual components, and show how they interact, as well as their combined contributions. Our results show that across a wide variety of simple control tasks, difficult manipulation tasks, and a set of hard obstacle-based locomotion tasks the D4PG algorithm achieves state of the art performance.
tl;dr: We provide a principled, optimization-based re-look at the notion of adversarial examples, and develop methods that produce models that are adversarially robust against a wide range of adversaries.

Recent work has demonstrated that neural networks are vulnerable to adversarial examples, i.e., inputs that are almost indistinguishable from natural data and yet classified incorrectly by the network. To address this problem, we study the adversarial robustness of neural networks through the lens of robust optimization. This approach provides us with a broad and unifying view on much prior work on this topic. Its principled nature also enables us to identify methods for both training and attacking neural networks that are reliable and, in a certain sense, universal. In particular, they specify a concrete security guarantee that would protect against a well-defined class of adversaries. These methods let us train networks with significantly improved resistance to a wide range of adversarial attacks. They also suggest robustness against a first-order adversary as a natural security guarantee. We believe that robustness against such well-defined classes of adversaries is an important stepping stone towards fully resistant deep learning models.
tl;dr: Relaxing the constraint of shared hierarchies enables more effective deep multitask learning.

Existing deep multitask learning (MTL) approaches align layers shared between tasks in a parallel ordering. Such an organization significantly constricts the types of shared structure that can be learned. The necessity of parallel ordering for deep MTL is first tested by comparing it with permuted ordering of shared layers. The results indicate that a flexible ordering can enable more effective sharing, thus motivating the development of a soft ordering approach, which learns how shared layers are applied in different ways for different tasks. Deep MTL with soft ordering outperforms parallel ordering methods across a series of domains. These results suggest that the power of deep MTL comes from learning highly general building blocks that can be assembled to meet the demands of each task.
tl;dr: We propose a support size estimator of GANs's learned distribution to show they indeed suffer from mode collapse, and we prove that encoder-decoder GANs do not avoid the issue as well.

Do GANS (Generative Adversarial Nets) actually learn the target distribution? The foundational paper of Goodfellow et al. (2014) suggested they do, if they were given sufficiently large deep nets, sample size, and computation time. A recent theoretical analysis in Arora et al. (2017) raised doubts whether the same holds when discriminator has bounded size. It showed that the training objective can approach its optimum value even if the generated distribution has very low support. In other words, the training objective is unable to prevent mode collapse. The current paper makes two contributions. (1) It proposes a novel test for estimating support size using the birthday paradox of discrete probability. Using this evidence is presented that well-known GANs approaches do learn distributions of fairly low support. (2) It theoretically studies encoder-decoder GANs architectures (e.g., BiGAN/ALI), which were proposed to learn more meaningful features via GANs, and consequently to also solve the mode-collapse issue. Our result shows that such encoder-decoder training objectives also cannot guarantee learning of the full distribution because they cannot prevent serious mode collapse. More seriously, they cannot prevent learning meaningless codes for data, contrary to usual intuition.
tl;dr: Synthesize complex and extended human motions using an auto-conditioned LSTM network

We present a real-time method for synthesizing highly complex human motions using a novel training regime we call the auto-conditioned Recurrent Neural Network (acRNN). Recently, researchers have attempted to synthesize new motion by using autoregressive techniques, but existing methods tend to freeze or diverge after a couple of seconds due to an accumulation of errors that are fed back into the network. Furthermore, such methods have only been shown to be reliable for relatively simple human motions, such as walking or running. In contrast, our approach can synthesize arbitrary motions with highly complex styles, including dances or martial arts in addition to locomotion. The acRNN is able to accomplish this by explicitly accommodating for autoregressive noise accumulation during training. Our work is the first to our knowledge that demonstrates the ability to generate over 18,000 continuous frames (300 seconds) of new complex human motion w.r.t. different styles.
tl;dr: FearNet is a memory efficient neural-network, inspired by memory formation in the mammalian brain, that is capable of incremental class learning without catastrophic forgetting.

Incremental class learning involves sequentially learning classes in bursts of examples from the same class. This violates the assumptions that underlie methods for training standard deep neural networks, and will cause them to suffer from catastrophic forgetting. Arguably, the best method for incremental class learning is iCaRL, but it requires storing training examples for each class, making it challenging to scale. Here, we propose FearNet for incremental class learning. FearNet is a generative model that does not store previous examples, making it memory efficient. FearNet uses a brain-inspired dual-memory system in which new memories are consolidated from a network for recent memories inspired by the mammalian hippocampal complex to a network for long-term storage inspired by medial prefrontal cortex. Memory consolidation is inspired by mechanisms that occur during sleep. FearNet also uses a module inspired by the basolateral amygdala for determining which memory system to use for recall. FearNet achieves state-of-the-art performance at incremental class learning on image (CIFAR-100, CUB-200) and audio classification (AudioSet) benchmarks.
tl;dr: The normalized solution of gradient descent on logistic regression (or a similarly decaying loss) slowly converges to the L2 max margin solution on separable data.

We show that gradient descent on an unregularized logistic regression
problem, for almost all separable datasets, converges to the same direction as the max-margin solution. The result generalizes also to other monotone decreasing loss functions with an infimum at infinity, and we also discuss a multi-class generalizations to the cross entropy loss. Furthermore,
we show this convergence is very slow, and only logarithmic in the
convergence of the loss itself. This can help explain the benefit
of continuing to optimize the logistic or cross-entropy loss even
after the training error is zero and the training loss is extremely
small, and, as we show, even if the validation loss increases. Our
methodology can also aid in understanding implicit regularization
in more complex models and with other optimization methods.
tl;dr: We show that several claims of the information bottleneck theory of deep learning are not true in the general case.

The practical successes of deep neural networks have not been matched by theoretical progress that satisfyingly explains their behavior. In this work, we study the information bottleneck (IB) theory of deep learning, which makes three specific claims: first, that deep networks undergo two distinct phases consisting of an initial fitting phase and a subsequent compression phase; second, that the compression phase is causally related to the excellent generalization performance of deep networks; and third, that the compression phase occurs due to the diffusion-like behavior of stochastic gradient descent. Here we show that none of these claims hold true in the general case. Through a combination of analytical results and simulation, we demonstrate that the information plane trajectory is predominantly a function of the neural nonlinearity employed: double-sided saturating nonlinearities like tanh yield a compression phase as neural activations enter the saturation regime, but linear activation functions and single-sided saturating nonlinearities like the widely used ReLU in fact do not. Moreover, we find that there is no evident causal connection between compression and generalization: networks that do not compress are still capable of generalization, and vice versa. Next, we show that the compression phase, when it exists, does not arise from stochasticity in training by demonstrating that we can replicate the IB findings using full batch gradient descent rather than stochastic gradient descent. Finally, we show that when an input domain consists of a subset of task-relevant and task-irrelevant information, hidden representations do compress the task-irrelevant information, although the overall information about the input may monotonically increase with training time, and that this compression happens concurrently with the fitting process rather than during a subsequent compression period.
tl;dr: We integrate symbolic (deductive) and statistical (neural-based) methods to enable real-time program synthesis with almost perfect generalization from 1 input-output example.

Synthesizing user-intended programs from a small number of input-output exam-
ples is a challenging problem with several important applications like spreadsheet
manipulation, data wrangling and code refactoring. Existing synthesis systems
either completely rely on deductive logic techniques that are extensively hand-
engineered or on purely statistical models that need massive amounts of data, and in
general fail to provide real-time synthesis on challenging benchmarks. In this work,
we propose Neural Guided Deductive Search (NGDS), a hybrid synthesis technique
that combines the best of both symbolic logic techniques and statistical models.
Thus, it produces programs that satisfy the provided specifications by construction
and generalize well on unseen examples, similar to data-driven systems. Our
technique effectively utilizes the deductive search framework to reduce the learning
problem of the neural component to a simple supervised learning setup. Further,
this allows us to both train on sparingly available real-world data and still leverage
powerful recurrent neural network encoders. We demonstrate the effectiveness
of our method by evaluating on real-world customer scenarios by synthesizing
accurate programs with up to 12× speed-up compared to state-of-the-art systems.
tl;dr: Mixed precision training pipeline using 16-bit integers on general purpose HW; SOTA accuracy for ImageNet-class CNNs; Best reported accuracy for ImageNet-1K classification task with any reduced precision training;

The state-of-the-art (SOTA) for mixed precision training is dominated by variants of low precision floating point operations, and in particular, FP16 accumulating into FP32 Micikevicius et al. (2017). On the other hand, while a lot of research has also happened in the domain of low and mixed-precision Integer training, these works either present results for non-SOTA networks (for instance only AlexNet for ImageNet-1K), or relatively small datasets (like CIFAR-10). In this work, we train state-of-the-art visual understanding neural networks on the ImageNet-1K dataset, with Integer operations on General Purpose (GP) hardware. In particular, we focus on Integer Fused-Multiply-and-Accumulate (FMA) operations which take two pairs of INT16 operands and accumulate results into an INT32 output.We propose a shared exponent representation of tensors and develop a Dynamic Fixed Point (DFP) scheme suitable for common neural network operations. The nuances of developing an efficient integer convolution kernel is examined, including methods to handle overflow of the INT32 accumulator. We implement CNN training for ResNet-50, GoogLeNet-v1, VGG-16 and AlexNet; and these networks achieve or exceed SOTA accuracy within the same number of iterations as their FP32 counterparts without any change in hyper-parameters and with a 1.8X improvement in end-to-end training throughput. To the best of our knowledge these results represent the first INT16 training results on GP hardware for ImageNet-1K dataset using SOTA CNNs and achieve highest reported accuracy using half precision
184. Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning
tl;dr: A large-scale multi-task learning framework with diverse training objectives to learn fixed-length sentence representations

A lot of the recent success in natural language processing (NLP) has been driven by distributed vector representations of words trained on large amounts of text in an unsupervised manner. These representations are typically used as general purpose features for words across a range of NLP problems. However, extending this success to learning representations of sequences of words, such as sentences, remains an open problem. Recent work has explored unsupervised as well as supervised learning techniques with different training objectives to learn general purpose fixed-length sentence representations. In this work, we present a simple, effective multi-task learning framework for sentence representations that combines the inductive biases of diverse training objectives in a single model.
We train this model on several data sources with multiple training objectives on over 100 million sentences. Extensive experiments demonstrate that sharing a single recurrent sentence encoder across weakly related tasks leads to consistent improvements over previous methods. We present substantial improvements in the context of transfer learning and low-resource settings using our learned general-purpose representations.
tl;dr: We present a simple modification to the alternating SGD method, called a prediction step, that improves the stability of adversarial networks.

Adversarial neural networks solve many important problems in data science, but are notoriously difficult to train. These difficulties come from the fact that optimal weights for adversarial nets correspond to saddle points, and not minimizers, of the loss function. The alternating stochastic gradient methods typically used for such problems do not reliably converge to saddle points, and when convergence does happen it is often highly sensitive to learning rates. We propose a simple modification of stochastic gradient descent that stabilizes adversarial networks. We show, both in theory and practice, that the proposed method reliably converges to saddle points. This makes adversarial networks less likely to "collapse," and enables faster training with larger learning rates.
tl;dr: We embed nodes in a graph as Gaussian distributions allowing us to capture uncertainty about their representation.

Methods that learn representations of nodes in a graph play a critical role in network analysis since they enable many downstream learning tasks. We propose Graph2Gauss - an approach that can efficiently learn versatile node embeddings on large scale (attributed) graphs that show strong performance on tasks such as link prediction and node classification. Unlike most approaches that represent nodes as point vectors in a low-dimensional continuous space, we embed each node as a Gaussian distribution, allowing us to capture uncertainty about the representation. Furthermore, we propose an unsupervised method that handles inductive learning scenarios and is applicable to different types of graphs: plain/attributed, directed/undirected. By leveraging both the network structure and the associated node attributes, we are able to generalize to unseen nodes without additional training. To learn the embeddings we adopt a personalized ranking formulation w.r.t. the node distances that exploits the natural ordering of the nodes imposed by the network structure. Experiments on real world networks demonstrate the high performance of our approach, outperforming state-of-the-art network embedding methods on several different tasks. Additionally, we demonstrate the benefits of modeling uncertainty - by analyzing it we can estimate neighborhood diversity and detect the intrinsic latent dimensionality of a graph.

We consider the use of Deep Learning methods for modeling complex phenomena like those occurring in natural physical processes. With the large amount of data gathered on these phenomena the data intensive paradigm could begin to challenge more traditional approaches elaborated over the years in fields like maths or physics. However, despite considerable successes in a variety of application domains, the machine learning field is not yet ready to handle the level of complexity required by such problems. Using an example application, namely Sea Surface Temperature Prediction, we show how general background knowledge gained from the physics could be used as a guideline for designing efficient Deep Learning models. In order to motivate the approach and to assess its generality we demonstrate a formal link between the solution of a class of differential equations underlying a large family of physical phenomena and the proposed model. Experiments and comparison with series of baselines including a state of the art numerical approach is then provided.
tl;dr: We provide efficiently checkable necessary and sufficient conditions for global optimality in deep linear neural networks, with some initial extensions to nonlinear settings.

We study the error landscape of deep linear and nonlinear neural networks with the squared error loss. Minimizing the loss of a deep linear neural network is a nonconvex problem, and despite recent progress, our understanding of this loss surface is still incomplete. For deep linear networks, we present necessary and sufficient conditions for a critical point of the risk function to be a global minimum. Surprisingly, our conditions provide an efficiently checkable test for global optimality, while such tests are typically intractable in nonconvex optimization. We further extend these results to deep nonlinear neural networks and prove similar sufficient conditions for global optimality, albeit in a more limited function space setting.
tl;dr: A generative memory model that combines slow-learning neural networks and a fast-adapting linear Gaussian model as memory.

We present an end-to-end trained memory system that quickly adapts to new data and generates samples like them. Inspired by Kanerva's sparse distributed memory, it has a robust distributed reading and writing mechanism. The memory is analytically tractable, which enables optimal on-line compression via a Bayesian update-rule. We formulate it as a hierarchical conditional generative model, where memory provides a rich data-dependent prior distribution. Consequently, the top-down memory and bottom-up perception are combined to produce the code representing an observation. Empirically, we demonstrate that the adaptive memory significantly improves generative models trained on both the Omniglot and CIFAR datasets. Compared with the Differentiable Neural Computer (DNC) and its variants, our memory model has greater capacity and is significantly easier to train.
tl;dr: We conduct adversarial attacks against binarized neural networks and show that we reduce the impact of the strongest attacks, while maintaining comparable accuracy in a black-box setting

Neural networks with low-precision weights and activations offer compelling
efficiency advantages over their full-precision equivalents. The two most
frequently discussed benefits of quantization are reduced memory consumption,
and a faster forward pass when implemented with efficient bitwise
operations. We propose a third benefit of very low-precision neural networks:
improved robustness against some adversarial attacks, and in the worst case,
performance that is on par with full-precision models. We focus on the very
low-precision case where weights and activations are both quantized to $\pm$1,
and note that stochastically quantizing weights in just one layer can sharply
reduce the impact of iterative attacks. We observe that non-scaled binary neural
networks exhibit a similar effect to the original \emph{defensive distillation}
procedure that led to \emph{gradient masking}, and a false notion of security.
We address this by conducting both black-box and white-box experiments with
binary models that do not artificially mask gradients.
tl;dr: We introduce the first NMT model with fully parallel decoding, reducing inference latency by 10x.

Existing approaches to neural machine translation condition each output word on previously generated outputs. We introduce a model that avoids this autoregressive property and produces its outputs in parallel, allowing an order of magnitude lower latency during inference. Through knowledge distillation, the use of input token fertilities as a latent variable, and policy gradient fine-tuning, we achieve this at a cost of as little as 2.0 BLEU points relative to the autoregressive Transformer network used as a teacher. We demonstrate substantial cumulative improvements associated with each of the three aspects of our training strategy, and validate our approach on IWSLT 2016 English–German and two WMT language pairs. By sampling fertilities in parallel at inference time, our non-autoregressive model achieves near-state-of-the-art performance of 29.8 BLEU on WMT 2016 English–Romanian.
tl;dr: An extension of GANs combining optimal transport in primal form with an energy distance defined in an adversarially learned feature space.

We present Optimal Transport GAN (OT-GAN), a variant of generative adversarial nets minimizing a new metric measuring the distance between the generator distribution and the data distribution. This metric, which we call mini-batch energy distance, combines optimal transport in primal form with an energy distance defined in an adversarially learned feature space, resulting in a highly discriminative distance function with unbiased mini-batch gradients. Experimentally we show OT-GAN to be highly stable when trained with large mini-batches, and we present state-of-the-art results on several popular benchmark problems for image generation.
tl;dr: Improving recommendations using time sensitive modeling with neural networks in multiple product categories on a retail website

We present a personalized recommender system using neural network for recommending
products, such as eBooks, audio-books, Mobile Apps, Video and Music.
It produces recommendations based on customer’s implicit feedback history such
as purchases, listens or watches. Our key contribution is to formulate recommendation
problem as a model that encodes historical behavior to predict the future
behavior using soft data split, combining predictor and auto-encoder models. We
introduce convolutional layer for learning the importance (time decay) of the purchases
depending on their purchase date and demonstrate that the shape of the time
decay function can be well approximated by a parametrical function. We present
offline experimental results showing that neural networks with two hidden layers
can capture seasonality changes, and at the same time outperform other modeling
techniques, including our recommender in production. Most importantly, we
demonstrate that our model can be scaled to all digital categories, and we observe
significant improvements in an online A/B test. We also discuss key enhancements
to the neural network model and describe our production pipeline. Finally
we open-sourced our deep learning library which supports multi-gpu model parallel
training. This is an important feature in building neural network based recommenders
with large dimensionality of input and output data.
tl;dr: We propose a generalization of visit-counters that evaluate the propagating exploratory value over trajectories, enabling efficient exploration for model-free RL

Exploration is a fundamental aspect of Reinforcement Learning, typically implemented using stochastic action-selection. Exploration, however, can be more efficient if directed toward gaining new world knowledge. Visit-counters have been proven useful both in practice and in theory for directed exploration. However, a major limitation of counters is their locality. While there are a few model-based solutions to this shortcoming, a model-free approach is still missing.
We propose $E$-values, a generalization of counters that can be used to evaluate the propagating exploratory value over state-action trajectories. We compare our approach to commonly used RL techniques, and show that using $E$-values improves learning and performance over traditional counters. We also show how our method can be implemented with function approximation to efficiently learn continuous MDPs. We demonstrate this by showing that our approach surpasses state of the art performance in the Freeway Atari 2600 game.
tl;dr: We extend the K-FAC method to RNNs by developing a new family of Fisher approximations.

Kronecker-factor Approximate Curvature (Martens & Grosse, 2015) (K-FAC) is a 2nd-order optimization method which has been shown to give state-of-the-art performance on large-scale neural network optimization tasks (Ba et al., 2017). It is based on an approximation to the Fisher information matrix (FIM) that makes assumptions about the particular structure of the network and the way it is parameterized. The original K-FAC method was applicable only to fully-connected networks, although it has been recently extended by Grosse & Martens (2016) to handle convolutional networks as well. In this work we extend the method to handle RNNs by introducing a novel approximation to the FIM for RNNs. This approximation works by modelling the covariance structure between the gradient contributions at different time-steps using a chain-structured linear Gaussian graphical model, summing the various cross-covariances, and computing the inverse in closed form. We demonstrate in experiments that our method significantly outperforms general purpose state-of-the-art optimizers like SGD with momentum and Adam on several challenging RNN training tasks.
tl;dr: Training binary/ternary networks using local reparameterization with the CLT approximation

Recent breakthroughs in computer vision make use of large deep neural networks, utilizing the substantial speedup offered by GPUs. For applications running on limited hardware, however, high precision real-time processing can still be a challenge. One approach to solving this problem is training networks with binary or ternary weights, thus removing the need to calculate multiplications and significantly reducing memory size. In this work, we introduce LR-nets (Local reparameterization networks), a new method for training neural networks with discrete weights using stochastic parameters. We show how a simple modification to the local reparameterization trick, previously used to train Gaussian distributed weights, enables the training of discrete weights. Using the proposed training we test both binary and ternary models on MNIST, CIFAR-10 and ImageNet benchmarks and reach state-of-the-art results on most experiments.
tl;dr: SD-GANs disentangle latent codes according to known commonalities in a dataset (e.g. photographs depicting the same person).

We propose a new algorithm for training generative adversarial networks to jointly learn latent codes for both identities (e.g. individual humans) and observations (e.g. specific photographs). In practice, this means that by fixing the identity portion of latent codes, we can generate diverse images of the same subject, and by fixing the observation portion we can traverse the manifold of subjects while maintaining contingent aspects such as lighting and pose. Our algorithm features a pairwise training scheme in which each sample from the generator consists of two images with a common identity code. Corresponding samples from the real dataset consist of two distinct photographs of the same subject. In order to fool the discriminator, the generator must produce images that are both photorealistic, distinct, and appear to depict the same person. We augment both the DCGAN and BEGAN approaches with Siamese discriminators to accommodate pairwise training. Experiments with human judges and an off-the-shelf face verification system demonstrate our algorithm’s ability to generate convincing, identity-matched photographs.
tl;dr: We present general closed loop analysis for Markov potential games and show that deep reinforcement learning can be used for learning approximate closed-loop Nash equilibrium.

Multiagent systems where the agents interact among themselves and with an stochastic environment can be formalized as stochastic games. We study a subclass of these games, named Markov potential games (MPGs), that appear often in economic and engineering applications when the agents share some common resource. We consider MPGs with continuous state-action variables, coupled constraints and nonconvex rewards. Previous analysis followed a variational approach that is only valid for very simple cases (convex rewards, invertible dynamics, and no coupled constraints); or considered deterministic dynamics and provided open-loop (OL) analysis, studying strategies that consist in predefined action sequences, which are not optimal for stochastic environments. We present a closed-loop (CL) analysis for MPGs and consider parametric policies that depend on the current state and where agents adapt to stochastic transitions. We provide easily verifiable, sufficient and necessary conditions for a stochastic game to be an MPG, even for complex parametric functions (e.g., deep neural networks); and show that a closed-loop Nash equilibrium (NE) can be found (or at least approximated) by solving a related optimal control problem (OCP). This is useful since solving an OCP---which is a single-objective problem---is usually much simpler than solving the original set of coupled OCPs that form the game---which is a multiobjective control problem. This is a considerable improvement over the previously standard approach for the CL analysis of MPGs, which gives no approximate solution if no NE belongs to the chosen parametric family, and which is practical only for simple parametric forms. We illustrate the theoretical contributions with an example by applying our approach to a noncooperative communications engineering game. We then solve the game with a deep reinforcement learning algorithm that learns policies that closely approximates an exact variational NE of the game.
tl;dr: Few-shot learning PixelCNN

Deep autoregressive models have shown state-of-the-art performance in density estimation for natural images on large-scale datasets such as ImageNet. However, such models require many thousands of gradient-based weight updates and unique image examples for training. Ideally, the models would rapidly learn visual concepts from only a handful of examples, similar to the manner in which humans learns across many vision tasks. In this paper, we show how 1) neural attention and 2) meta learning techniques can be used in combination with autoregressive models to enable effective few-shot density estimation. Our proposed modifications to PixelCNN result in state-of-the art few-shot density estimation on the Omniglot dataset. Furthermore, we visualize the learned attention policy and find that it learns intuitive algorithms for simple tasks such as image mirroring on ImageNet and handwriting on Omniglot without supervision. Finally, we extend the model to natural images and demonstrate few-shot image generation on the Stanford Online Products dataset.
tl;dr: Depthwise separable convolutions improve neural machine translation: the more separable the better.

Depthwise separable convolutions reduce the number of parameters and computation used in convolutional operations while increasing representational efficiency.
They have been shown to be successful in image classification models, both in obtaining better models than previously possible for a given parameter count (the Xception architecture) and considerably reducing the number of parameters required to perform at a given level (the MobileNets family of architectures). Recently, convolutional sequence-to-sequence networks have been applied to machine translation tasks with good results. In this work, we study how depthwise separable convolutions can be applied to neural machine translation. We introduce a new architecture inspired by Xception and ByteNet, called SliceNet, which enables a significant reduction of the parameter count and amount of computation needed to obtain results like ByteNet, and, with a similar parameter count, achieves better results.
In addition to showing that depthwise separable convolutions perform well for machine translation, we investigate the architectural changes that they enable: we observe that thanks to depthwise separability, we can increase the length of convolution windows, removing the need for filter dilation. We also introduce a new super-separable convolution operation that further reduces the number of parameters and computational cost of the models.
tl;dr: Memory Augmented Network to plan in partially observable environments.

Planning problems in partially observable environments cannot be solved directly with convolutional networks and require some form of memory. But, even memory networks with sophisticated addressing schemes are unable to learn intelligent reasoning satisfactorily due to the complexity of simultaneously learning to access memory and plan. To mitigate these challenges we propose the Memory Augmented Control Network (MACN). The network splits planning into a hierarchical process. At a lower level, it learns to plan in a locally observed space. At a higher level, it uses a collection of policies computed on locally observed spaces to learn an optimal plan in the global environment it is operating in. The performance of the network is evaluated on path planning tasks in environments in the presence of simple and complex obstacles and in addition, is tested for its ability to generalize to new environments not seen in the training set.
tl;dr: This paper formalises the problem of online algorithm selection in the context of Reinforcement Learning.

This paper formalises the problem of online algorithm selection in the context of Reinforcement Learning (RL). The setup is as follows: given an episodic task and a finite number of off-policy RL algorithms, a meta-algorithm has to decide which RL algorithm is in control during the next episode so as to maximize the expected return. The article presents a novel meta-algorithm, called Epochal Stochastic Bandit Algorithm Selection (ESBAS). Its principle is to freeze the policy updates at each epoch, and to leave a rebooted stochastic bandit in charge of the algorithm selection. Under some assumptions, a thorough theoretical analysis demonstrates its near-optimality considering the structural sampling budget limitations. ESBAS is first empirically evaluated on a dialogue task where it is shown to outperform each individual algorithm in most configurations. ESBAS is then adapted to a true online setting where algorithms update their policies after each transition, which we call SSBAS. SSBAS is evaluated on a fruit collection task where it is shown to adapt the stepsize parameter more efficiently than the classical hyperbolic decay, and on an Atari game, where it improves the performance by a wide margin.
tl;dr: SGD implicitly performs variational inference; gradient noise is highly non-isotropic, so SGD does not even converge to critical points of the original loss

Stochastic gradient descent (SGD) is widely believed to perform implicit regularization when used to train deep neural networks, but the precise manner in which this occurs has thus far been elusive. We prove that SGD minimizes an average potential over the posterior distribution of weights along with an entropic regularization term. This potential is however not the original loss function in general. So SGD does perform variational inference, but for a different loss than the one used to compute the gradients. Even more surprisingly, SGD does not even converge in the classical sense: we show that the most likely trajectories of SGD for deep networks do not behave like Brownian motion around critical points. Instead, they resemble closed loops with deterministic components. We prove that such out-of-equilibrium behavior is a consequence of highly non-isotropic gradient noise in SGD; the covariance matrix of mini-batch gradients for deep networks has a rank as small as 1% of its dimension. We provide extensive empirical validation of these claims, proven in the appendix.
tl;dr: Letting a meta-learner decide the task to train on for an agent in a multi-task setting improves multi-tasking ability substantially

One of the long-standing challenges in Artificial Intelligence for learning goal-directed behavior is to build a single agent which can solve multiple tasks. Recent progress in multi-task learning for goal-directed sequential problems has been in the form of distillation based learning wherein a student network learns from multiple task-specific expert networks by mimicking the task-specific policies of the expert networks. While such approaches offer a promising solution to the multi-task learning problem, they require supervision from large expert networks which require extensive data and computation time for training.
In this work, we propose an efficient multi-task learning framework which solves multiple goal-directed tasks in an on-line setup without the need for expert supervision. Our work uses active learning principles to achieve multi-task learning by sampling the harder tasks more than the easier ones. We propose three distinct models under our active sampling framework. An adaptive method with extremely competitive multi-tasking performance. A UCB-based meta-learner which casts the problem of picking the next task to train on as a multi-armed bandit problem. A meta-learning method that casts the next-task picking problem as a full Reinforcement Learning problem and uses actor-critic methods for optimizing the multi-tasking performance directly. We demonstrate results in the Atari 2600 domain on seven multi-tasking instances: three 6-task instances, one 8-task instance, two 12-task instances and one 21-task instance.
tl;dr: We prove that deep neural networks are exponentially more efficient than shallow ones at approximating sparse multivariate polynomials.

It is well-known that neural networks are universal approximators, but that deeper networks tend in practice to be more powerful than shallower ones. We shed light on this by proving that the total number of neurons m required to approximate natural classes of multivariate polynomials of n variables grows only linearly with n for deep neural networks, but grows exponentially when merely a single hidden layer is allowed. We also provide evidence that when the number of hidden layers is increased from 1 to k, the neuron requirement grows exponentially not with n but with n^{1/k}, suggesting that the minimum number of layers required for practical expressibility grows only logarithmically with n.
tl;dr: Training an agent in a 2D virtual world for grounded language acquisition and generalization.

We build a virtual agent for learning language in a 2D maze-like world. The agent sees images of the surrounding environment, listens to a virtual teacher, and takes actions to receive rewards. It interactively learns the teacher’s language from scratch based on two language use cases: sentence-directed navigation and question answering. It learns simultaneously the visual representations of the world, the language, and the action control. By disentangling language grounding from other computational routines and sharing a concept detection function between language grounding and prediction, the agent reliably interpolates and extrapolates to interpret sentences that contain new word combinations or new words missing from training sentences. The new words are transferred from the answers of language prediction. Such a language ability is trained and evaluated on a population of over 1.6 million distinct sentences consisting of 119 object words, 8 color words, 9 spatial-relation words, and 50 grammatical words. The proposed model significantly outperforms five comparison methods for interpreting zero-shot sentences. In addition, we demonstrate human-interpretable intermediate outputs of the model in the appendix.

We compare and analyze sequential, random access, and stack memory architectures for recurrent neural network language models. Our experiments on the Penn Treebank and Wikitext-2 datasets show that stack-based memory architectures consistently achieve the best performance in terms of held out perplexity. We also propose a generalization to existing continuous stack models (Joulin & Mikolov,2015; Grefenstette et al., 2015) to allow a variable number of pop operations more naturally that further improves performance. We further evaluate these language models in terms of their ability to capture non-local syntactic dependencies on a subject-verb agreement dataset (Linzen et al., 2016) and establish new state of the art results using memory augmented language models. Our results demonstrate the value of stack-structured memory for explaining the distribution of words in natural language, in line with linguistic theories claiming a context-free backbone for natural language.

We propose an approach to address two issues that commonly occur during training of unsupervised GANs. First, since GANs use only a continuous latent distribution to embed multiple classes or clusters of data, they often do not correctly handle the structural discontinuity between disparate classes in a latent space. Second, discriminators of GANs easily forget about past generated samples by generators, incurring instability during adversarial training. We argue that these two infamous problems of unsupervised GAN training can be largely alleviated by a learnable memory network to which both generators and discriminators can access. Generators can effectively learn representation of training samples to understand underlying cluster distributions of data, which ease the structure discontinuity problem. At the same time, discriminators can better memorize clusters of previously generated samples, which mitigate the forgetting problem. We propose a novel end-to-end GAN model named memoryGAN, which involves a memory network that is unsupervisedly trainable and integrable to many existing GAN models. With evaluations on multiple datasets such as Fashion-MNIST, CelebA, CIFAR10, and Chairs, we show that our model is probabilistically interpretable, and generates realistic image samples of high visual fidelity. The memoryGAN also achieves the state-of-the-art inception scores over unsupervised GAN models on the CIFAR10 dataset, without any optimization tricks and weaker divergences.
tl;dr: We propose a DRL framework that disentangles task and environment specific knowledge.

Recent state-of-the-art reinforcement learning algorithms are trained under the goal of excelling in one specific task. Hence, both environment and task specific knowledge are entangled into one framework. However, there are often scenarios where the environment (e.g. the physical world) is fixed while only the target task changes. Hence, borrowing the idea from hierarchical reinforcement learning, we propose a framework that disentangles task and environment specific knowledge by separating them into two units. The environment-specific unit handles how to move from one state to the target state; and the task-specific unit plans for the next target state given a specific task. The extensive results in simulators indicate that our method can efficiently separate and learn two independent units, and also adapt to a new task more efficiently than the state-of-the-art methods.
tl;dr: We find evidence that divergence minimization may not be an accurate characterization of GAN training.

Generative adversarial networks (GANs) are a family of generative models that do not minimize a single training criterion. Unlike other generative models, the data distribution is learned via a game between a generator (the generative model) and a discriminator (a teacher providing training signal) that each minimize their own cost. GANs are designed to reach a Nash equilibrium at which each player cannot reduce their cost without changing the other players’ parameters. One useful approach for the theory of GANs is to show that a divergence between the training distribution and the model distribution obtains its minimum value at equilibrium. Several recent research directions have been motivated by the idea that this divergence is the primary guide for the learning process and that every step of learning should decrease the divergence. We show that this view is overly restrictive. During GAN training, the discriminator provides learning signal in situations where the gradients of the divergences between distributions would not be useful. We provide empirical counterexamples to the view of GAN training as divergence minimization. Specifically, we demonstrate that GANs are able to learn distributions in situations where the divergence minimization point of view predicts they would fail. We also show that gradient penalties motivated from the divergence minimization perspective are equally helpful when applied in other contexts in which the divergence minimization perspective does not predict they would be helpful. This contributes to a growing body of evidence that GAN training may be more usefully viewed as approaching Nash equilibria via trajectories that do not necessarily minimize a specific divergence at each step.
tl;dr: Lowering precision (to 4-bits, 2-bits and even binary) and widening the filter banks gives as accurate network as those obtained with FP32 weights and activations.

For computer vision applications, prior works have shown the efficacy of reducing numeric precision of model parameters (network weights) in deep neural networks. Activation maps, however, occupy a large memory footprint during both the training and inference step when using mini-batches of inputs. One way to reduce this large memory footprint is to reduce the precision of activations. However, past works have shown that reducing the precision of activations hurts model accuracy. We study schemes to train networks from scratch using reduced-precision activations without hurting accuracy. We reduce the precision of activation maps (along with model parameters) and increase the number of filter maps in a layer, and find that this scheme matches or surpasses the accuracy of the baseline full-precision network. As a result, one can significantly improve the execution efficiency (e.g. reduce dynamic memory footprint, memory band- width and computational energy) and speed up the training and inference process with appropriate hardware support. We call our scheme WRPN -- wide reduced-precision networks. We report results and show that WRPN scheme is better than previously reported accuracies on ILSVRC-12 dataset while being computationally less expensive compared to previously reported reduced-precision networks.

Neural programming involves training neural networks to learn programs, mathematics, or logic from data. Previous works have failed to achieve good generalization performance, especially on problems and programs with high complexity or on large domains. This is because they mostly rely either on black-box function evaluations that do not capture the structure of the program, or on detailed execution traces that are expensive to obtain, and hence the training data has poor coverage of the domain under consideration. We present a novel framework that utilizes black-box function evaluations, in conjunction with symbolic expressions that define relationships between the given functions. We employ tree LSTMs to incorporate the structure of the symbolic expression trees. We use tree encoding for numbers present in function evaluation data, based on their decimal representation. We present an evaluation benchmark for this task to demonstrate our proposed model combines symbolic reasoning and function evaluation in a fruitful manner, obtaining high accuracies in our experiments. Our framework generalizes significantly better to expressions of higher depth and is able to fill partial equations with valid completions.
tl;dr: Coulomb GANs can optimally learn a distribution by posing the distribution learning problem as optimizing a potential field

Generative adversarial networks (GANs) evolved into one of the most successful unsupervised techniques for generating realistic images. Even though it has recently been shown that GAN training converges, GAN models often end up in local Nash equilibria that are associated with mode collapse or otherwise fail to model the target distribution. We introduce Coulomb GANs, which pose the GAN learning problem as a potential field, where generated samples are attracted to training set samples but repel each other. The discriminator learns a potential field while the generator decreases the energy by moving its samples along the vector (force) field determined by the gradient of the potential field. Through decreasing the energy, the GAN model learns to generate samples according to the whole target distribution and does not only cover some of its modes. We prove that Coulomb GANs possess only one Nash equilibrium which is optimal in the sense that the model distribution equals the target distribution. We show the efficacy of Coulomb GANs on LSUN bedrooms, CelebA faces, CIFAR-10 and the Google Billion Word text generation.

Convolutional neural networks have demonstrated high accuracy on various tasks in recent years. However, they are extremely vulnerable to adversarial examples. For example, imperceptible perturbations added to clean images can cause convolutional neural networks to fail. In this paper, we propose to utilize randomization at inference time to mitigate adversarial effects. Specifically, we use two randomization operations: random resizing, which resizes the input images to a random size, and random padding, which pads zeros around the input images in a random manner. Extensive experiments demonstrate that the proposed randomization method is very effective at defending against both single-step and iterative attacks. Our method provides the following advantages: 1) no additional training or fine-tuning, 2) very few additional computations, 3) compatible with other adversarial defense methods. By combining the proposed randomization method with an adversarially trained model, it achieves a normalized score of 0.924 (ranked No.2 among 107 defense teams) in the NIPS 2017 adversarial examples defense challenge, which is far better than using adversarial training alone with a normalized score of 0.773 (ranked No.56). The code is public available at https://github.com/cihangxie/NIPS2017_adv_challenge_defense.

Reinforcement learning algorithms can train agents that solve problems in complex, interesting environments. Normally, the complexity of the trained agent is closely related to the complexity of the environment. This suggests that a highly capable agent requires a complex environment for training. In this paper, we point out that a competitive multi-agent environment trained with self-play can produce behaviors that are far more complex than the environment itself. We also point out that such environments come with a natural curriculum, because for any skill level, an environment full of agents of this level will have the right level of difficulty.
This work introduces several competitive multi-agent environments where agents compete in a 3D world with simulated physics. The trained agents learn a wide variety of complex and interesting skills, even though the environment themselves are relatively simple. The skills include behaviors such as running, blocking, ducking, tackling, fooling opponents, kicking, and defending using both arms and legs. A highlight of the learned behaviors can be found here: https://goo.gl/eR7fbX
tl;dr: We propose a framework to generate “natural” adversaries against black-box classifiers for both visual and textual domains, by doing the search for adversaries in the latent semantic space.

Due to their complex nature, it is hard to characterize the ways in which machine learning models can misbehave or be exploited when deployed. Recent work on adversarial examples, i.e. inputs with minor perturbations that result in substantially different model predictions, is helpful in evaluating the robustness of these models by exposing the adversarial scenarios where they fail. However, these malicious perturbations are often unnatural, not semantically meaningful, and not applicable to complicated domains such as language. In this paper, we propose a framework to generate natural and legible adversarial examples that lie on the data manifold, by searching in semantic space of dense and continuous data representation, utilizing the recent advances in generative adversarial networks. We present generated adversaries to demonstrate the potential of the proposed approach for black-box classifiers for a wide range of applications such as image classification, textual entailment, and machine translation. We include experiments to show that the generated adversaries are natural, legible to humans, and useful in evaluating and analyzing black-box classifiers.
tl;dr: Training on convex combinations between random training examples and their labels improves generalization in deep neural networks

Large deep neural networks are powerful, but exhibit undesirable behaviors such as memorization and sensitivity to adversarial examples. In this work, we propose mixup, a simple learning principle to alleviate these issues. In essence, mixup trains a neural network on convex combinations of pairs of examples and their labels. By doing so, mixup regularizes the neural network to favor simple linear behavior in-between training examples. Our experiments on the ImageNet-2012, CIFAR-10, CIFAR-100, Google commands and UCI datasets show that mixup improves the generalization of state-of-the-art neural network architectures. We also find that mixup reduces the memorization of corrupt labels, increases the robustness to adversarial examples, and stabilizes the training of generative adversarial networks.
tl;dr: We propose a novel, projection based way to incorporate the conditional information into the discriminator of GANs that respects the role of the conditional information in the underlining probabilistic model.

We propose a novel, projection based way to incorporate the conditional information into the discriminator of GANs that respects the role of the conditional information in the underlining probabilistic model.
This approach is in contrast with most frameworks of conditional GANs used in application today, which use the conditional information by concatenating the (embedded) conditional vector to the feature vectors.
With this modification, we were able to significantly improve the quality of the class conditional image generation on ILSVRC2012 (ImageNet) dataset from the current state-of-the-art result, and we achieved this with a single pair of a discriminator and a generator.
We were also able to extend the application to super-resolution and succeeded in producing highly discriminative super-resolution images.
This new structure also enabled high quality category transformation based on parametric functional transformation of conditional batch normalization layers in the generator.
tl;dr: Decaying the learning rate and increasing the batch size during training are equivalent.
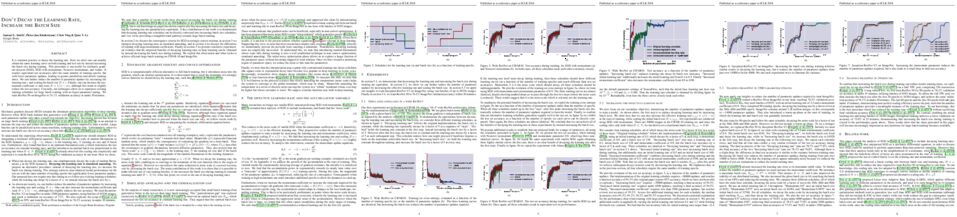
It is common practice to decay the learning rate. Here we show one can usually obtain the same learning curve on both training and test sets by instead increasing the batch size during training. This procedure is successful for stochastic gradient descent (SGD), SGD with momentum, Nesterov momentum, and Adam. It reaches equivalent test accuracies after the same number of training epochs, but with fewer parameter updates, leading to greater parallelism and shorter training times. We can further reduce the number of parameter updates by increasing the learning rate $\epsilon$ and scaling the batch size $B \propto \epsilon$. Finally, one can increase the momentum coefficient $m$ and scale $B \propto 1/(1-m)$, although this tends to slightly reduce the test accuracy. Crucially, our techniques allow us to repurpose existing training schedules for large batch training with no hyper-parameter tuning. We train ResNet-50 on ImageNet to 76.1% validation accuracy in under 30 minutes.
tl;dr: We propose the Warped Residual Network using a parallelizable warp operator for forward and backward propagation to distant layers that trains faster than the original residual neural network.

We propose a Warped Residual Network (WarpNet) using a parallelizable warp operator for forward and backward propagation to distant layers that trains faster than the original residual neural network. We apply a perturbation theory on residual networks and decouple the interactions between residual units. The resulting warp operator is a first order approximation of the output over multiple layers. The first order perturbation theory exhibits properties such as binomial path lengths and exponential gradient scaling found experimentally by Veit et al (2016).
We demonstrate through an extensive performance study that the proposed network achieves comparable predictive performance to the original residual network with the same number of parameters, while achieving a significant speed-up on the total training time. As WarpNet performs model parallelism in residual network training in which weights are distributed over different GPUs, it offers speed-up and capability to train larger networks compared to original residual networks.
tl;dr: Deep autoencoders to learn a good representation for geometric 3D point-cloud data; Generative models for point clouds.

Three-dimensional geometric data offer an excellent domain for studying representation learning and generative modeling. In this paper, we look at geometric data represented as point clouds. We introduce a deep autoencoder (AE) network with excellent reconstruction quality and generalization ability. The learned representations outperform the state of the art in 3D recognition tasks and enable basic shape editing applications via simple algebraic manipulations, such as semantic part editing, shape analogies and shape interpolation. We also perform a thorough study of different generative models including GANs operating on the raw point clouds, significantly improved GANs trained in the fixed latent space our AEs and, Gaussian mixture models (GMM). Interestingly, GMMs trained in the latent space of our AEs produce samples of the best fidelity and diversity.
To perform our quantitative evaluation of generative models, we propose simple measures of fidelity and diversity based on optimally matching between sets point clouds.

We present Deep Voice 3, a fully-convolutional attention-based neural text-to-speech (TTS) system. Deep Voice 3 matches state-of-the-art neural speech synthesis systems in naturalness while training an order of magnitude faster. We scale Deep Voice 3 to dataset sizes unprecedented for TTS, training on more than eight hundred hours of audio from over two thousand speakers. In addition, we identify common error modes of attention-based speech synthesis networks, demonstrate how to mitigate them, and compare several different waveform synthesis methods. We also describe how to scale inference to ten million queries per day on a single GPU server.
tl;dr: Using a simple language-driven navigation task, we study the compositional capabilities of modern seq2seq recurrent networks.

Humans can understand and produce new utterances effortlessly, thanks to their systematic compositional skills. Once a person learns the meaning of a new verb "dax," he or she can immediately understand the meaning of "dax twice" or "sing and dax." In this paper, we introduce the SCAN domain, consisting of a set of simple compositional navigation commands paired with the corresponding action sequences. We then test the zero-shot generalization capabilities of a variety of recurrent neural networks (RNNs) trained on SCAN with sequence-to-sequence methods. We find that RNNs can generalize well when the differences between training and test commands are small, so that they can apply "mix-and-match" strategies to solve the task. However, when generalization requires systematic compositional skills (as in the "dax" example above), RNNs fail spectacularly. We conclude with a proof-of-concept experiment in neural machine translation, supporting the conjecture that lack of systematicity is an important factor explaining why neural networks need very large training sets.
tl;dr: We propose an adversarial inverse reinforcement learning algorithm capable of learning reward functions which can transfer to new, unseen environments.

Reinforcement learning provides a powerful and general framework for decision
making and control, but its application in practice is often hindered by the need
for extensive feature and reward engineering. Deep reinforcement learning methods
can remove the need for explicit engineering of policy or value features, but
still require a manually specified reward function. Inverse reinforcement learning
holds the promise of automatic reward acquisition, but has proven exceptionally
difficult to apply to large, high-dimensional problems with unknown dynamics. In
this work, we propose AIRL, a practical and scalable inverse reinforcement learning
algorithm based on an adversarial reward learning formulation that is competitive
with direct imitation learning algorithms. Additionally, we show that AIRL is
able to recover portable reward functions that are robust to changes in dynamics,
enabling us to learn policies even under significant variation in the environment
seen during training.

Recent progress in variational inference has paid much attention to the flexibility of variational posteriors. One promising direction is to use implicit distributions, i.e., distributions without tractable densities as the variational posterior. However, existing methods on implicit posteriors still face challenges of noisy estimation and computational infeasibility when applied to models with high-dimensional latent variables. In this paper, we present a new approach named Kernel Implicit Variational Inference that addresses these challenges. As far as we know, for the first time implicit variational inference is successfully applied to Bayesian neural networks, which shows promising results on both regression and classification tasks.
tl;dr: We apply a model-agnostic defense strategy against adversarial examples and achieve 60% white-box accuracy and 90% black-box accuracy against major attack algorithms.

This paper investigates strategies that defend against adversarial-example attacks on image-classification systems by transforming the inputs before feeding them to the system. Specifically, we study applying image transformations such as bit-depth reduction, JPEG compression, total variance minimization, and image quilting before feeding the image to a convolutional network classifier. Our experiments on ImageNet show that total variance minimization and image quilting are very effective defenses in practice, in particular, when the network is trained on transformed images. The strength of those defenses lies in their non-differentiable nature and their inherent randomness, which makes it difficult for an adversary to circumvent the defenses. Our best defense eliminates 60% of strong gray-box and 90% of strong black-box attacks by a variety of major attack methods.
tl;dr: Improving Predictive State Recurrent Neural Networks via Orthogonal Random Features

Learning to predict complex time-series data is a fundamental challenge in a range of disciplines including Machine Learning, Robotics, and Natural Language Processing. Predictive State Recurrent Neural Networks (PSRNNs) (Downey et al.) are a state-of-the-art approach for modeling time-series data which combine the benefits of probabilistic filters and Recurrent Neural Networks into a single model. PSRNNs leverage the concept of Hilbert Space Embeddings of distributions (Smola et al.) to embed predictive states into a Reproducing Kernel Hilbert Space, then estimate, predict, and update these embedded states using Kernel Bayes Rule. Practical implementations of PSRNNs are made possible by the machinery of Random Features, where input features are mapped into a new space where dot products approximate the kernel well. Unfortunately PSRNNs often require a large number of RFs to obtain good results, resulting in large models which are slow to execute and slow to train. Orthogonal Random Features (ORFs) (Choromanski et al.) is an improvement on RFs which has been shown to decrease the number of RFs required for pointwise kernel approximation. Unfortunately, it is not clear that ORFs can be applied to PSRNNs, as PSRNNs rely on Kernel Ridge Regression as a core component of their learning algorithm, and the theoretical guarantees of ORF do not apply in this setting. In this paper, we extend the theory of ORFs to Kernel Ridge Regression and show that ORFs can be used to obtain Orthogonal PSRNNs (OPSRNNs), which are smaller and faster than PSRNNs. In particular, we show that OPSRNN models clearly outperform LSTMs and furthermore, can achieve accuracy similar to PSRNNs with an order of magnitude smaller number of features needed.
tl;dr: We show how to optimize the expected L_0 norm of parametric models with gradient descent and introduce a new distribution that facilitates hard gating.

We propose a practical method for $L_0$ norm regularization for neural networks: pruning the network during training by encouraging weights to become exactly zero. Such regularization is interesting since (1) it can greatly speed up training and inference, and (2) it can improve generalization. AIC and BIC, well-known model selection criteria, are special cases of $L_0$ regularization. However, since the $L_0$ norm of weights is non-differentiable, we cannot incorporate it directly as a regularization term in the objective function. We propose a solution through the inclusion of a collection of non-negative stochastic gates, which collectively determine which weights to set to zero. We show that, somewhat surprisingly, for certain distributions over the gates, the expected $L_0$ regularized objective is differentiable with respect to the distribution parameters. We further propose the \emph{hard concrete} distribution for the gates, which is obtained by ``stretching'' a binary concrete distribution and then transforming its samples with a hard-sigmoid. The parameters of the distribution over the gates can then be jointly optimized with the original network parameters. As a result our method allows for straightforward and efficient learning of model structures with stochastic gradient descent and allows for conditional computation in a principled way. We perform various experiments to demonstrate the effectiveness of the resulting approach and regularizer.
tl;dr: Querying a black-box neural network reveals a lot of information about it; we propose novel "metamodels" for effectively extracting information from a black box.

Many deployed learned models are black boxes: given input, returns output. Internal information about the model, such as the architecture, optimisation procedure, or training data, is not disclosed explicitly as it might contain proprietary information or make the system more vulnerable. This work shows that such attributes of neural networks can be exposed from a sequence of queries. This has multiple implications. On the one hand, our work exposes the vulnerability of black-box neural networks to different types of attacks -- we show that the revealed internal information helps generate more effective adversarial examples against the black box model. On the other hand, this technique can be used for better protection of private content from automatic recognition models using adversarial examples. Our paper suggests that it is actually hard to draw a line between white box and black box models.
tl;dr: Conditional GANs trained to generate data augmented samples of their conditional inputs used to enhance vanilla classification and one shot learning systems such as matching networks and pixel distance

Effective training of neural networks requires much data. In the low-data regime,
parameters are underdetermined, and learnt networks generalise poorly. Data
Augmentation (Krizhevsky et al., 2012) alleviates this by using existing data
more effectively. However standard data augmentation produces only limited
plausible alternative data. Given there is potential to generate a much broader set
of augmentations, we design and train a generative model to do data augmentation.
The model, based on image conditional Generative Adversarial Networks, takes
data from a source domain and learns to take any data item and generalise it
to generate other within-class data items. As this generative process does not
depend on the classes themselves, it can be applied to novel unseen classes of data.
We show that a Data Augmentation Generative Adversarial Network (DAGAN)
augments standard vanilla classifiers well. We also show a DAGAN can enhance
few-shot learning systems such as Matching Networks. We demonstrate these
approaches on Omniglot, on EMNIST having learnt the DAGAN on Omniglot, and
VGG-Face data. In our experiments we can see over 13% increase in accuracy in
the low-data regime experiments in Omniglot (from 69% to 82%), EMNIST (73.9%
to 76%) and VGG-Face (4.5% to 12%); in Matching Networks for Omniglot we
observe an increase of 0.5% (from 96.9% to 97.4%) and an increase of 1.8% in
EMNIST (from 59.5% to 61.3%).

We present a new neural text to speech (TTS) method that is able to transform text to speech in voices that are sampled in the wild. Unlike other systems, our solution is able to deal with unconstrained voice samples and without requiring aligned phonemes or linguistic features. The network architecture is simpler than those in the existing literature and is based on a novel shifting buffer working memory. The same buffer is used for estimating the attention, computing the output audio, and for updating the buffer itself. The input sentence is encoded using a context-free lookup table that contains one entry per character or phoneme. The speakers are similarly represented by a short vector that can also be fitted to new identities, even with only a few samples. Variability in the generated speech is achieved by priming the buffer prior to generating the audio. Experimental results on several datasets demonstrate convincing capabilities, making TTS accessible to a wider range of applications. In order to promote reproducibility, we release our source code and models.
tl;dr: A simple architecture consisting of convolutions and attention achieves results on par with the best documented recurrent models.

Current end-to-end machine reading and question answering (Q\&A) models are primarily based on recurrent neural networks (RNNs) with attention. Despite their success, these models are often slow for both training and inference due to the sequential nature of RNNs. We propose a new Q\&A architecture called QANet, which does not require recurrent networks: Its encoder consists exclusively of convolution and self-attention, where convolution models local interactions and self-attention models global interactions. On the SQuAD dataset, our model is 3x to 13x faster in training and 4x to 9x faster in inference, while achieving equivalent accuracy to recurrent models. The speed-up gain allows us to train the model with much more data. We hence combine our model with data generated by backtranslation from a neural machine translation model.
On the SQuAD dataset, our single model, trained with augmented data, achieves 84.6 F1 score on the test set, which is significantly better than the best published F1 score of 81.8.
tl;dr: a simple RNN-based meta-learner that achieves SOTA performance on popular benchmarks

Deep neural networks excel in regimes with large amounts of data, but tend to struggle when data is scarce or when they need to adapt quickly to changes in the task. In response, recent work in meta-learning proposes training a meta-learner on a distribution of similar tasks, in the hopes of generalization to novel but related tasks by learning a high-level strategy that captures the essence of the problem it is asked to solve. However, many recent meta-learning approaches are extensively hand-designed, either using architectures specialized to a particular application, or hard-coding algorithmic components that constrain how the meta-learner solves the task. We propose a class of simple and generic meta-learner architectures that use a novel combination of temporal convolutions and soft attention; the former to aggregate information from past experience and the latter to pinpoint specific pieces of information. In the most extensive set of meta-learning experiments to date, we evaluate the resulting Simple Neural AttentIve Learner (or SNAIL) on several heavily-benchmarked tasks. On all tasks, in both supervised and reinforcement learning, SNAIL attains state-of-the-art performance by significant margins.

The problem of detecting whether a test sample is from in-distribution (i.e., training distribution by a classifier) or out-of-distribution sufficiently different from it arises in many real-world machine learning applications. However, the state-of-art deep neural networks are known to be highly overconfident in their predictions, i.e., do not distinguish in- and out-of-distributions. Recently, to handle this issue, several threshold-based detectors have been proposed given pre-trained neural classifiers. However, the performance of prior works highly depends on how to train the classifiers since they only focus on improving inference procedures. In this paper, we develop a novel training method for classifiers so that such inference algorithms can work better. In particular, we suggest two additional terms added to the original loss (e.g., cross entropy). The first one forces samples from out-of-distribution less confident by the classifier and the second one is for (implicitly) generating most effective training samples for the first one. In essence, our method jointly trains both classification and generative neural networks for out-of-distribution. We demonstrate its effectiveness using deep convolutional neural networks on various popular image datasets.
tl;dr: We present a new pruning method and sparse matrix format to enable high index compression ratio and parallel index decoding process.

Weight pruning has proven to be an effective method in reducing the model size and computation cost while not sacrificing the model accuracy. Conventional sparse matrix formats, however, involve irregular index structures with large storage requirement and sequential reconstruction process, resulting in inefficient use of highly parallel computing resources. Hence, pruning is usually restricted to inference with a batch size of one, for which an efficient parallel matrix-vector multiplication method exists. In this paper, a new class of sparse matrix representation utilizing Viterbi algorithm that has a high, and more importantly, fixed index compression ratio regardless of the pruning rate, is proposed. In this approach, numerous sparse matrix candidates are first generated by the Viterbi encoder, and then the one that aims to minimize the model accuracy degradation is selected by the Viterbi algorithm. The model pruning process based on the proposed Viterbi encoder and Viterbi algorithm is highly parallelizable, and can be implemented efficiently in hardware to achieve low-energy, high-performance index decoding process. Compared with the existing magnitude-based pruning methods, index data storage requirement can be further compressed by 85.2% in MNIST and 83.9% in AlexNet while achieving similar pruning rate. Even compared with the relative index compression technique, our method can still reduce the index storage requirement by 52.7% in MNIST and 35.5% in AlexNet.
tl;dr: We used an LSTM to detect when a smartphone walks into a building. Then we predict the device's floor level using data from sensors aboard the smartphone.

In cities with tall buildings, emergency responders need an accurate floor level location to find 911 callers quickly. We introduce a system to estimate a victim's floor level via their mobile device's sensor data in a two-step process. First, we train a neural network to determine when a smartphone enters or exits a building via GPS signal changes. Second, we use a barometer equipped smartphone to measure the change in barometric pressure from the entrance of the building to the victim's indoor location. Unlike impractical previous approaches, our system is the first that does not require the use of beacons, prior knowledge of the building infrastructure, or knowledge of user behavior. We demonstrate real-world feasibility through 63 experiments across five different tall buildings throughout New York City where our system predicted the correct floor level with 100% accuracy.
tl;dr: We describe a novel multi-view generative model that can generate multiple views of the same object, or multiple objects in the same view with no need of label on views.

The development of high-dimensional generative models has recently gained a great surge of interest with the introduction of variational auto-encoders and generative adversarial neural networks. Different variants have been proposed where the underlying latent space is structured, for example, based on attributes describing the data to generate. We focus on a particular problem where one aims at generating samples corresponding to a number of objects under various views. We assume that the distribution of the data is driven by two independent latent factors: the content, which represents the intrinsic features of an object, and the view, which stands for the settings of a particular observation of that object. Therefore, we propose a generative model and a conditional variant built on such a disentangled latent space. This approach allows us to generate realistic samples corresponding to various objects in a high variety of views. Unlike many multi-view approaches, our model doesn't need any supervision on the views but only on the content. Compared to other conditional generation approaches that are mostly based on binary or categorical attributes, we make no such assumption about the factors of variations. Our model can be used on problems with a huge, potentially infinite, number of categories. We experiment it on four images datasets on which we demonstrate the effectiveness of the model and its ability to generalize.
tl;dr: We introduce a lightweight architecture for named entity recognition and carry out incremental active learning, which is able to match state-of-the-art performance with just 25% of the original training data.

Deep learning has yielded state-of-the-art performance on many natural language processing tasks including named entity recognition (NER). However, this typically requires large amounts of labeled data. In this work, we demonstrate that the amount of labeled training data can be drastically reduced when deep learning is combined with active learning. While active learning is sample-efficient, it can be computationally expensive since it requires iterative retraining. To speed this up, we introduce a lightweight architecture for NER, viz., the CNN-CNN-LSTM model consisting of convolutional character and word encoders and a long short term memory (LSTM) tag decoder. The model achieves nearly state-of-the-art performance on standard datasets for the task while being computationally much more efficient than best performing models. We carry out incremental active learning, during the training process, and are able to nearly match state-of-the-art performance with just 25\% of the original training data.
tl;dr: The paper presents Deep Rewiring, an algorithm that can be used to train deep neural networks when the network connectivity is severely constrained during training.
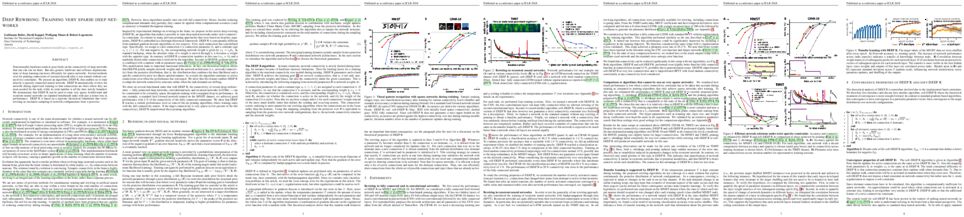
Neuromorphic hardware tends to pose limits on the connectivity of deep networks that one can run on them. But also generic hardware and software implementations of deep learning run more efficiently for sparse networks. Several methods exist for pruning connections of a neural network after it was trained without connectivity constraints. We present an algorithm, DEEP R, that enables us to train directly a sparsely connected neural network. DEEP R automatically rewires the network during supervised training so that connections are there where they are most needed for the task, while its total number is all the time strictly bounded. We demonstrate that DEEP R can be used to train very sparse feedforward and recurrent neural networks on standard benchmark tasks with just a minor loss in performance. DEEP R is based on a rigorous theoretical foundation that views rewiring as stochastic sampling of network configurations from a posterior.
tl;dr: We propose a novel framework to adaptively adjust the dropout rates for the deep neural network based on a Rademacher complexity bound.

We propose a novel framework to adaptively adjust the dropout rates for the deep neural network based on a Rademacher complexity bound. The state-of-the-art deep learning algorithms impose dropout strategy to prevent feature co-adaptation. However, choosing the dropout rates remains an art of heuristics or relies on empirical grid-search over some hyperparameter space. In this work, we show the network Rademacher complexity is bounded by a function related to the dropout rate vectors and the weight coefficient matrices. Subsequently, we impose this bound as a regularizer and provide a theoretical justified way to trade-off between model complexity and representation power. Therefore, the dropout rates and the empirical loss are unified into the same objective function, which is then optimized using the block coordinate descent algorithm. We discover that the adaptively adjusted dropout rates converge to some interesting distributions that reveal meaningful patterns.Experiments on the task of image and document classification also show our method achieves better performance compared to the state-of the-art dropout algorithms.

Recent AI research has emphasised the importance of learning disentangled representations of the explanatory factors behind data. Despite the growing interest in models which can learn such representations, visual inspection remains the standard evaluation metric. While various desiderata have been implied in recent definitions, it is currently unclear what exactly makes one disentangled representation better than another. In this work we propose a framework for the quantitative evaluation of disentangled representations when the ground-truth latent structure is available. Three criteria are explicitly defined and quantified to elucidate the quality of learnt representations and thus compare models on an equal basis. To illustrate the appropriateness of the framework, we employ it to compare quantitatively the representations learned by recent state-of-the-art models.

The rapid adoption of machine learning has increased concerns about the privacy implications of machine learning models trained on sensitive data, such as medical records or other personal information. To address those concerns, one promising approach is Private Aggregation of Teacher Ensembles, or PATE, which transfers to a "student" model the knowledge of an ensemble of "teacher" models, with intuitive privacy provided by training teachers on disjoint data and strong privacy guaranteed by noisy aggregation of teachers’ answers. However, PATE has so far been evaluated only on simple classification tasks like MNIST, leaving unclear its utility when applied to larger-scale learning tasks and real-world datasets.
In this work, we show how PATE can scale to learning tasks with large numbers of output classes and uncurated, imbalanced training data with errors. For this, we introduce new noisy aggregation mechanisms for teacher ensembles that are more selective and add less noise, and prove their tighter differential-privacy guarantees. Our new mechanisms build on two insights: the chance of teacher consensus is increased by using more concentrated noise and, lacking consensus, no answer need be given to a student. The consensus answers used are more likely to be correct, offer better intuitive privacy, and incur lower-differential privacy cost. Our evaluation shows our mechanisms improve on the original PATE on all measures, and scale to larger tasks with both high utility and very strong privacy (ε < 1.0).
tl;dr: Deep representations combined with gradient descent can approximate any learning algorithm.

Learning to learn is a powerful paradigm for enabling models to learn from data more effectively and efficiently. A popular approach to meta-learning is to train a recurrent model to read in a training dataset as input and output the parameters of a learned model, or output predictions for new test inputs. Alternatively, a more recent approach to meta-learning aims to acquire deep representations that can be effectively fine-tuned, via standard gradient descent, to new tasks. In this paper, we consider the meta-learning problem from the perspective of universality, formalizing the notion of learning algorithm approximation and comparing the expressive power of the aforementioned recurrent models to the more recent approaches that embed gradient descent into the meta-learner. In particular, we seek to answer the following question: does deep representation combined with standard gradient descent have sufficient capacity to approximate any learning algorithm? We find that this is indeed true, and further find, in our experiments, that gradient-based meta-learning consistently leads to learning strategies that generalize more widely compared to those represented by recurrent models.

At present, the vast majority of building blocks, techniques, and architectures for deep learning are based on real-valued operations and representations. However, recent work on recurrent neural networks and older fundamental theoretical analysis suggests that complex numbers could have a richer representational capacity and could also facilitate noise-robust memory retrieval mechanisms. Despite their attractive properties and potential for opening up entirely new neural architectures, complex-valued deep neural networks have been marginalized due to the absence of the building blocks required to design such models. In this work, we provide the key atomic components for complex-valued deep neural networks and apply them to convolutional feed-forward networks. More precisely, we rely on complex convolutions and present algorithms for complex batch-normalization, complex weight initialization strategies for complex-valued neural nets and we use them in experiments with end-to-end training schemes. We demonstrate that such complex-valued models are competitive with their real-valued counterparts. We test deep complex models on several computer vision tasks, on music transcription using the MusicNet dataset and on Speech spectrum prediction using TIMIT. We achieve state-of-the-art performance on these audio-related tasks.
tl;dr: This paper 1) characterizes functions representable by ReLU DNNs, 2) formally studies the benefit of depth in such architectures, 3) gives an algorithm to implement empirical risk minimization to global optimality for two layer ReLU nets.

In this paper we investigate the family of functions representable by deep neural networks (DNN) with rectified linear units (ReLU). We give an algorithm to train a ReLU DNN with one hidden layer to {\em global optimality} with runtime polynomial in the data size albeit exponential in the input dimension. Further, we improve on the known lower bounds on size (from exponential to super exponential) for approximating a ReLU deep net function by a shallower ReLU net. Our gap theorems hold for smoothly parametrized families of ``hard'' functions, contrary to countable, discrete families known in the literature. An example consequence of our gap theorems is the following: for every natural number $k$ there exists a function representable by a ReLU DNN with $k^2$ hidden layers and total size $k^3$, such that any ReLU DNN with at most $k$ hidden layers will require at least $\frac12k^{k+1}-1$ total nodes. Finally, for the family of $\R^n\to \R$ DNNs with ReLU activations, we show a new lowerbound on the number of affine pieces, which is larger than previous constructions in certain regimes of the network architecture and most distinctively our lowerbound is demonstrated by an explicit construction of a \emph{smoothly parameterized} family of functions attaining this scaling. Our construction utilizes the theory of zonotopes from polyhedral theory.
tl;dr: A continual learning method that uses distillation to combine expert policies and transfer learning to accelerate learning new skills.

Deep reinforcement learning has demonstrated increasing capabilities for continuous control problems,
including agents that can move with skill and agility through their environment.
An open problem in this setting is that of developing good strategies for integrating or merging policies
for multiple skills, where each individual skill is a specialist in a specific skill and its associated state distribution.
We extend policy distillation methods to the continuous action setting and leverage this technique to combine \expert policies,
as evaluated in the domain of simulated bipedal locomotion across different classes of terrain.
We also introduce an input injection method for augmenting an existing policy network to exploit new input features.
Lastly, our method uses transfer learning to assist in the efficient acquisition of new skills.
The combination of these methods allows a policy to be incrementally augmented with new skills.
We compare our progressive learning and integration via distillation (PLAID) method
against three alternative baselines.

Neural networks are known to be vulnerable to adversarial examples. Carefully chosen perturbations to real images, while imperceptible to humans, induce misclassification and threaten the reliability of deep learning systems in the wild. To guard against adversarial examples, we take inspiration from game theory and cast the problem as a minimax zero-sum game between the adversary and the model. In general, for such games, the optimal strategy for both players requires a stochastic policy, also known as a mixed strategy. In this light, we propose Stochastic Activation Pruning (SAP), a mixed strategy for adversarial defense. SAP prunes a random subset of activations (preferentially pruning those with smaller magnitude) and scales up the survivors to compensate. We can apply SAP to pretrained networks, including adversarially trained models, without fine-tuning, providing robustness against adversarial examples. Experiments demonstrate that SAP confers robustness against attacks, increasing accuracy and preserving calibration.
tl;dr: We propose an autonomous method for safe and efficient reinforcement learning that simultaneously learns a forward and backward policy, with the backward policy resetting the environment for a subsequent attempt.

Deep reinforcement learning algorithms can learn complex behavioral skills, but real-world application of these methods requires a considerable amount of experience to be collected by the agent. In practical settings, such as robotics, this involves repeatedly attempting a task, resetting the environment between each attempt. However, not all tasks are easily or automatically reversible. In practice, this learning process requires considerable human intervention. In this work, we propose an autonomous method for safe and efficient reinforcement learning that simultaneously learns a forward and backward policy, with the backward policy resetting the environment for a subsequent attempt. By learning a value function for the backward policy, we can automatically determine when the forward policy is about to enter a non-reversible state, providing for uncertainty-aware safety aborts. Our experiments illustrate that proper use of the backward policy can greatly reduce the number of manual resets required to learn a task and can reduce the number of unsafe actions that lead to non-reversible states.

While domain adaptation has been actively researched in recent years, most theoretical results and algorithms focus on the single-source-single-target adaptation setting. Naive application of such algorithms on multiple source domain adaptation problem may lead to suboptimal solutions. We propose a new generalization bound for domain adaptation when there are multiple source domains with labeled instances and one target domain with unlabeled instances. Compared with existing bounds, the new bound does not require expert knowledge about the target distribution, nor the optimal combination rule for multisource domains. Interestingly, our theory also leads to an efficient learning strategy using adversarial neural networks: we show how to interpret it as learning feature representations that are invariant to the multiple domain shifts while still being discriminative for the learning task. To this end, we propose two models, both of which we call multisource domain adversarial networks (MDANs): the first model optimizes directly our bound, while the second model is a smoothed approximation of the first one, leading to a more data-efficient and task-adaptive model. The optimization tasks of both models are minimax saddle point problems that can be optimized by adversarial training. To demonstrate the effectiveness of MDANs, we conduct extensive experiments showing superior adaptation performance on three real-world datasets: sentiment analysis, digit classification, and vehicle counting.
tl;dr: We describe a practical optimization algorithm for deep neural networks that works faster and generates better models compared to widely used algorithms.

Progress in deep learning is slowed by the days or weeks it takes to train large models. The natural solution of using more hardware is limited by diminishing returns, and leads to inefficient use of additional resources. In this paper, we present a large batch, stochastic optimization algorithm that is both faster than widely used algorithms for fixed amounts of computation, and also scales up substantially better as more computational resources become available. Our algorithm implicitly computes the inverse Hessian of each mini-batch to produce descent directions; we do so without either an explicit approximation to the Hessian or Hessian-vector products. We demonstrate the effectiveness of our algorithm by successfully training large ImageNet models (InceptionV3, ResnetV1-50, ResnetV1-101 and InceptionResnetV2) with mini-batch sizes of up to 32000 with no loss in validation error relative to current baselines, and no increase in the total number of steps. At smaller mini-batch sizes, our optimizer improves the validation error in these models by 0.8-0.9\%. Alternatively, we can trade off this accuracy to reduce the number of training steps needed by roughly 10-30\%. Our work is practical and easily usable by others -- only one hyperparameter (learning rate) needs tuning, and furthermore, the algorithm is as computationally cheap as the commonly used Adam optimizer.
tl;dr: Use deep reinforcement learning to design the physical attributes of a robot jointly with a control policy.

The physical design of a robot and the policy that controls its motion are inherently coupled. However, existing approaches largely ignore this coupling, instead choosing to alternate between separate design and control phases, which requires expert intuition throughout and risks convergence to suboptimal designs. In this work, we propose a method that jointly optimizes over the physical design of a robot and the corresponding control policy in a model-free fashion, without any need for expert supervision. Given an arbitrary robot morphology, our method maintains a distribution over the design parameters and uses reinforcement learning to train a neural network controller. Throughout training, we refine the robot distribution to maximize the expected reward. This results in an assignment to the robot parameters and neural network policy that are jointly optimal. We evaluate our approach in the context of legged locomotion, and demonstrate that it discovers novel robot designs and walking gaits for several different morphologies, achieving performance comparable to or better than that of hand-crafted designs.
tl;dr: We propose a measure of long-term memory and prove that deep recurrent networks are much better fit to model long-term temporal dependencies than shallow ones.

The key attribute that drives the unprecedented success of modern Recurrent Neural Networks (RNNs) on learning tasks which involve sequential data, is their ever-improving ability to model intricate long-term temporal dependencies. However, a well established measure of RNNs' long-term memory capacity is lacking, and thus formal understanding of their ability to correlate data throughout time is limited. Though depth efficiency in convolutional networks is well established by now, it does not suffice in order to account for the success of deep RNNs on inputs of varying lengths, and the need to address their 'time-series expressive power' arises. In this paper, we analyze the effect of depth on the ability of recurrent networks to express correlations ranging over long time-scales. To meet the above need, we introduce a measure of the information flow across time that can be supported by the network, referred to as the Start-End separation rank. Essentially, this measure reflects the distance of the function realized by the recurrent network from a function that models no interaction whatsoever between the beginning and end of the input sequence. We prove that deep recurrent networks support Start-End separation ranks which are exponentially higher than those supported by their shallow counterparts. Moreover, we show that the ability of deep recurrent networks to correlate different parts of the input sequence increases exponentially as the input sequence extends, while that of vanilla shallow recurrent networks does not adapt to the sequence length at all. Thus, we establish that depth brings forth an overwhelming advantage in the ability of recurrent networks to model long-term dependencies, and provide an exemplar of quantifying this key attribute which may be readily extended to other RNN architectures of interest, e.g. variants of LSTM networks. We obtain our results by considering a class of recurrent networks referred to as Recurrent Arithmetic Circuits (RACs), which merge the hidden state with the input via the Multiplicative Integration operation.
tl;dr: You can fix the classifier in neural networks without losing accuracy

Neural networks are commonly used as models for classification for a wide variety of tasks. Typically, a learned affine transformation is placed at the end of such models, yielding a per-class value used for classification. This classifier can have a vast number of parameters, which grows linearly with the number of possible classes, thus requiring increasingly more resources.
In this work we argue that this classifier can be fixed, up to a global scale constant, with little or no loss of accuracy for most tasks, allowing memory and computational benefits. Moreover, we show that by initializing the classifier with a Hadamard matrix we can speed up inference as well. We discuss the implications for current understanding of neural network models.

Estimating individualized treatment effects (ITE) is a challenging task due to the need for an individual's potential outcomes to be learned from biased data and without having access to the counterfactuals. We propose a novel method for inferring ITE based on the Generative Adversarial Nets (GANs) framework. Our method, termed Generative Adversarial Nets for inference of Individualized Treatment Effects (GANITE), is motivated by the possibility that we can capture the uncertainty in the counterfactual distributions by attempting to learn them using a GAN. We generate proxies of the counterfactual outcomes using a counterfactual generator, G, and then pass these proxies to an ITE generator, I, in order to train it. By modeling both of these using the GAN framework, we are able to infer based on the factual data, while still accounting for the unseen counterfactuals. We test our method on three real-world datasets (with both binary and multiple treatments) and show that GANITE outperforms state-of-the-art methods.
tl;dr: This paper develops a principled method for continual learning in deep models.

This paper develops variational continual learning (VCL), a simple but general framework for continual learning that fuses online variational inference (VI) and recent advances in Monte Carlo VI for neural networks. The framework can successfully train both deep discriminative models and deep generative models in complex continual learning settings where existing tasks evolve over time and entirely new tasks emerge. Experimental results show that VCL outperforms state-of-the-art continual learning methods on a variety of tasks, avoiding catastrophic forgetting in a fully automatic way.
tl;dr: We present a neural variational model for learning language-guided compositional visual concepts.

The seemingly infinite diversity of the natural world arises from a relatively small set of coherent rules, such as the laws of physics or chemistry. We conjecture that these rules give rise to regularities that can be discovered through primarily unsupervised experiences and represented as abstract concepts. If such representations are compositional and hierarchical, they can be recombined into an exponentially large set of new concepts. This paper describes SCAN (Symbol-Concept Association Network), a new framework for learning such abstractions in the visual domain. SCAN learns concepts through fast symbol association, grounding them in disentangled visual primitives that are discovered in an unsupervised manner. Unlike state of the art multimodal generative model baselines, our approach requires very few pairings between symbols and images and makes no assumptions about the form of symbol representations. Once trained, SCAN is capable of multimodal bi-directional inference, generating a diverse set of image samples from symbolic descriptions and vice versa. It also allows for traversal and manipulation of the implicit hierarchy of visual concepts through symbolic instructions and learnt logical recombination operations. Such manipulations enable SCAN to break away from its training data distribution and imagine novel visual concepts through symbolically instructed recombination of previously learnt concepts.
257. Synthesizing realistic neural population activity patterns using Generative Adversarial Networks
tl;dr: Using Wasserstein-GANs to generate realistic neural activity and to detect the most relevant features present in neural population patterns.
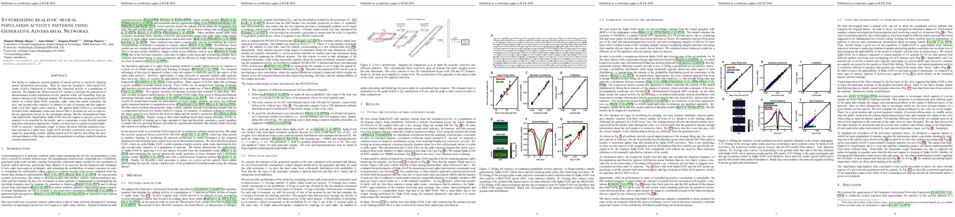
The ability to synthesize realistic patterns of neural activity is crucial for studying neural information processing. Here we used the Generative Adversarial Networks (GANs) framework to simulate the concerted activity of a population of neurons.
We adapted the Wasserstein-GAN variant to facilitate the generation of unconstrained neural population activity patterns while still benefiting from parameter sharing in the temporal domain.
We demonstrate that our proposed GAN, which we termed Spike-GAN, generates spike trains that match accurately the first- and second-order statistics of datasets of tens of neurons and also approximates well their higher-order statistics. We applied Spike-GAN to a real dataset recorded from salamander retina and showed that it performs as well as state-of-the-art approaches based on the maximum entropy and the dichotomized Gaussian frameworks. Importantly, Spike-GAN does not require to specify a priori the statistics to be matched by the model, and so constitutes a more flexible method than these alternative approaches.
Finally, we show how to exploit a trained Spike-GAN to construct 'importance maps' to detect the most relevant statistical structures present in a spike train.
Spike-GAN provides a powerful, easy-to-use technique for generating realistic spiking neural activity and for describing the most relevant features of the large-scale neural population recordings studied in modern systems neuroscience.
tl;dr: We present a RL agent MINERVA which learns to walk on a knowledge graph and answer queries

Knowledge bases (KB), both automatically and manually constructed, are often incomplete --- many valid facts can be inferred from the KB by synthesizing existing information. A popular approach to KB completion is to infer new relations by combinatory reasoning over the information found along other paths connecting a pair of entities. Given the enormous size of KBs and the exponential number of paths, previous path-based models have considered only the problem of predicting a missing relation given two entities, or evaluating the truth of a proposed triple. Additionally, these methods have traditionally used random paths between fixed entity pairs or more recently learned to pick paths between them. We propose a new algorithm, MINERVA, which addresses the much more difficult and practical task of answering questions where the relation is known, but only one entity. Since random walks are impractical in a setting with unknown destination and combinatorially many paths from a start node, we present a neural reinforcement learning approach which learns how to navigate the graph conditioned on the input query to find predictive paths. On a comprehensive evaluation on seven knowledge base datasets, we found MINERVA to be competitive with many current state-of-the-art methods.
tl;dr: Looking at decision boundaries around an input gives you more information than a fixed small neighborhood

Deep neural networks (DNNs) are vulnerable to adversarial examples, which are carefully crafted instances aiming to cause prediction errors for DNNs. Recent research on adversarial examples has examined local neighborhoods in the input space of DNN models. However, previous work has limited what regions to consider, focusing either on low-dimensional subspaces or small balls. In this paper, we argue that information from larger neighborhoods, such as from more directions and from greater distances, will better characterize the relationship between adversarial examples and the DNN models. First, we introduce an attack, OPTMARGIN, which generates adversarial examples robust to small perturbations. These examples successfully evade a defense that only considers a small ball around an input instance. Second, we analyze a larger neighborhood around input instances by looking at properties of surrounding decision boundaries, namely the distances to the boundaries and the adjacent classes. We find that the boundaries around these adversarial examples do not resemble the boundaries around benign examples. Finally, we show that, under scrutiny of the surrounding decision boundaries, our OPTMARGIN examples do not convincingly mimic benign examples. Although our experiments are limited to a few specific attacks, we hope these findings will motivate new, more evasive attacks and ultimately, effective defenses.
tl;dr: We introduce the PHP model for hierarchical representation of neural programs, and an algorithm for learning PHPs from a mixture of strong and weak supervision.

Neural programs are highly accurate and structured policies that perform algorithmic tasks by controlling the behavior of a computation mechanism. Despite the potential to increase the interpretability and the compositionality of the behavior of artificial agents, it remains difficult to learn from demonstrations neural networks that represent computer programs. The main challenges that set algorithmic domains apart from other imitation learning domains are the need for high accuracy, the involvement of specific structures of data, and the extremely limited observability. To address these challenges, we propose to model programs as Parametrized Hierarchical Procedures (PHPs). A PHP is a sequence of conditional operations, using a program counter along with the observation to select between taking an elementary action, invoking another PHP as a sub-procedure, and returning to the caller. We develop an algorithm for training PHPs from a set of supervisor demonstrations, only some of which are annotated with the internal call structure, and apply it to efficient level-wise training of multi-level PHPs. We show in two benchmarks, NanoCraft and long-hand addition, that PHPs can learn neural programs more accurately from smaller amounts of both annotated and unannotated demonstrations.
tl;dr: A modification for existing RNN architectures which allows them to skip state updates while preserving the performance of the original architectures.

Recurrent Neural Networks (RNNs) continue to show outstanding performance in sequence modeling tasks. However, training RNNs on long sequences often face challenges like slow inference, vanishing gradients and difficulty in capturing long term dependencies. In backpropagation through time settings, these issues are tightly coupled with the large, sequential computational graph resulting from unfolding the RNN in time. We introduce the Skip RNN model which extends existing RNN models by learning to skip state updates and shortens the effective size of the computational graph. This model can also be encouraged to perform fewer state updates through a budget constraint. We evaluate the proposed model on various tasks and show how it can reduce the number of required RNN updates while preserving, and sometimes even improving, the performance of the baseline RNN models. Source code is publicly available at https://imatge-upc.github.io/skiprnn-2017-telecombcn/.
tl;dr: Out work presents a Kronecker factorization of recurrent weight matrices for parameter efficient and well conditioned recurrent neural networks.

Our work addresses two important issues with recurrent neural networks: (1) they are over-parameterized, and (2) the recurrent weight matrix is ill-conditioned. The former increases the sample complexity of learning and the training time. The latter causes the vanishing and exploding gradient problem. We present a flexible recurrent neural network model called Kronecker Recurrent Units (KRU). KRU achieves parameter efficiency in RNNs through a Kronecker factored recurrent matrix. It overcomes the ill-conditioning of the recurrent matrix by enforcing soft unitary constraints on the factors. Thanks to the small dimensionality of the factors, maintaining these constraints is computationally efficient. Our experimental results on seven standard data-sets reveal that KRU can reduce the number of parameters by three orders of magnitude in the recurrent weight matrix compared to the existing recurrent models, without trading the statistical performance. These results in particular show that while there are advantages in having a high dimensional recurrent space, the capacity of the recurrent part of the model can be dramatically reduced.
tl;dr: "Bad" local minima are vanishing in a multilayer neural net: a proof with more reasonable assumptions than before

Background: Statistical mechanics results (Dauphin et al. (2014); Choromanska et al. (2015)) suggest that local minima with high error are exponentially rare in high dimensions. However, to prove low error guarantees for Multilayer Neural Networks (MNNs), previous works so far required either a heavily modified MNN model or training method, strong assumptions on the labels (e.g., “near” linear separability), or an unrealistically wide hidden layer with \Omega\(N) units.
Results: We examine a MNN with one hidden layer of piecewise linear units, a single output, and a quadratic loss. We prove that, with high probability in the limit of N\rightarrow\infty datapoints, the volume of differentiable regions of the empiric loss containing sub-optimal differentiable local minima is exponentially vanishing in comparison with the same volume of global minima, given standard normal input of dimension d_0=\tilde{\Omega}(\sqrt{N}), and a more realistic number of d_1=\tilde{\Omega}(N/d_0) hidden units. We demonstrate our results numerically: for example, 0% binary classification training error on CIFAR with only N/d_0 = 16 hidden neurons.

To represent a text as a bag of properly identified “phrases” and use the representation for processing the text is proved to be useful. The key question here is how to identify the phrases and represent them. The traditional method of utilizing n-grams can be regarded as an approximation of the approach. Such a method can suffer from data sparsity, however, particularly when the length of n-gram is large. In this paper, we propose a new method of learning and utilizing task-specific distributed representations of n-grams, referred to as “region embeddings”. Without loss of generality we address text classification. We specifically propose two models for region embeddings. In our models, the representation of a word has two parts, the embedding of the word itself, and a weighting matrix to interact with the local context, referred to as local context unit. The region embeddings are learned and used in the classification task, as parameters of the neural network classifier. Experimental results show that our proposed method outperforms existing methods in text classification on several benchmark datasets. The results also indicate that our method can indeed capture the salient phrasal expressions in the texts.
tl;dr: We perform large scale experiments to show that a simple online variant of distillation can help us scale distributed neural network training to more machines.

Techniques such as ensembling and distillation promise model quality improvements when paired with almost any base model. However, due to increased test-time cost (for ensembles) and increased complexity of the training pipeline (for distillation), these techniques are challenging to use in industrial settings. In this paper we explore a variant of distillation which is relatively straightforward to use as it does not require a complicated multi-stage setup or many new hyperparameters. Our first claim is that online distillation enables us to use extra parallelism to fit very large datasets about twice as fast. Crucially, we can still speed up training even after we have already reached the point at which additional parallelism provides no benefit for synchronous or asynchronous stochastic gradient descent. Two neural networks trained on disjoint subsets of the data can share knowledge by encouraging each model to agree with the predictions the other model would have made. These predictions can come from a stale version of the other model so they can be safely computed using weights that only rarely get transmitted. Our second claim is that online distillation is a cost-effective way to make the exact predictions of a model dramatically more reproducible. We support our claims using experiments on the Criteo Display Ad Challenge dataset, ImageNet, and the largest to-date dataset used for neural language modeling, containing $6\times 10^{11}$ tokens and based on the Common Crawl repository of web data.

Softmax-based loss is widely used in deep learning for multi-class classification, where each class is represented by a weight vector and each sample is represented as a feature vector. Different from traditional learning algorithms where features are pre-defined and only weight vectors are tunable through training, feature vectors are also tunable as representation learning in deep learning. Thus we investigate how to improve the classification performance by better adjusting the features. One main observation is that elongating the feature norm of both correctly-classified and mis-classified feature vectors improves learning: (1) increasing the feature norm of correctly-classified examples induce smaller training loss; (2) increasing the feature norm of mis-classified examples can upweight the contribution from hard examples. Accordingly, we propose feature incay to regularize representation learning by encouraging larger feature norm. In contrast to weight decay which shrinks the weight norm, feature incay is proposed to stretch the feature norm. Extensive empirical results on MNIST, CIFAR10, CIFAR100 and LFW demonstrate the effectiveness of feature incay.

In implicit models, one often interpolates between sampled points in latent space. As we show in this paper, care needs to be taken to match-up the distributional assumptions on code vectors with the geometry of the interpolating paths. Otherwise, typical assumptions about the quality and semantics of in-between points may not be justified. Based on our analysis we propose to modify the prior code distribution to put significantly more probability mass closer to the origin. As a result, linear interpolation paths are not only shortest paths, but they are also guaranteed to pass through high-density regions, irrespective of the dimensionality of the latent space. Experiments on standard benchmark image datasets demonstrate clear visual improvements in the quality of the generated samples and exhibit more meaningful interpolation paths.
tl;dr: We show that the mode collapse problem in GANs may be explained by a lack of information sharing between observations in a training batch, and propose a distribution-based framework for globally sharing information between gradients that leads to more stable and effective adversarial training.

In most current formulations of adversarial training, the discriminators can be expressed as single-input operators, that is, the mapping they define is separable over observations. In this work, we argue that this property might help explain the infamous mode collapse phenomenon in adversarially-trained generative models. Inspired by discrepancy measures and two-sample tests between probability distributions, we propose distributional adversaries that operate on samples, i.e., on sets of multiple points drawn from a distribution, rather than on single observations. We show how they can be easily implemented on top of existing models. Various experimental results show that generators trained in combination with our distributional adversaries are much more stable and are remarkably less prone to mode collapse than traditional models trained with observation-wise prediction discriminators. In addition, the application of our framework to domain adaptation results in strong improvement over recent state-of-the-art.
tl;dr: We decompose the gap between the marginal log-likelihood and the evidence lower bound and study the effect of the approximate posterior on the true posterior distribution in VAEs.

Amortized inference has led to efficient approximate inference for large datasets. The quality of posterior inference is largely determined by two factors: a) the ability of the variational distribution to model the true posterior and b) the capacity of the recognition network to generalize inference over all datapoints. We analyze approximate inference in variational autoencoders in terms of these factors. We find that suboptimal inference is often due to amortizing inference rather than the limited complexity of the approximating distribution. We show that this is due partly to the generator learning to accommodate the choice of approximation. Furthermore, we show that the parameters used to increase the expressiveness of the approximation play a role in generalizing inference rather than simply improving the complexity of the approximation.
tl;dr: We prove the exponential efficiency of recurrent-type neural networks over shallow networks.

Deep neural networks are surprisingly efficient at solving practical tasks,
but the theory behind this phenomenon is only starting to catch up with
the practice. Numerous works show that depth is the key to this efficiency.
A certain class of deep convolutional networks – namely those that correspond
to the Hierarchical Tucker (HT) tensor decomposition – has been
proven to have exponentially higher expressive power than shallow networks.
I.e. a shallow network of exponential width is required to realize
the same score function as computed by the deep architecture. In this paper,
we prove the expressive power theorem (an exponential lower bound on
the width of the equivalent shallow network) for a class of recurrent neural
networks – ones that correspond to the Tensor Train (TT) decomposition.
This means that even processing an image patch by patch with an RNN
can be exponentially more efficient than a (shallow) convolutional network
with one hidden layer. Using theoretical results on the relation between
the tensor decompositions we compare expressive powers of the HT- and
TT-Networks. We also implement the recurrent TT-Networks and provide
numerical evidence of their expressivity.
tl;dr: Using a novel, controlled, visual-relation challenge, we show that same-different tasks critically strain the capacity of CNNs; we argue that visual relations can be better solved using attention-mnemonic strategies.

The robust and efficient recognition of visual relations in images is a hallmark of biological vision. Here, we argue that, despite recent progress in visual recognition, modern machine vision algorithms are severely limited in their ability to learn visual relations. Through controlled experiments, we demonstrate that visual-relation problems strain convolutional neural networks (CNNs). The networks eventually break altogether when rote memorization becomes impossible such as when the intra-class variability exceeds their capacity. We further show that another type of feedforward network, called a relational network (RN), which was shown to successfully solve seemingly difficult visual question answering (VQA) problems on the CLEVR datasets, suffers similar limitations. Motivated by the comparable success of biological vision, we argue that feedback mechanisms including working memory and attention are the key computational components underlying abstract visual reasoning.
tl;dr: We present a question-answering dataset, FigureQA, as a first step towards developing models that can intuitively recognize patterns from visual representations of data.

We introduce FigureQA, a visual reasoning corpus of over one million question-answer pairs grounded in over 100,000 images. The images are synthetic, scientific-style figures from five classes: line plots, dot-line plots, vertical and horizontal bar graphs, and pie charts. We formulate our reasoning task by generating questions from 15 templates; questions concern various relationships between plot elements and examine characteristics like the maximum, the minimum, area-under-the-curve, smoothness, and intersection. To resolve, such questions often require reference to multiple plot elements and synthesis of information distributed spatially throughout a figure. To facilitate the training of machine learning systems, the corpus also includes side data that can be used to formulate auxiliary objectives. In particular, we provide the numerical data used to generate each figure as well as bounding-box annotations for all plot elements. We study the proposed visual reasoning task by training several models, including the recently proposed Relation Network as strong baseline. Preliminary results indicate that the task poses a significant machine learning challenge. We envision FigureQA as a first step towards developing models that can intuitively recognize patterns from visual representations of data.
tl;dr: A deep reinforcement learning agent with parametric noise added to its weights can be used to aid efficient exploration.

We introduce NoisyNet, a deep reinforcement learning agent with parametric noise added to its weights, and show that the induced stochasticity of the agent’s policy can be used to aid efficient exploration. The parameters of the noise are learned with gradient descent along with the remaining network weights. NoisyNet is straightforward to implement and adds little computational overhead. We find that replacing the conventional exploration heuristics for A3C, DQN and Dueling agents (entropy reward and epsilon-greedy respectively) with NoisyNet yields substantially higher scores for a wide range of Atari games, in some cases advancing the agent from sub to super-human performance.
tl;dr: We propose neural cascades, a simple and trivially parallelizable approach to reading comprehension, consisting only of feed-forward nets and attention that achieves state-of-the-art performance on the TriviaQA dataset.

Reading comprehension is a challenging task, especially when executed across longer or across multiple evidence documents, where the answer is likely to reoccur. Existing neural architectures typically do not scale to the entire evidence, and hence, resort to selecting a single passage in the document (either via truncation or other means), and carefully searching for the answer within that passage. However, in some cases, this strategy can be suboptimal, since by focusing on a specific passage, it becomes difficult to leverage multiple mentions of the same answer throughout the document. In this work, we take a different approach by constructing lightweight models that are combined in a cascade to find the answer. Each submodel consists only of feed-forward networks equipped with an attention mechanism, making it trivially parallelizable. We show that our approach can scale to approximately an order of magnitude larger evidence documents and can aggregate information from multiple mentions of each answer candidate across the document. Empirically, our approach achieves state-of-the-art performance on both the Wikipedia and web domains of the TriviaQA dataset, outperforming more complex, recurrent architectures.
tl;dr: We teach agents to negotiate using only reinforcement learning; selfish agents can do so, but only using a trustworthy communication channel, and prosocial agents can negotiate using cheap talk.

Multi-agent reinforcement learning offers a way to study how communication could emerge in communities of agents needing to solve specific problems. In this paper, we study the emergence of communication in the negotiation environment, a semi-cooperative model of agent interaction. We introduce two communication protocols - one grounded in the semantics of the game, and one which is a priori ungrounded. We show that self-interested agents can use the pre-grounded communication channel to negotiate fairly, but are unable to effectively use the ungrounded, cheap talk channel to do the same. However, prosocial agents do learn to use cheap talk to find an optimal negotiating strategy, suggesting that cooperation is necessary for language to emerge. We also study communication behaviour in a setting where one agent interacts with agents in a community with different levels of prosociality and show how agent identifiability can aid negotiation.
276. Rethinking the Smaller-Norm-Less-Informative Assumption in Channel Pruning of Convolution Layers
tl;dr: A CNN model pruning method using ISTA and rescaling trick to enforce sparsity of scaling parameters in batch normalization.

Model pruning has become a useful technique that improves the computational efficiency of deep learning, making it possible to deploy solutions in resource-limited scenarios. A widely-used practice in relevant work assumes that a smaller-norm parameter or feature plays a less informative role at the inference time. In this paper, we propose a channel pruning technique for accelerating the computations of deep convolutional neural networks (CNNs) that does not critically rely on this assumption. Instead, it focuses on direct simplification of the channel-to-channel computation graph of a CNN without the need of performing a computationally difficult and not-always-useful task of making high-dimensional tensors of CNN structured sparse. Our approach takes two stages: first to adopt an end-to-end stochastic training method that eventually forces the outputs of some channels to be constant, and then to prune those constant channels from the original neural network by adjusting the biases of their impacting layers such that the resulting compact model can be quickly fine-tuned. Our approach is mathematically appealing from an optimization perspective and easy to reproduce. We experimented our approach through several image learning benchmarks and demonstrate its interest- ing aspects and competitive performance.
tl;dr: A neural sequence model that learns to forecast on a directed graph.

Spatiotemporal forecasting has various applications in neuroscience, climate and transportation domain. Traffic forecasting is one canonical example of such learning task. The task is challenging due to (1) complex spatial dependency on road networks, (2) non-linear temporal dynamics with changing road conditions and (3) inherent difficulty of long-term forecasting. To address these challenges, we propose to model the traffic flow as a diffusion process on a directed graph and introduce Diffusion Convolutional Recurrent Neural Network (DCRNN), a deep learning framework for traffic forecasting that incorporates both spatial and temporal dependency in the traffic flow. Specifically, DCRNN captures the spatial dependency using bidirectional random walks on the graph, and the temporal dependency using the encoder-decoder architecture with scheduled sampling. We evaluate the framework on two real-world large-scale road network traffic datasets and observe consistent improvement of 12% - 15% over state-of-the-art baselines
tl;dr: We show how to use deep RL to construct agents that can solve social dilemmas beyond matrix games.

Social dilemmas, where mutual cooperation can lead to high payoffs but participants face incentives to cheat, are ubiquitous in multi-agent interaction. We wish to construct agents that cooperate with pure cooperators, avoid exploitation by pure defectors, and incentivize cooperation from the rest. However, often the actions taken by a partner are (partially) unobserved or the consequences of individual actions are hard to predict. We show that in a large class of games good strategies can be constructed by conditioning one's behavior solely on outcomes (ie. one's past rewards). We call this consequentialist conditional cooperation. We show how to construct such strategies using deep reinforcement learning techniques and demonstrate, both analytically and experimentally, that they are effective in social dilemmas beyond simple matrix games. We also show the limitations of relying purely on consequences and discuss the need for understanding both the consequences of and the intentions behind an action.
tl;dr: We propose a new approach to train GANs with a mixture of generators to overcome the mode collapsing problem.

We propose in this paper a new approach to train the Generative Adversarial Nets (GANs) with a mixture of generators to overcome the mode collapsing problem. The main intuition is to employ multiple generators, instead of using a single one as in the original GAN. The idea is simple, yet proven to be extremely effective at covering diverse data modes, easily overcoming the mode collapsing problem and delivering state-of-the-art results. A minimax formulation was able to establish among a classifier, a discriminator, and a set of generators in a similar spirit with GAN. Generators create samples that are intended to come from the same distribution as the training data, whilst the discriminator determines whether samples are true data or generated by generators, and the classifier specifies which generator a sample comes from. The distinguishing feature is that internal samples are created from multiple generators, and then one of them will be randomly selected as final output similar to the mechanism of a probabilistic mixture model. We term our method Mixture Generative Adversarial Nets (MGAN). We develop theoretical analysis to prove that, at the equilibrium, the Jensen-Shannon divergence (JSD) between the mixture of generators’ distributions and the empirical data distribution is minimal, whilst the JSD among generators’ distributions is maximal, hence effectively avoiding the mode collapsing problem. By utilizing parameter sharing, our proposed model adds minimal computational cost to the standard GAN, and thus can also efficiently scale to large-scale datasets. We conduct extensive experiments on synthetic 2D data and natural image databases (CIFAR-10, STL-10 and ImageNet) to demonstrate the superior performance of our MGAN in achieving state-of-the-art Inception scores over latest baselines, generating diverse and appealing recognizable objects at different resolutions, and specializing in capturing different types of objects by the generators.
tl;dr: We propose Dual Actor-Critic algorithm, which is derived in a principled way from the Lagrangian dual form of the Bellman optimality equation. The algorithm achieves the state-of-the-art performances across several benchmarks.

This paper proposes a new actor-critic-style algorithm called Dual Actor-Critic or Dual-AC. It is derived in a principled way from the Lagrangian dual form of the Bellman optimality equation, which can be viewed as a two-player game between the actor and a critic-like function, which is named as dual critic. Compared to its actor-critic relatives, Dual-AC has the desired property that the actor and dual critic are updated cooperatively to optimize the same objective function, providing a more transparent way for learning the critic that is directly related to the objective function of the actor. We then provide a concrete algorithm that can effectively solve the minimax optimization problem, using techniques of multi-step bootstrapping, path regularization, and stochastic dual ascent algorithm. We demonstrate that the proposed algorithm achieves the state-of-the-art performances across several benchmarks.
tl;dr: Residual connections really perform iterative inference

Residual networks (Resnets) have become a prominent architecture in deep learning. However, a comprehensive understanding of Resnets is still a topic of ongoing research. A recent view argues that Resnets perform iterative refinement of features. We attempt to further expose properties of this aspect. To this end, we study Resnets both analytically and empirically. We formalize the notion of iterative refinement in Resnets by showing that residual architectures naturally encourage features to move along the negative gradient of loss during the feedforward phase. In addition, our empirical analysis suggests that Resnets are able to perform both representation learning and iterative refinement. In general, a Resnet block tends to concentrate representation learning behavior in the first few layers while higher layers perform iterative refinement of features. Finally we observe that sharing residual layers naively leads to representation explosion and hurts generalization performance, and show that simple existing strategies can help alleviating this problem.
tl;dr: Using the DSL grammar and reinforcement learning to improve synthesis of programs with complex control flow.

Program synthesis is the task of automatically generating a program consistent with
a specification. Recent years have seen proposal of a number of neural approaches
for program synthesis, many of which adopt a sequence generation paradigm similar
to neural machine translation, in which sequence-to-sequence models are trained to
maximize the likelihood of known reference programs. While achieving impressive
results, this strategy has two key limitations. First, it ignores Program Aliasing: the
fact that many different programs may satisfy a given specification (especially with
incomplete specifications such as a few input-output examples). By maximizing
the likelihood of only a single reference program, it penalizes many semantically
correct programs, which can adversely affect the synthesizer performance. Second,
this strategy overlooks the fact that programs have a strict syntax that can be
efficiently checked. To address the first limitation, we perform reinforcement
learning on top of a supervised model with an objective that explicitly maximizes
the likelihood of generating semantically correct programs. For addressing the
second limitation, we introduce a training procedure that directly maximizes the
probability of generating syntactically correct programs that fulfill the specification.
We show that our contributions lead to improved accuracy of the models, especially
in cases where the training data is limited.

By representing words with probability densities rather than point vectors, proba- bilistic word embeddings can capture rich and interpretable semantic information and uncertainty (Vilnis & McCallum, 2014; Athiwaratkun & Wilson, 2017). The uncertainty information can be particularly meaningful in capturing entailment relationships – whereby general words such as “entity” correspond to broad distributions that encompass more specific words such as “animal” or “instrument”. We introduce density order embeddings, which learn hierarchical representations through encapsulation of probability distributions. In particular, we propose simple yet effective loss functions and distance metrics, as well as graph-based schemes to select negative samples to better learn hierarchical probabilistic representations. Our approach provides state-of-the-art performance on the WordNet hypernym relationship prediction task and the challenging HyperLex lexical entailment dataset – while retaining a rich and interpretable probabilistic representation.
tl;dr: Combining network pruning and persistent kernels into a practical, fast, and accurate network implementation.

Recurrent Neural Networks (RNNs) are powerful tools for solving sequence-based problems, but their efficacy and execution time are dependent on the size of the network. Following recent work in simplifying these networks with model pruning and a novel mapping of work onto GPUs, we design an efficient implementation for sparse RNNs. We investigate several optimizations and tradeoffs: Lamport timestamps, wide memory loads, and a bank-aware weight layout. With these optimizations, we achieve speedups of over 6x over the next best algorithm for a hidden layer of size 2304, batch size of 4, and a density of 30%. Further, our technique allows for models of over 5x the size to fit on a GPU for a speedup of 2x, enabling larger networks to help advance the state-of-the-art. We perform case studies on NMT and speech recognition tasks in the appendix, accelerating their recurrent layers by up to 3x.
tl;dr: Input discretization leads to robustness against adversarial examples

It is well known that it is possible to construct "adversarial examples"
for neural networks: inputs which are misclassified by the network
yet indistinguishable from true data. We propose a simple
modification to standard neural network architectures, thermometer
encoding, which significantly increases the robustness of the network to
adversarial examples. We demonstrate this robustness with experiments
on the MNIST, CIFAR-10, CIFAR-100, and SVHN datasets, and show that
models with thermometer-encoded inputs consistently have higher accuracy
on adversarial examples, without decreasing generalization.
State-of-the-art accuracy under the strongest known white-box attack was
increased from 93.20% to 94.30% on MNIST and 50.00% to 79.16% on CIFAR-10.
We explore the properties of these networks, providing evidence
that thermometer encodings help neural networks to
find more-non-linear decision boundaries.
tl;dr: We show that a special goal-condition value function trained with model free methods can be used within model-based control, resulting in substantially better sample efficiency and performance.

Model-free reinforcement learning (RL) has been proven to be a powerful, general tool for learning complex behaviors. However, its sample efficiency is often impractically large for solving challenging real-world problems, even for off-policy algorithms such as Q-learning. A limiting factor in classic model-free RL is that the learning signal consists only of scalar rewards, ignoring much of the rich information contained in state transition tuples. Model-based RL uses this information, by training a predictive model, but often does not achieve the same asymptotic performance as model-free RL due to model bias. We introduce temporal difference models (TDMs), a family of goal-conditioned value functions that can be trained with model-free learning and used for model-based control. TDMs combine the benefits of model-free and model-based RL: they leverage the rich information in state transitions to learn very efficiently, while still attaining asymptotic performance that exceeds that of direct model-based RL methods. Our experimental results show that, on a range of continuous control tasks, TDMs provide a substantial improvement in efficiency compared to state-of-the-art model-based and model-free methods.
tl;dr: Analysis of vulnerability of classifiers to universal perturbations and relation to the curvature of the decision boundary.

Deep networks have recently been shown to be vulnerable to universal perturbations: there exist very small image-agnostic perturbations that cause most natural images to be misclassified by such classifiers. In this paper, we provide a quantitative analysis of the robustness of classifiers to universal perturbations, and draw a formal link between the robustness to universal perturbations, and the geometry of the decision boundary. Specifically, we establish theoretical bounds on the robustness of classifiers under two decision boundary models (flat and curved models). We show in particular that the robustness of deep networks to universal perturbations is driven by a key property of their curvature: there exist shared directions along which the decision boundary of deep networks is systematically positively curved. Under such conditions, we prove the existence of small universal perturbations. Our analysis further provides a novel geometric method for computing universal perturbations, in addition to explaining their properties.

Over the last years, deep convolutional neural networks (ConvNets) have transformed the field of computer vision thanks to their unparalleled capacity to learn high level semantic image features. However, in order to successfully learn those features, they usually require massive amounts of manually labeled data, which is both expensive and impractical to scale. Therefore, unsupervised semantic feature learning, i.e., learning without requiring manual annotation effort, is of crucial importance in order to successfully harvest the vast amount of visual data that are available today. In our work we propose to learn image features by training ConvNets to recognize the 2d rotation that is applied to the image that it gets as input. We demonstrate both qualitatively and quantitatively that this apparently simple task actually provides a very powerful supervisory signal for semantic feature learning. We exhaustively evaluate our method in various unsupervised feature learning benchmarks and we exhibit in all of them state-of-the-art performance. Specifically, our results on those benchmarks demonstrate dramatic improvements w.r.t. prior state-of-the-art approaches in unsupervised representation learning and thus significantly close the gap with supervised feature learning. For instance, in PASCAL VOC 2007 detection task our unsupervised pre-trained AlexNet model achieves the state-of-the-art (among unsupervised methods) mAP of 54.4%$that is only 2.4 points lower from the supervised case. We get similarly striking results when we transfer our unsupervised learned features on various other tasks, such as ImageNet classification, PASCAL classification, PASCAL segmentation, and CIFAR-10 classification. The code and models of our paper will be published on:
https://github.com/gidariss/FeatureLearningRotNet
tl;dr: We introduce a hierarchical model for efficient, end-to-end placement of computational graphs onto hardware devices.

We introduce a hierarchical model for efficient placement of computational graphs onto hardware devices, especially in heterogeneous environments with a mixture of CPUs, GPUs, and other computational devices. Our method learns to assign graph operations to groups and to allocate those groups to available devices. The grouping and device allocations are learned jointly. The proposed method is trained with policy gradient and requires no human intervention. Experiments with widely-used
computer vision and natural language models show that our algorithm can find optimized, non-trivial placements for TensorFlow computational graphs with over 80,000 operations. In addition, our approach outperforms placements by human
experts as well as a previous state-of-the-art placement method based on deep reinforcement learning. Our method achieves runtime reductions of up to 60.6% per training step when applied to models such as Neural Machine Translation.

Standard model-free deep reinforcement learning (RL) algorithms sample a new initial state for each trial, allowing them to optimize policies that can perform well even in highly stochastic environments. However, problems that exhibit considerable initial state variation typically produce high-variance gradient estimates for model-free RL, making direct policy or value function optimization challenging. In this paper, we develop a novel algorithm that instead partitions the initial state space into "slices", and optimizes an ensemble of policies, each on a different slice. The ensemble is gradually unified into a single policy that can succeed on the whole state space. This approach, which we term divide-and-conquer RL, is able to solve complex tasks where conventional deep RL methods are ineffective. Our results show that divide-and-conquer RL greatly outperforms conventional policy gradient methods on challenging grasping, manipulation, and locomotion tasks, and exceeds the performance of a variety of prior methods. Videos of policies learned by our algorithm can be viewed at https://sites.google.com/view/dnc-rl/
tl;dr: An adaptive method for fixed-point quantization of neural networks based on theoretical analysis rather than heuristics.

Despite the state-of-the-art accuracy of Deep Neural Networks (DNN) in various classification problems, their deployment onto resource constrained edge computing devices remains challenging due to their large size and complexity. Several recent studies have reported remarkable results in reducing this complexity through quantization of DNN models. However, these studies usually do not consider the changes in the loss function when performing quantization, nor do they take the different importances of DNN model parameters to the accuracy into account. We address these issues in this paper by proposing a new method, called adaptive quantization, which simplifies a trained DNN model by finding a unique, optimal precision for each network parameter such that the increase in loss is minimized. The optimization problem at the core of this method iteratively uses the loss function gradient to determine an error margin for each parameter and assigns it a precision accordingly. Since this problem uses linear functions, it is computationally cheap and, as we will show, has a closed-form approximate solution. Experiments on MNIST, CIFAR, and SVHN datasets showed that the proposed method can achieve near or better than state-of-the-art reduction in model size with similar error rates. Furthermore, it can achieve compressions close to floating-point model compression methods without loss of accuracy.
tl;dr: An Empirical Comparison of Bayesian Deep Networks for Thompson Sampling

Recent advances in deep reinforcement learning have made significant strides in performance on applications such as Go and Atari games. However, developing practical methods to balance exploration and exploitation in complex domains remains largely unsolved. Thompson Sampling and its extension to reinforcement learning provide an elegant approach to exploration that only requires access to posterior samples of the model. At the same time, advances in approximate Bayesian methods have made posterior approximation for flexible neural network models practical. Thus, it is attractive to consider approximate Bayesian neural networks in a Thompson Sampling framework. To understand the impact of using an approximate posterior on Thompson Sampling, we benchmark well-established and recently developed methods for approximate posterior sampling combined with Thompson Sampling over a series of contextual bandit problems. We found that many approaches that have been successful in the supervised learning setting underperformed in the sequential decision-making scenario. In particular, we highlight the challenge of adapting slowly converging uncertainty estimates to the online setting.
tl;dr: We present a novel algorithm for hierarchical subtask discovery which leverages the multitask linear Markov decision process framework.

Hierarchical reinforcement learning methods offer a powerful means of planning flexible behavior in complicated domains. However, learning an appropriate hierarchical decomposition of a domain into subtasks remains a substantial challenge. We present a novel algorithm for subtask discovery, based on the recently introduced multitask linearly-solvable Markov decision process (MLMDP) framework. The MLMDP can perform never-before-seen tasks by representing them as a linear combination of a previously learned basis set of tasks. In this setting, the subtask discovery problem can naturally be posed as finding an optimal low-rank approximation of the set of tasks the agent will face in a domain. We use non-negative matrix factorization to discover this minimal basis set of tasks, and show that the technique learns intuitive decompositions in a variety of domains. Our method has several qualitatively desirable features: it is not limited to learning subtasks with single goal states, instead learning distributed patterns of preferred states; it learns qualitatively different hierarchical decompositions in the same domain depending on the ensemble of tasks the agent will face; and it may be straightforwardly iterated to obtain deeper hierarchical decompositions.
tl;dr: A novel approach to processing graph-structured data by neural networks, leveraging attention over a node's neighborhood. Achieves state-of-the-art results on transductive citation network tasks and an inductive protein-protein interaction task.

We present graph attention networks (GATs), novel neural network architectures that operate on graph-structured data, leveraging masked self-attentional layers to address the shortcomings of prior methods based on graph convolutions or their approximations. By stacking layers in which nodes are able to attend over their neighborhoods' features, we enable (implicitly) specifying different weights to different nodes in a neighborhood, without requiring any kind of computationally intensive matrix operation (such as inversion) or depending on knowing the graph structure upfront. In this way, we address several key challenges of spectral-based graph neural networks simultaneously, and make our model readily applicable to inductive as well as transductive problems. Our GAT models have achieved or matched state-of-the-art results across four established transductive and inductive graph benchmarks: the Cora, Citeseer and Pubmed citation network datasets, as well as a protein-protein interaction dataset (wherein test graphs remain unseen during training).
tl;dr: We train wide residual networks that can be immediately deployed using only a single bit for each convolutional weight, with signficantly better accuracy than past methods.

For fast and energy-efficient deployment of trained deep neural networks on resource-constrained embedded hardware, each learned weight parameter should ideally be represented and stored using a single bit. Error-rates usually increase when this requirement is imposed. Here, we report large improvements in error rates on multiple datasets, for deep convolutional neural networks deployed with 1-bit-per-weight. Using wide residual networks as our main baseline, our approach simplifies existing methods that binarize weights by applying the sign function in training; we apply scaling factors for each layer with constant unlearned values equal to the layer-specific standard deviations used for initialization. For CIFAR-10, CIFAR-100 and ImageNet, and models with 1-bit-per-weight requiring less than 10 MB of parameter memory, we achieve error rates of 3.9%, 18.5% and 26.0% / 8.5% (Top-1 / Top-5) respectively. We also considered MNIST, SVHN and ImageNet32, achieving 1-bit-per-weight test results of 0.27%, 1.9%, and 41.3% / 19.1% respectively. For CIFAR, our error rates halve previously reported values, and are within about 1% of our error-rates for the same network with full-precision weights. For networks that overfit, we also show significant improvements in error rate by not learning batch normalization scale and offset parameters. This applies to both full precision and 1-bit-per-weight networks. Using a warm-restart learning-rate schedule, we found that training for 1-bit-per-weight is just as fast as full-precision networks, with better accuracy than standard schedules, and achieved about 98%-99% of peak performance in just 62 training epochs for CIFAR-10/100. For full training code and trained models in MATLAB, Keras and PyTorch see https://github.com/McDonnell-Lab/1-bit-per-weight/ .
tl;dr: Using triplets to learn a metric for comparing neural responses and improve the performance of a prosthesis.

Retinal prostheses for treating incurable blindness are designed to electrically stimulate surviving retinal neurons, causing them to send artificial visual signals to the brain. However, electrical stimulation generally cannot precisely reproduce normal patterns of neural activity in the retina. Therefore, an electrical stimulus must be selected that produces a neural response as close as possible to the desired response. This requires a technique for computing a distance between the desired response and the achievable response that is meaningful in terms of the visual signal being conveyed. Here we propose a method to learn such a metric on neural responses, directly from recorded light responses of a population of retinal ganglion cells (RGCs) in the primate retina. The learned metric produces a measure of similarity of RGC population responses that accurately reflects the similarity of the visual input. Using data from electrical stimulation experiments, we demonstrate that this metric may improve the performance of a prosthesis.
tl;dr: We introduce the first successful method to train neural machine translation in an unsupervised manner, using nothing but monolingual corpora

In spite of the recent success of neural machine translation (NMT) in standard benchmarks, the lack of large parallel corpora poses a major practical problem for many language pairs. There have been several proposals to alleviate this issue with, for instance, triangulation and semi-supervised learning techniques, but they still require a strong cross-lingual signal. In this work, we completely remove the need of parallel data and propose a novel method to train an NMT system in a completely unsupervised manner, relying on nothing but monolingual corpora. Our model builds upon the recent work on unsupervised embedding mappings, and consists of a slightly modified attentional encoder-decoder model that can be trained on monolingual corpora alone using a combination of denoising and backtranslation. Despite the simplicity of the approach, our system obtains 15.56 and 10.21 BLEU points in WMT 2014 French-to-English and German-to-English translation. The model can also profit from small parallel corpora, and attains 21.81 and 15.24 points when combined with 100,000 parallel sentences, respectively. Our implementation is released as an open source project.
tl;dr: We train neural network agents to develop a language with compositional properties from raw pixel input.

One of the distinguishing aspects of human language is its compositionality, which allows us to describe complex environments with limited vocabulary. Previously, it has been shown that neural network agents can learn to communicate in a highly structured, possibly compositional language based on disentangled input (e.g. hand- engineered features). Humans, however, do not learn to communicate based on well-summarized features. In this work, we train neural agents to simultaneously develop visual perception from raw image pixels, and learn to communicate with a sequence of discrete symbols. The agents play an image description game where the image contains factors such as colors and shapes. We train the agents using the obverter technique where an agent introspects to generate messages that maximize its own understanding. Through qualitative analysis, visualization and a zero-shot test, we show that the agents can develop, out of raw image pixels, a language with compositional properties, given a proper pressure from the environment.
tl;dr: We propose Fidelity-weighted Learning, a semi-supervised teacher-student approach for training neural networks using weakly-labeled data.

Training deep neural networks requires many training samples, but in practice training labels are expensive to obtain and may be of varying quality, as some may be from trusted expert labelers while others might be from heuristics or other sources of weak supervision such as crowd-sourcing. This creates a fundamental quality- versus-quantity trade-off in the learning process. Do we learn from the small amount of high-quality data or the potentially large amount of weakly-labeled data? We argue that if the learner could somehow know and take the label-quality into account when learning the data representation, we could get the best of both worlds. To this end, we propose “fidelity-weighted learning” (FWL), a semi-supervised student- teacher approach for training deep neural networks using weakly-labeled data. FWL modulates the parameter updates to a student network (trained on the task we care about) on a per-sample basis according to the posterior confidence of its label-quality estimated by a teacher (who has access to the high-quality labels). Both student and teacher are learned from the data. We evaluate FWL on two tasks in information retrieval and natural language processing where we outperform state-of-the-art alternative semi-supervised methods, indicating that our approach makes better use of strong and weak labels, and leads to better task-dependent data representations.
tl;dr: Recent successes of Binary Neural Networks can be understood based on the geometry of high-dimensional binary vectors

Recent research has shown that one can train a neural network with binary weights and activations at train time by augmenting the weights with a high-precision continuous latent variable that accumulates small changes from stochastic gradient descent. However, there is a dearth of work to explain why one can effectively capture the features in data with binary weights and activations. Our main result is that the neural networks with binary weights and activations trained using the method of Courbariaux, Hubara et al. (2016) work because of the high-dimensional geometry of binary vectors. In particular, the ideal continuous vectors that extract out features in the intermediate representations of these BNNs are well-approximated by binary vectors in the sense that dot products are approximately preserved. Compared to previous research that demonstrated good classification performance with BNNs, our work explains why these BNNs work in terms of HD geometry. Furthermore, the results and analysis used on BNNs are shown to generalize to neural networks with ternary weights and activations. Our theory serves as a foundation for understanding not only BNNs but a variety of methods that seek to compress traditional neural networks. Furthermore, a better understanding of multilayer binary neural networks serves as a starting point for generalizing BNNs to other neural network architectures such as recurrent neural networks.

We propose proximal backpropagation (ProxProp) as a novel algorithm that takes implicit instead of explicit gradient steps to update the network parameters during neural network training. Our algorithm is motivated by the step size limitation of explicit gradient descent, which poses an impediment for optimization. ProxProp is developed from a general point of view on the backpropagation algorithm, currently the most common technique to train neural networks via stochastic gradient descent and variants thereof. Specifically, we show that backpropagation of a prediction error is equivalent to sequential gradient descent steps on a quadratic penalty energy, which comprises the network activations as variables of the optimization. We further analyze theoretical properties of ProxProp and in particular prove that the algorithm yields a descent direction in parameter space and can therefore be combined with a wide variety of convergent algorithms. Finally, we devise an efficient numerical implementation that integrates well with popular deep learning frameworks. We conclude by demonstrating promising numerical results and show that ProxProp can be effectively combined with common first order optimizers such as Adam.
tl;dr: We propose novel extensions of Prototypical Networks that are augmented with the ability to use unlabeled examples when producing prototypes.

In few-shot classification, we are interested in learning algorithms that train a classifier from only a handful of labeled examples. Recent progress in few-shot classification has featured meta-learning, in which a parameterized model for a learning algorithm is defined and trained on episodes representing different classification problems, each with a small labeled training set and its corresponding test set. In this work, we advance this few-shot classification paradigm towards a scenario where unlabeled examples are also available within each episode. We consider two situations: one where all unlabeled examples are assumed to belong to the same set of classes as the labeled examples of the episode, as well as the more challenging situation where examples from other distractor classes are also provided. To address this paradigm, we propose novel extensions of Prototypical Networks (Snell et al., 2017) that are augmented with the ability to use unlabeled examples when producing prototypes. These models are trained in an end-to-end way on episodes, to learn to leverage the unlabeled examples successfully. We evaluate these methods on versions of the Omniglot and miniImageNet benchmarks, adapted to this new framework augmented with unlabeled examples. We also propose a new split of ImageNet, consisting of a large set of classes, with a hierarchical structure. Our experiments confirm that our Prototypical Networks can learn to improve their predictions due to unlabeled examples, much like a semi-supervised algorithm would.
tl;dr: Adversarial training with single-step methods overfits, and remains vulnerable to simple black-box and white-box attacks. We show that including adversarial examples from multiple sources helps defend against black-box attacks.

Adversarial examples are perturbed inputs designed to fool machine learning models. Adversarial training injects such examples into training data to increase robustness. To scale this technique to large datasets, perturbations are crafted using fast single-step methods that maximize a linear approximation of the model's loss.
We show that this form of adversarial training converges to a degenerate global minimum, wherein small curvature artifacts near the data points obfuscate a linear approximation of the loss. The model thus learns to generate weak perturbations, rather than defend against strong ones. As a result, we find that adversarial training remains vulnerable to black-box attacks, where we transfer perturbations computed on undefended models, as well as to a powerful novel single-step attack that escapes the non-smooth vicinity of the input data via a small random step.
We further introduce Ensemble Adversarial Training, a technique that augments training data with perturbations transferred from other models. On ImageNet, Ensemble Adversarial Training yields models with strong robustness to black-box attacks. In particular, our most robust model won the first round of the NIPS 2017 competition on Defenses against Adversarial Attacks.
tl;dr: We address training GANs with discrete data by formulating a policy gradient that generalizes across f-divergences

Generative adversarial networks are a learning framework that rely on training a discriminator to estimate a measure of difference between a target and generated distributions. GANs, as normally formulated, rely on the generated samples being completely differentiable w.r.t. the generative parameters, and thus do not work for discrete data. We introduce a method for training GANs with discrete data that uses the estimated difference measure from the discriminator to compute importance weights for generated samples, thus providing a policy gradient for training the generator. The importance weights have a strong connection to the decision boundary of the discriminator, and we call our method boundary-seeking GANs (BGANs). We demonstrate the effectiveness of the proposed algorithm with discrete image and character-based natural language generation. In addition, the boundary-seeking objective extends to continuous data, which can be used to improve stability of training, and we demonstrate this on Celeba, Large-scale Scene Understanding (LSUN) bedrooms, and Imagenet without conditioning.

We introduce a new algorithm for reinforcement learning called Maximum a-posteriori Policy Optimisation (MPO) based on coordinate ascent on a relative-entropy objective. We show that several existing methods can directly be related to our derivation. We develop two off-policy algorithms and demonstrate that they are competitive with the state-of-the-art in deep reinforcement learning. In particular, for continuous control, our method outperforms existing methods with respect to sample efficiency, premature convergence and robustness to hyperparameter settings.
tl;dr: A novel hierarchical policy network which can reuse previously learned skills alongside and as subcomponents of new skills by discovering the underlying relations between skills.

Learning policies for complex tasks that require multiple different skills is a major challenge in reinforcement learning (RL). It is also a requirement for its deployment in real-world scenarios. This paper proposes a novel framework for efficient multi-task reinforcement learning. Our framework trains agents to employ hierarchical policies that decide when to use a previously learned policy and when to learn a new skill. This enables agents to continually acquire new skills during different stages of training. Each learned task corresponds to a human language description. Because agents can only access previously learned skills through these descriptions, the agent can always provide a human-interpretable description of its choices. In order to help the agent learn the complex temporal dependencies necessary for the hierarchical policy, we provide it with a stochastic temporal grammar that modulates when to rely on previously learned skills and when to execute new skills. We validate our approach on Minecraft games designed to explicitly test the ability to reuse previously learned skills while simultaneously learning new skills.
tl;dr: An empirical evaluation on generative adversarial networks

Generative adversarial networks (GANs) have been extremely effective in approximating complex distributions of high-dimensional, input data samples, and substantial progress has been made in understanding and improving GAN performance in terms of both theory and application.
However, we currently lack quantitative methods for model assessment. Because of this, while many GAN variants being proposed, we have relatively little understanding of their relative abilities. In this paper, we evaluate the performance of various types of GANs using divergence and distance functions typically used only for training. We observe consistency across the various proposed metrics and, interestingly, the test-time metrics do not favour networks that use the same training-time criterion. We also compare the proposed metrics to human perceptual scores.
tl;dr: We introduce a new dataset of logical entailments for the purpose of measuring models' ability to capture and exploit the structure of logical expressions against an entailment prediction task.

We introduce a new dataset of logical entailments for the purpose of measuring models' ability to capture and exploit the structure of logical expressions against an entailment prediction task. We use this task to compare a series of architectures which are ubiquitous in the sequence-processing literature, in addition to a new model class---PossibleWorldNets---which computes entailment as a ``convolution over possible worlds''. Results show that convolutional networks present the wrong inductive bias for this class of problems relative to LSTM RNNs, tree-structured neural networks outperform LSTM RNNs due to their enhanced ability to exploit the syntax of logic, and PossibleWorldNets outperform all benchmarks.
tl;dr: A novel reinforcement learning based approach to compress deep neural networks with knowledge distillation

While bigger and deeper neural network architectures continue to advance the state-of-the-art for many computer vision tasks, real-world adoption of these networks is impeded by hardware and speed constraints. Conventional model compression methods attempt to address this problem by modifying the architecture manually or using pre-defined heuristics. Since the space of all reduced architectures is very large, modifying the architecture of a deep neural network in this way is a difficult task. In this paper, we tackle this issue by introducing a principled method for learning reduced network architectures in a data-driven way using reinforcement learning. Our approach takes a larger 'teacher' network as input and outputs a compressed 'student' network derived from the 'teacher' network. In the first stage of our method, a recurrent policy network aggressively removes layers from the large 'teacher' model. In the second stage, another recurrent policy network carefully reduces the size of each remaining layer. The resulting network is then evaluated to obtain a reward -- a score based on the accuracy and compression of the network. Our approach uses this reward signal with policy gradients to train the policies to find a locally optimal student network. Our experiments show that we can achieve compression rates of more than 10x for models such as ResNet-34 while maintaining similar performance to the input 'teacher' network. We also present a valuable transfer learning result which shows that policies which are pre-trained on smaller 'teacher' networks can be used to rapidly speed up training on larger 'teacher' networks.

Whilst deep neural networks have shown great empirical success, there is still much work to be done to understand their theoretical properties. In this paper, we study the relationship between Gaussian processes with a recursive kernel definition and random wide fully connected feedforward networks with more than one hidden layer. We exhibit limiting procedures under which finite deep networks will converge in distribution to the corresponding Gaussian process. To evaluate convergence rates empirically, we use maximum mean discrepancy. We then exhibit situations where existing Bayesian deep networks are close to Gaussian processes in terms of the key quantities of interest. Any Gaussian process has a flat representation. Since this behaviour may be undesirable in certain situations we discuss ways in which it might be prevented.
tl;dr: Adversarially Regularized Autoencoders learn smooth representations of discrete structures allowing for interesting results in text generation, such as unaligned style transfer, semi-supervised learning, and latent space interpolation and arithmetic.

While autoencoders are a key technique in representation learning for continuous structures, such as images or wave forms, developing general-purpose autoencoders for discrete structures, such as text sequence or discretized images, has proven to be more challenging. In particular, discrete inputs make it more difficult to learn a smooth encoder that preserves the complex local relationships in the input space. In this work, we propose an adversarially regularized autoencoder (ARAE) with the goal of learning more robust discrete-space representations. ARAE jointly trains both a rich discrete-space encoder, such as an RNN, and a simpler continuous space generator function, while using generative adversarial network (GAN) training to constrain the distributions to be similar. This method yields a smoother contracted code space that maps similar inputs to nearby codes, and also an implicit latent variable GAN model for generation. Experiments on text and discretized images demonstrate that the GAN model produces clean interpolations and captures the multimodality of the original space, and that the autoencoder produces improvements in semi-supervised learning as well as state-of-the-art results in unaligned text style transfer task using only a shared continuous-space representation.
tl;dr: This paper bridges deep network architectures with numerical (stochastic) differential equations. This new perspective enables new designs of more effective deep neural networks.

Deep neural networks have become the state-of-the-art models in numerous machine learning tasks. However, general guidance to network architecture design is still missing. In our work, we bridge deep neural network design with numerical differential equations. We show that many effective networks, such as ResNet, PolyNet, FractalNet and RevNet, can be interpreted as different numerical discretizations of differential equations. This finding brings us a brand new perspective on the design of effective deep architectures. We can take advantage of the rich knowledge in numerical analysis to guide us in designing new and potentially more effective deep networks. As an example, we propose a linear multi-step architecture (LM-architecture) which is inspired by the linear multi-step method solving ordinary differential equations. The LM-architecture is an effective structure that can be used on any ResNet-like networks. In particular, we demonstrate that LM-ResNet and LM-ResNeXt (i.e. the networks obtained by applying the LM-architecture on ResNet and ResNeXt respectively) can achieve noticeably higher accuracy than ResNet and ResNeXt on both CIFAR and ImageNet with comparable numbers of trainable parameters. In particular, on both CIFAR and ImageNet, LM-ResNet/LM-ResNeXt can significantly compress (>50%) the original networks while maintaining a similar performance. This can be explained mathematically using the concept of modified equation from numerical analysis. Last but not least, we also establish a connection between stochastic control and noise injection in the training process which helps to improve generalization of the networks. Furthermore, by relating stochastic training strategy with stochastic dynamic system, we can easily apply stochastic training to the networks with the LM-architecture. As an example, we introduced stochastic depth to LM-ResNet and achieve significant improvement over the original LM-ResNet on CIFAR10.
tl;dr: We apply the copula transformation to the Deep Information Bottleneck which leads to restored invariance properties and a disentangled latent space with superior predictive capabilities.

Deep latent variable models are powerful tools for representation learning. In this paper, we adopt the deep information bottleneck model, identify its shortcomings and propose a model that circumvents them. To this end, we apply a copula transformation which, by restoring the invariance properties of the information bottleneck method, leads to disentanglement of the features in the latent space. Building on that, we show how this transformation translates to sparsity of the latent space in the new model. We evaluate our method on artificial and real data.

Teaching an agent to navigate in an unseen 3D environment is a challenging task, even in the event of simulated environments. To generalize to unseen environments, an agent needs to be robust to low-level variations (e.g. color, texture, object changes), and also high-level variations (e.g. layout changes of the environment). To improve overall generalization, all types of variations in the environment have to be taken under consideration via different level of data augmentation steps. To this end, we propose House3D, a rich, extensible and efficient environment that contains 45,622 human-designed 3D scenes of visually realistic houses, ranging from single-room studios to multi-storied houses, equipped with a diverse set of fully labeled 3D objects, textures and scene layouts, based on the SUNCG dataset (Song et al., 2017). The diversity in House3D opens the door towards scene-level augmentation, while the label-rich nature of House3D enables us to inject pixel- & task-level augmentations such as domain randomization (Tobin et al., 2017) and multi-task training. Using a subset of houses in House3D, we show that reinforcement learning agents trained with an enhancement of different levels of augmentations perform much better in unseen environments than our baselines with raw RGB input by over 8% in terms of navigation success rate. House3D is publicly available at http://github.com/facebookresearch/House3D.
tl;dr: Current somatic mutation methods do not work with liquid biopsies (ie low coverage sequencing), we apply a CNN architecture to a unique representation of a read and its ailgnment, we show significant improvement over previous methods in the low frequency setting.

Somatic cancer mutation detection at ultra-low variant allele frequencies (VAFs) is an unmet challenge that is intractable with current state-of-the-art mutation calling methods. Specifically, the limit of VAF detection is closely related to the depth of coverage, due to the requirement of multiple supporting reads in extant methods, precluding the detection of mutations at VAFs that are orders of magnitude lower than the depth of coverage. Nevertheless, the ability to detect cancer-associated mutations in ultra low VAFs is a fundamental requirement for low-tumor burden cancer diagnostics applications such as early detection, monitoring, and therapy nomination using liquid biopsy methods (cell-free DNA). Here we defined a spatial representation of sequencing information adapted for convolutional architecture that enables variant detection at VAFs, in a manner independent of the depth of sequencing. This method enables the detection of cancer mutations even in VAFs as low as 10x-4^, >2 orders of magnitude below the current state-of-the-art. We validated our method on both simulated plasma and on clinical cfDNA plasma samples from cancer patients and non-cancer controls. This method introduces a new domain within bioinformatics and personalized medicine – somatic whole genome mutation calling for liquid biopsy.
tl;dr: We present TreeQN and ATreeC, new architectures for deep reinforcement learning in discrete-action domains that integrate differentiable on-line tree planning into the action-value function or policy.

Combining deep model-free reinforcement learning with on-line planning is a promising approach to building on the successes of deep RL. On-line planning with look-ahead trees has proven successful in environments where transition models are known a priori. However, in complex environments where transition models need to be learned from data, the deficiencies of learned models have limited their utility for planning. To address these challenges, we propose TreeQN, a differentiable, recursive, tree-structured model that serves as a drop-in replacement for any value function network in deep RL with discrete actions. TreeQN dynamically constructs a tree by recursively applying a transition model in a learned abstract state space and then aggregating predicted rewards and state-values using a tree backup to estimate Q-values. We also propose ATreeC, an actor-critic variant that augments TreeQN with a softmax layer to form a stochastic policy network. Both approaches are trained end-to-end, such that the learned model is optimised for its actual use in the tree. We show that TreeQN and ATreeC outperform n-step DQN and A2C on a box-pushing task, as well as n-step DQN and value prediction networks (Oh et al., 2017) on multiple Atari games. Furthermore, we present ablation studies that demonstrate the effect of different auxiliary losses on learning transition models.
tl;dr: We show that creatively designed and trained RNN architectures can decode well known sequential codes and achieve close to optimal performances.

Coding theory is a central discipline underpinning wireline and wireless modems that are the workhorses of the information age. Progress in coding theory is largely driven by individual human ingenuity with sporadic breakthroughs over the past century. In this paper we study whether it is possible to automate the discovery of decoding algorithms via deep learning. We study a family of sequential codes parametrized by recurrent neural network (RNN) architectures. We show that cre- atively designed and trained RNN architectures can decode well known sequential codes such as the convolutional and turbo codes with close to optimal performance on the additive white Gaussian noise (AWGN) channel, which itself is achieved by breakthrough algorithms of our times (Viterbi and BCJR decoders, representing dynamic programing and forward-backward algorithms). We show strong gen- eralizations, i.e., we train at a specific signal to noise ratio and block length but test at a wide range of these quantities, as well as robustness and adaptivity to deviations from the AWGN setting.

To overcome the limitations of Neural Programmer-Interpreters (NPI) in its universality and learnability, we propose the incorporation of combinator abstraction into neural programing and a new NPI architecture to support this abstraction, which we call Combinatory Neural Programmer-Interpreter (CNPI). Combinator abstraction dramatically reduces the number and complexity of programs that need to be interpreted by the core controller of CNPI, while still allowing the CNPI to represent and interpret arbitrary complex programs by the collaboration of the core with the other components. We propose a small set of four combinators to capture the most pervasive programming patterns. Due to the finiteness and simplicity of this combinator set and the offloading of some burden of interpretation from the core, we are able construct a CNPI that is universal with respect to the set of all combinatorizable programs, which is adequate for solving most algorithmic tasks. Moreover, besides supervised training on execution traces, CNPI can be trained by policy gradient reinforcement learning with appropriately designed curricula.
tl;dr: We present a novel network architecture for learning compact and efficient deep neural networks

We present a new approach and a novel architecture, termed WSNet, for learning compact and efficient deep neural networks. Existing approaches conventionally learn full model parameters independently and then compress them via \emph{ad hoc} processing such as model pruning or filter factorization. Alternatively, WSNet proposes learning model parameters by sampling from a compact set of learnable parameters, which naturally enforces {parameter sharing} throughout the learning process. We demonstrate that such a novel weight sampling approach (and induced WSNet) promotes both weights and computation sharing favorably. By employing this method, we can more efficiently learn much smaller networks with competitive performance compared to baseline networks with equal numbers of convolution filters. Specifically, we consider learning compact and efficient 1D convolutional neural networks for audio classification. Extensive experiments on multiple audio classification datasets verify the effectiveness of WSNet. Combined with weight quantization, the resulted models are up to \textbf{180$\times$} smaller and theoretically up to \textbf{16$\times$} faster than the well-established baselines, without noticeable performance drop.
tl;dr: Capsule networks with learned pose matrices and EM routing improves state of the art classification on smallNORB, improves generalizability to new view points, and white box adversarial robustness.

A capsule is a group of neurons whose outputs represent different properties of the same entity. Each layer in a capsule network contains many capsules. We describe a version of capsules in which each capsule has a logistic unit to represent the presence of an entity and a 4x4 matrix which could learn to represent the relationship between that entity and the viewer (the pose). A capsule in one layer votes for the pose matrix of many different capsules in the layer above by multiplying its own pose matrix by trainable viewpoint-invariant transformation matrices that could learn to represent part-whole relationships. Each of these votes is weighted by an assignment coefficient. These coefficients are iteratively updated for each image using the Expectation-Maximization algorithm such that the output of each capsule is routed to a capsule in the layer above that receives a cluster of similar votes. The transformation matrices are trained discriminatively by backpropagating through the unrolled iterations of EM between each pair of adjacent capsule layers. On the smallNORB benchmark, capsules reduce the number of test errors by 45\% compared to the state-of-the-art. Capsules also show far more resistance to white box adversarial attacks than our baseline convolutional neural network.
tl;dr: We propose Value Propagation, a novel end-to-end planner which can learn to solve 2D navigation tasks via Reinforcement Learning, and that generalizes to larger and dynamic environments.

We present Value Propagation (VProp), a parameter-efficient differentiable planning module built on Value Iteration which can successfully be trained in a reinforcement learning fashion to solve unseen tasks, has the capability to generalize to larger map sizes, and can learn to navigate in dynamic environments. We evaluate on configurations of MazeBase grid-worlds, with randomly generated environments of several different sizes. Furthermore, we show that the module enables to learn to plan when the environment also includes stochastic elements, providing a cost-efficient learning system to build low-level size-invariant planners for a variety of interactive navigation problems.
tl;dr: We study the graph generation problem and propose a powerful deep generative model capable of generating arbitrary graphs.

Graphs are fundamental data structures required to model many important real-world data, from knowledge graphs, physical and social interactions to molecules and proteins. In this paper, we study the problem of learning generative models of graphs from a dataset of graphs of interest. After learning, these models can be used to generate samples with similar properties as the ones in the dataset. Such models can be useful in a lot of applications, e.g. drug discovery and knowledge graph construction. The task of learning generative models of graphs, however, has its unique challenges. In particular, how to handle symmetries in graphs and ordering of its elements during the generation process are important issues. We propose a generic graph neural net based model that is capable of generating any arbitrary graph. We study its performance on a few graph generation tasks compared to baselines that exploit domain knowledge. We discuss potential issues and open problems for such generative models going forward.
323. Minimax Curriculum Learning: Machine Teaching with Desirable Difficulties and Scheduled Diversity
tl;dr: Minimax Curriculum Learning is a machine teaching method involving increasing desirable hardness and scheduled reducing diversity.

We introduce and study minimax curriculum learning (MCL), a new method for adaptively selecting a sequence of training subsets for a succession of stages in machine learning. The subsets are encouraged to be small and diverse early on, and then larger, harder, and allowably more homogeneous in later stages. At each stage, model weights and training sets are chosen by solving a joint continuous-discrete minimax optimization, whose objective is composed of a continuous loss (reflecting training set hardness) and a discrete submodular promoter of diversity for the chosen subset. MCL repeatedly solves a sequence of such optimizations with a schedule of increasing training set size and decreasing pressure on diversity encouragement. We reduce MCL to the minimization of a surrogate function handled by submodular maximization and continuous gradient methods. We show that MCL achieves better performance and, with a clustering trick, uses fewer labeled samples for both shallow and deep models while achieving the same performance. Our method involves repeatedly solving constrained submodular maximization of an only slowly varying function on the same ground set. Therefore, we develop a heuristic method that utilizes the previous submodular maximization solution as a warm start for the current submodular maximization process to reduce computation while still yielding a guarantee.

We propose a novel regularizer to improve the training of Generative Adversarial Networks (GANs). The motivation is that when the discriminator D spreads out its model capacity in the right way, the learning signals given to the generator G are more informative and diverse, which helps G to explore better and discover the real data manifold while avoiding large unstable jumps due to the erroneous extrapolation made by D . Our regularizer guides the rectifier discriminator D to better allocate its model capacity, by encouraging the binary activation patterns on selected internal layers of D to have a high joint entropy. Experimental results on both synthetic data and real datasets demonstrate improvements in stability and convergence speed of the GAN training, as well as higher sample quality. The approach also leads to higher classification accuracies in semi-supervised learning.
tl;dr: We show how to make predictions using deep networks, without training deep networks.

It has long been known that a single-layer fully-connected neural network with an i.i.d. prior over its parameters is equivalent to a Gaussian process (GP), in the limit of infinite network width. This correspondence enables exact Bayesian inference for infinite width neural networks on regression tasks by means of evaluating the corresponding GP. Recently, kernel functions which mimic multi-layer random neural networks have been developed, but only outside of a Bayesian framework. As such, previous work has not identified that these kernels can be used as covariance functions for GPs and allow fully Bayesian prediction with a deep neural network.
In this work, we derive the exact equivalence between infinitely wide, deep, networks and GPs with a particular covariance function. We further develop a computationally efficient pipeline to compute this covariance function. We then use the resulting GP to perform Bayesian inference for deep neural networks on MNIST and CIFAR-10. We observe that the trained neural network accuracy approaches that of the corresponding GP with increasing layer width, and that the GP uncertainty is strongly correlated with trained network prediction error. We further find that test performance increases as finite-width trained networks are made wider and more similar to a GP, and that the GP-based predictions typically outperform those of finite-width networks. Finally we connect the prior distribution over weights and variances in our GP formulation to the recent development of signal propagation in random neural networks.
tl;dr: We perform massive experimental studies characterizing the relationships between Jacobian norms, linear regions, and generalization.

In practice it is often found that large over-parameterized neural networks generalize better than their smaller counterparts, an observation that appears to conflict with classical notions of function complexity, which typically favor smaller models. In this work, we investigate this tension between complexity and generalization through an extensive empirical exploration of two natural metrics of complexity related to sensitivity to input perturbations. Our experiments survey thousands of models with different architectures, optimizers, and other hyper-parameters, as well as four different image classification datasets.
We find that trained neural networks are more robust to input perturbations in the vicinity of the training data manifold, as measured by the input-output Jacobian of the network, and that this correlates well with generalization. We further establish that factors associated with poor generalization -- such as full-batch training or using random labels -- correspond to higher sensitivity, while factors associated with good generalization -- such as data augmentation and ReLU non-linearities -- give rise to more robust functions. Finally, we demonstrate how the input-output Jacobian norm can be predictive of generalization at the level of individual test points.
tl;dr: We develop an end-to-end trainable approach for skimming, rereading and early stopping applicable to classification tasks.

Recent advances in recurrent neural nets (RNNs) have shown much promise in many applications in natural language processing. For most of these tasks, such as sentiment analysis of customer reviews, a recurrent neural net model parses the entire review before forming a decision. We argue that reading the entire input is not always necessary in practice, since a lot of reviews are often easy to classify, i.e., a decision can be formed after reading some crucial sentences or words in the provided text. In this paper, we present an approach of fast reading for text classification. Inspired by several well-known human reading techniques, our approach implements an intelligent recurrent agent which evaluates the importance of the current snippet in order to decide whether to make a prediction, or to skip some texts, or to re-read part of the sentence. Our agent uses an RNN module to encode information from the past and the current tokens, and applies a policy module to form decisions. With an end-to-end training algorithm based on policy gradient, we train and test our agent on several text classification datasets and achieve both higher efficiency and better accuracy compared to previous approaches.
tl;dr: A new algorithm to reduce the communication overhead of distributed deep learning by distinguishing ‘unambiguous’ gradients.

Due to the substantial computational cost, training state-of-the-art deep neural networks for large-scale datasets often requires distributed training using multiple computation workers. However, by nature, workers need to frequently communicate gradients, causing severe bottlenecks, especially on lower bandwidth connections. A few methods have been proposed to compress gradient for efficient communication, but they either suffer a low compression ratio or significantly harm the resulting model accuracy, particularly when applied to convolutional neural networks. To address these issues, we propose a method to reduce the communication overhead of distributed deep learning. Our key observation is that gradient updates can be delayed until an unambiguous (high amplitude, low variance) gradient has been calculated. We also present an efficient algorithm to compute the variance and prove that it can be obtained with negligible additional cost. We experimentally show that our method can achieve very high compression ratio while maintaining the result model accuracy. We also analyze the efficiency using computation and communication cost models and provide the evidence that this method enables distributed deep learning for many scenarios with commodity environments.
tl;dr: By setting the width or the initialization variance of each layer differently, we can actually subdue gradient explosion problems in residual networks (with fully connected layers and no batchnorm). A mathematical theory is developed that not only tells you how to do it, but also surprisingly is able to predict, after you apply such tricks, how fast your network trains to achieve a certain test set performance. This is some black magic stuff, and it's called "Deep Mean Field Theory."

A recent line of work has studied the statistical properties of neural networks to great success from a {\it mean field theory} perspective, making and verifying very precise predictions of neural network behavior and test time performance.
In this paper, we build upon these works to explore two methods for taming the behaviors of random residual networks (with only fully connected layers and no batchnorm).
The first method is {\it width variation (WV)}, i.e. varying the widths of layers as a function of depth.
We show that width decay reduces gradient explosion without affecting the mean forward dynamics of the random network.
The second method is {\it variance variation (VV)}, i.e. changing the initialization variances of weights and biases over depth.
We show VV, used appropriately, can reduce gradient explosion of tanh and ReLU resnets from $\exp(\Theta(\sqrt L))$ and $\exp(\Theta(L))$ respectively to constant $\Theta(1)$.
A complete phase-diagram is derived for how variance decay affects different dynamics, such as those of gradient and activation norms.
In particular, we show the existence of many phase transitions where these dynamics switch between exponential, polynomial, logarithmic, and even constant behaviors.
Using the obtained mean field theory, we are able to track surprisingly well how VV at initialization time affects training and test time performance on MNIST after a set number of epochs: the level sets of test/train set accuracies coincide with the level sets of the expectations of certain gradient norms or of metric expressivity (as defined in \cite{yang_meanfield_2017}), a measure of expansion in a random neural network.
Based on insights from past works in deep mean field theory and information geometry, we also provide a new perspective on the gradient explosion/vanishing problems: they lead to ill-conditioning of the Fisher information matrix, causing optimization troubles.
tl;dr: We propose a dual version of the logistic adversarial distance for feature alignment and show that it yields more stable gradient step iterations than the min-max objective.

Methods that align distributions by minimizing an adversarial distance between them have recently achieved impressive results. However, these approaches are difficult to optimize with gradient descent and they often do not converge well without careful hyperparameter tuning and proper initialization. We investigate whether turning the adversarial min-max problem into an optimization problem by replacing the maximization part with its dual improves the quality of the resulting alignment and explore its connections to Maximum Mean Discrepancy. Our empirical results suggest that using the dual formulation for the restricted family of linear discriminators results in a more stable convergence to a desirable solution when compared with the performance of a primal min-max GAN-like objective and an MMD objective under the same restrictions. We test our hypothesis on the problem of aligning two synthetic point clouds on a plane and on a real-image domain adaptation problem on digits. In both cases, the dual formulation yields an iterative procedure that gives more stable and monotonic improvement over time.
tl;dr: We introduce a novel compiler infrastructure that addresses shortcomings of existing deep learning frameworks.

Deep learning software demands reliability and performance. However, many of the existing deep learning frameworks are software libraries that act as an unsafe DSL in Python and a computation graph interpreter. We present DLVM, a design and implementation of a compiler infrastructure with a linear algebra intermediate representation, algorithmic differentiation by adjoint code generation, domain- specific optimizations and a code generator targeting GPU via LLVM. Designed as a modern compiler infrastructure inspired by LLVM, DLVM is more modular and more generic than existing deep learning compiler frameworks, and supports tensor DSLs with high expressivity. With our prototypical staged DSL embedded in Swift, we argue that the DLVM system enables a form of modular, safe and performant frameworks for deep learning.
tl;dr: We investigate a variety of RL algorithms for molecular generation and define new benchmarks (to be released as an OpenAI Gym), finding PPO and a hill-climbing MLE algorithm work best.

The design of small molecules with bespoke properties is of central importance to drug discovery. However significant challenges yet remain for computational methods, despite recent advances such as deep recurrent networks and reinforcement learning strategies for sequence generation, and it can be difficult to compare results across different works. This work proposes 19 benchmarks selected by subject experts, expands smaller datasets previously used to approximately 1.1 million training molecules, and explores how to apply new reinforcement learning techniques effectively for molecular design. The benchmarks here, built as OpenAI Gym environments, will be open-sourced to encourage innovation in molecular design algorithms and to enable usage by those without a background in chemistry. Finally, this work explores recent development in reinforcement-learning methods with excellent sample complexity (the A2C and PPO algorithms) and investigates their behavior in molecular generation, demonstrating significant performance gains compared to standard reinforcement learning techniques.

Deep generative models provide a systematic way to learn nonlinear data distributions through a set of latent variables and a nonlinear "generator" function that maps latent points into the input space. The nonlinearity of the generator implies that the latent space gives a distorted view of the input space. Under mild conditions, we show that this distortion can be characterized by a stochastic Riemannian metric, and we demonstrate that distances and interpolants are significantly improved under this metric. This in turn improves probability distributions, sampling algorithms and clustering in the latent space. Our geometric analysis further reveals that current generators provide poor variance estimates and we propose a new generator architecture with vastly improved variance estimates. Results are demonstrated on convolutional and fully connected variational autoencoders, but the formalism easily generalizes to other deep generative models.
tl;dr: We adapt a family of combinatorial games with tunable difficulty and an optimal policy expressible as linear network, developing it as a rich environment for reinforcement learning, showing contrasts in performance with supervised learning, and analyzing multiagent learning and generalization.

Deep reinforcement learning has achieved many recent successes, but our understanding of its strengths and limitations is hampered by the lack of rich environments in which we can fully characterize optimal behavior, and correspondingly diagnose individual actions against such a characterization.
Here we consider a family of combinatorial games, arising from work of Erdos, Selfridge, and Spencer, and we propose their use as environments for evaluating and comparing different approaches to reinforcement learning. These games have a number of appealing features: they are challenging for current learning approaches, but they form (i) a low-dimensional, simply parametrized environment where (ii) there is a linear closed form solution for optimal behavior from any state, and (iii) the difficulty of the game can be tuned by changing environment parameters in an interpretable way. We use these Erdos-Selfridge-Spencer games not only to compare different algorithms, but also to compare approaches based on supervised and reinforcement learning, to analyze the power of multi-agent approaches in improving performance, and to evaluate generalization to environments outside the training set.

To train an inference network jointly with a deep generative topic model, making it both scalable to big corpora and fast in out-of-sample prediction, we develop Weibull hybrid autoencoding inference (WHAI) for deep latent Dirichlet allocation, which infers posterior samples via a hybrid of stochastic-gradient MCMC and autoencoding variational Bayes. The generative network of WHAI has a hierarchy of gamma distributions, while the inference network of WHAI is a Weibull upward-downward variational autoencoder, which integrates a deterministic-upward deep neural network, and a stochastic-downward deep generative model based on a hierarchy of Weibull distributions. The Weibull distribution can be used to well approximate a gamma distribution with an analytic Kullback-Leibler divergence, and has a simple reparameterization via the uniform noise, which help efficiently compute the gradients of the evidence lower bound with respect to the parameters of the inference network. The effectiveness and efficiency of WHAI are illustrated with experiments on big corpora.

With the increasing interest in deeper understanding of the loss surface of many non-convex deep models, this paper presents a unifying framework to study the local/global optima equivalence of the optimization problems arising from training of such non-convex models. Using the "local openness" property of the underlying training models, we provide simple sufficient conditions under which any local optimum of the resulting optimization problem is globally optimal. We first completely characterize the local openness of matrix multiplication mapping in its range. Then we use our characterization to: 1) show that every local optimum of two layer linear networks is globally optimal. Unlike many existing results in the literature, our result requires no assumption on the target data matrix Y, and input data matrix X. 2) develop almost complete characterization of the local/global optima equivalence of multi-layer linear neural networks. We provide various counterexamples to show the necessity of each of our assumptions. 3) show global/local optima equivalence of non-linear deep models having certain pyramidal structure. Unlike some existing works, our result requires no assumption on the differentiability of the activation functions and can go beyond "full-rank" cases.
tl;dr: We argue that convolutional networks should be considered the default starting point for sequence modeling tasks.

This paper revisits the problem of sequence modeling using convolutional
architectures. Although both convolutional and recurrent architectures have a
long history in sequence prediction, the current "default" mindset in much of
the deep learning community is that generic sequence modeling is best handled
using recurrent networks. The goal of this paper is to question this assumption.
Specifically, we consider a simple generic temporal convolution network (TCN),
which adopts features from modern ConvNet architectures such as a dilations and
residual connections. We show that on a variety of sequence modeling tasks,
including many frequently used as benchmarks for evaluating recurrent networks,
the TCN outperforms baseline RNN methods (LSTMs, GRUs, and vanilla RNNs) and
sometimes even highly specialized approaches. We further show that the
potential "infinite memory" advantage that RNNs have over TCNs is largely
absent in practice: TCNs indeed exhibit longer effective history sizes than their
recurrent counterparts. As a whole, we argue that it may be time to (re)consider
ConvNets as the default "go to" architecture for sequence modeling.

We propose a multi-task learning framework to jointly learn document ranking and query suggestion for web search. It consists of two major components, a document ranker, and a query recommender. Document ranker combines current query and session information and compares the combined representation with document representation to rank the documents. Query recommender tracks users' query reformulation sequence considering all previous in-session queries using a sequence to sequence approach. As both tasks are driven by the users' underlying search intent, we perform joint learning of these two components through session recurrence, which encodes search context and intent. Extensive comparisons against state-of-the-art document ranking and query suggestion algorithms are performed on the public AOL search log, and the promising results endorse the effectiveness of the joint learning framework.
tl;dr: Unsupervised spectral clustering using deep neural networks

Spectral clustering is a leading and popular technique in unsupervised data analysis. Two of its major limitations are scalability and generalization of the spectral embedding (i.e., out-of-sample-extension). In this paper we introduce a deep learning approach to spectral clustering that overcomes the above shortcomings. Our network, which we call SpectralNet, learns a map that embeds input data points into the eigenspace of their associated graph Laplacian matrix and subsequently clusters them. We train SpectralNet using a procedure that involves constrained stochastic optimization. Stochastic optimization allows it to scale to large datasets, while the constraints, which are implemented using a special purpose output layer, allow us to keep the network output orthogonal. Moreover, the map learned by SpectralNet naturally generalizes the spectral embedding to unseen data points. To further improve the quality of the clustering, we replace the standard pairwise Gaussian affinities with affinities leaned from unlabeled data using a Siamese network. Additional improvement can be achieved by applying the network to code representations produced, e.g., by standard autoencoders. Our end-to-end learning procedure is fully unsupervised. In addition, we apply VC dimension theory to derive a lower bound on the size of SpectralNet. State-of-the-art clustering results are reported for both the MNIST and Reuters datasets.
tl;dr: The paper proposes a method for forcing CNNs to leverage spatial attention in learning more object-centric representations that perform better in various respects.

We propose an end-to-end-trainable attention module for convolutional neural network (CNN) architectures built for image classification. The module takes as input the 2D feature vector maps which form the intermediate representations of the input image at different stages in the CNN pipeline, and outputs a 2D matrix of scores for each map. Standard CNN architectures are modified through the incorporation of this module, and trained under the constraint that a convex combination of the intermediate 2D feature vectors, as parametrised by the score matrices, must alone be used for classification. Incentivised to amplify the relevant and suppress the irrelevant or misleading, the scores thus assume the role of attention values. Our experimental observations provide clear evidence to this effect: the learned attention maps neatly highlight the regions of interest while suppressing background clutter. Consequently, the proposed function is able to bootstrap standard CNN architectures for the task of image classification, demonstrating superior generalisation over 6 unseen benchmark datasets. When binarised, our attention maps outperform other CNN-based attention maps, traditional saliency maps, and top object proposals for weakly supervised segmentation as demonstrated on the Object Discovery dataset. We also demonstrate improved robustness against the fast gradient sign method of adversarial attack.

Despite being impactful on a variety of problems and applications, the generative adversarial nets (GANs) are remarkably difficult to train. This issue is formally analyzed by \cite{arjovsky2017towards}, who also propose an alternative direction to avoid the caveats in the minmax two-player training of GANs. The corresponding algorithm, namely, Wasserstein GAN (WGAN) hinges on the 1-Lipschitz continuity of the discriminators. In this paper, we propose a novel approach for enforcing the Lipschitz continuity in the training procedure of WGANs. Our approach seamlessly connects WGAN with one of the recent semi-supervised learning approaches. As a result, it gives rise to not only better photo-realistic samples than the previous methods but also state-of-the-art semi-supervised learning results. In particular, to the best of our knowledge, our approach gives rise to the inception score of more than 5.0 with only 1,000 CIFAR10 images and is the first that exceeds the accuracy of 90\% the CIFAR10 datasets using only 4,000 labeled images.
tl;dr: Implicit models applied to causality and genetics

Progress in probabilistic generative models has accelerated, developing richer models with neural architectures, implicit densities, and with scalable algorithms for their Bayesian inference. However, there has been limited progress in models that capture causal relationships, for example, how individual genetic factors cause major human diseases. In this work, we focus on two challenges in particular: How do we build richer causal models, which can capture highly nonlinear relationships and interactions between multiple causes? How do we adjust for latent confounders, which are variables influencing both cause and effect and which prevent learning of causal relationships? To address these challenges, we synthesize ideas from causality and modern probabilistic modeling. For the first, we describe implicit causal models, a class of causal models that leverages neural architectures with an implicit density. For the second, we describe an implicit causal model that adjusts for confounders by sharing strength across examples. In experiments, we scale Bayesian inference on up to a billion genetic measurements. We achieve state of the art accuracy for identifying causal factors: we significantly outperform the second best result by an absolute difference of 15-45.3%.
tl;dr: We build on auto-encoding sequential Monte Carlo, gain new theoretical insights and develop an improved training procedure based on those insights.

We build on auto-encoding sequential Monte Carlo (AESMC): a method for model and proposal learning based on maximizing the lower bound to the log marginal likelihood in a broad family of structured probabilistic models. Our approach relies on the efficiency of sequential Monte Carlo (SMC) for performing inference in structured probabilistic models and the flexibility of deep neural networks to model complex conditional probability distributions. We develop additional theoretical insights and introduce a new training procedure which improves both model and proposal learning. We demonstrate that our approach provides a fast, easy-to-implement and scalable means for simultaneous model learning and proposal adaptation in deep generative models.
tl;dr: Genetic algorithms based approach for optimizing deep neural network policies

Genetic algorithms have been widely used in many practical optimization problems.
Inspired by natural selection, operators, including mutation, crossover
and selection, provide effective heuristics for search and black-box optimization.
However, they have not been shown useful for deep reinforcement learning, possibly
due to the catastrophic consequence of parameter crossovers of neural networks.
Here, we present Genetic Policy Optimization (GPO), a new genetic algorithm
for sample-efficient deep policy optimization. GPO uses imitation learning
for policy crossover in the state space and applies policy gradient methods for mutation.
Our experiments on MuJoCo tasks show that GPO as a genetic algorithm
is able to provide superior performance over the state-of-the-art policy gradient
methods and achieves comparable or higher sample efficiency.
tl;dr: A simple and practical algorithm for learning a margin-maximizing translation-invariant or spherically symmetric kernel from training data, using tools from Fourier analysis and regret minimization.

We propose a principled method for kernel learning, which relies on a Fourier-analytic characterization of translation-invariant or rotation-invariant kernels. Our method produces a sequence of feature maps, iteratively refining the SVM margin. We provide rigorous guarantees for optimality and generalization, interpreting our algorithm as online equilibrium-finding dynamics in a certain two-player min-max game. Evaluations on synthetic and real-world datasets demonstrate scalability and consistent improvements over related random features-based methods.
tl;dr: We introduce a new memory architecture for navigation in previously unseen environments, inspired by landmark-based navigation in animals.

We introduce a new memory architecture for navigation in previously unseen environments, inspired by landmark-based navigation in animals. The proposed semi-parametric topological memory (SPTM) consists of a (non-parametric) graph with nodes corresponding to locations in the environment and a (parametric) deep network capable of retrieving nodes from the graph based on observations. The graph stores no metric information, only connectivity of locations corresponding to the nodes. We use SPTM as a planning module in a navigation system. Given only 5 minutes of footage of a previously unseen maze, an SPTM-based navigation agent can build a topological map of the environment and use it to confidently navigate towards goals. The average success rate of the SPTM agent in goal-directed navigation across test environments is higher than the best-performing baseline by a factor of three.
tl;dr: This paper proposes a novel actor-critic method that uses Hessians of a critic to update an actor.

Actor-critic methods solve reinforcement learning problems by updating a parameterized policy known as an actor in a direction that increases an estimate of the expected return known as a critic. However, existing actor-critic methods only use values or gradients of the critic to update the policy parameter. In this paper, we propose a novel actor-critic method called the guide actor-critic (GAC). GAC firstly learns a guide actor that locally maximizes the critic and then it updates the policy parameter based on the guide actor by supervised learning. Our main theoretical contributions are two folds. First, we show that GAC updates the guide actor by performing second-order optimization in the action space where the curvature matrix is based on the Hessians of the critic. Second, we show that the deterministic policy gradient method is a special case of GAC when the Hessians are ignored. Through experiments, we show that our method is a promising reinforcement learning method for continuous controls.
tl;dr: learn hierarchal sub-policies through end-to-end training over a distribution of tasks

We develop a metalearning approach for learning hierarchically structured poli- cies, improving sample efficiency on unseen tasks through the use of shared primitives—policies that are executed for large numbers of timesteps. Specifi- cally, a set of primitives are shared within a distribution of tasks, and are switched between by task-specific policies. We provide a concrete metric for measuring the strength of such hierarchies, leading to an optimization problem for quickly reaching high reward on unseen tasks. We then present an algorithm to solve this problem end-to-end through the use of any off-the-shelf reinforcement learning method, by repeatedly sampling new tasks and resetting task-specific policies. We successfully discover meaningful motor primitives for the directional movement of four-legged robots, solely by interacting with distributions of mazes. We also demonstrate the transferability of primitives to solve long-timescale sparse-reward obstacle courses, and we enable 3D humanoid robots to robustly walk and crawl with the same policy.
tl;dr: Modifications to MAML and RL2 that should allow for better exploration.

We consider the problem of exploration in meta reinforcement learning. Two new meta reinforcement learning algorithms are suggested: E-MAML and ERL2. Results are presented on a novel environment we call 'Krazy World' and a set of maze environments. We show E-MAML and ERL2 deliver better performance on tasks where exploration is important.
tl;dr: Cascade adversarial training + low level similarity learning improve robustness against both white box and black box attacks.

Injecting adversarial examples during training, known as adversarial training, can improve robustness against one-step attacks, but not for unknown iterative attacks. To address this challenge, we first show iteratively generated adversarial images easily transfer between networks trained with the same strategy. Inspired by this observation, we propose cascade adversarial training, which transfers the knowledge of the end results of adversarial training. We train a network from scratch by injecting iteratively generated adversarial images crafted from already defended networks in addition to one-step adversarial images from the network being trained. We also propose to utilize embedding space for both classification and low-level (pixel-level) similarity learning to ignore unknown pixel level perturbation. During training, we inject adversarial images without replacing their corresponding clean images and penalize the distance between the two embeddings (clean and adversarial). Experimental results show that cascade adversarial training together with our proposed low-level similarity learning efficiently enhances the robustness against iterative attacks, but at the expense of decreased robustness against one-step attacks. We show that combining those two techniques can also improve robustness under the worst case black box attack scenario.
tl;dr: show multi-channel attention weight contains semantic feature to solve natural language inference task.

Natural Language Inference (NLI) task requires an agent to determine the logical relationship between a natural language premise and a natural language hypothesis. We introduce Interactive Inference Network (IIN), a novel class of neural network architectures that is able to achieve high-level understanding of the sentence pair by hierarchically extracting semantic features from interaction space. We show that an interaction tensor (attention weight) contains semantic information to solve natural language inference, and a denser interaction tensor contains richer semantic information. One instance of such architecture, Densely Interactive Inference Network (DIIN), demonstrates the state-of-the-art performance on large scale NLI copora and large-scale NLI alike corpus. It's noteworthy that DIIN achieve a greater than 20% error reduction on the challenging Multi-Genre NLI (MultiNLI) dataset with respect to the strongest published system.
tl;dr: We train generative adversarial networks in a progressive fashion, enabling us to generate high-resolution images with high quality.

We describe a new training methodology for generative adversarial networks. The key idea is to grow both the generator and discriminator progressively: starting from a low resolution, we add new layers that model increasingly fine details as training progresses. This both speeds the training up and greatly stabilizes it, allowing us to produce images of unprecedented quality, e.g., CelebA images at 1024^2. We also propose a simple way to increase the variation in generated images, and achieve a record inception score of 8.80 in unsupervised CIFAR10. Additionally, we describe several implementation details that are important for discouraging unhealthy competition between the generator and discriminator. Finally, we suggest a new metric for evaluating GAN results, both in terms of image quality and variation. As an additional contribution, we construct a higher-quality version of the CelebA dataset.
tl;dr: Explain bias situation with MMD GANs; MMD GANs work with smaller critic networks than WGAN-GPs; new GAN evaluation metric.

We investigate the training and performance of generative adversarial networks using the Maximum Mean Discrepancy (MMD) as critic, termed MMD GANs. As our main theoretical contribution, we clarify the situation with bias in GAN loss functions raised by recent work: we show that gradient estimators used in the optimization process for both MMD GANs and Wasserstein GANs are unbiased, but learning a discriminator based on samples leads to biased gradients for the generator parameters. We also discuss the issue of kernel choice for the MMD critic, and characterize the kernel corresponding to the energy distance used for the Cramér GAN critic. Being an integral probability metric, the MMD benefits from training strategies recently developed for Wasserstein GANs. In experiments, the MMD GAN is able to employ a smaller critic network than the Wasserstein GAN, resulting in a simpler and faster-training algorithm with matching performance. We also propose an improved measure of GAN convergence, the Kernel Inception Distance, and show how to use it to dynamically adapt learning rates during GAN training.
tl;dr: Generalization is strongly correlated with the Bayesian evidence, and gradient noise drives SGD towards minima whose evidence is large.
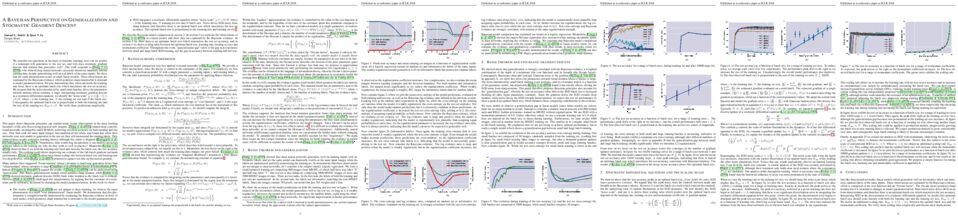
We consider two questions at the heart of machine learning; how can we predict if a minimum will generalize to the test set, and why does stochastic gradient descent find minima that generalize well? Our work responds to \citet{zhang2016understanding}, who showed deep neural networks can easily memorize randomly labeled training data, despite generalizing well on real labels of the same inputs. We show that the same phenomenon occurs in small linear models. These observations are explained by the Bayesian evidence, which penalizes sharp minima but is invariant to model parameterization. We also demonstrate that, when one holds the learning rate fixed, there is an optimum batch size which maximizes the test set accuracy. We propose that the noise introduced by small mini-batches drives the parameters towards minima whose evidence is large. Interpreting stochastic gradient descent as a stochastic differential equation, we identify the ``noise scale" $g = \epsilon (\frac{N}{B} - 1) \approx \epsilon N/B$, where $\epsilon$ is the learning rate, $N$ the training set size and $B$ the batch size. Consequently the optimum batch size is proportional to both the learning rate and the size of the training set, $B_{opt} \propto \epsilon N$. We verify these predictions empirically.

This work aims to provide comprehensive landscape analysis of empirical risk in deep neural networks (DNNs), including the convergence behavior of its gradient, its stationary points and the empirical risk itself to their corresponding population counterparts, which reveals how various network parameters determine the convergence performance. In particular, for an $l$-layer linear neural network consisting of $\dm_i$ neurons in the $i$-th layer, we prove the gradient of its empirical risk uniformly converges to the one of its population risk, at the rate of $\mathcal{O}(r^{2l} \sqrt{l\sqrt{\max_i \dm_i} s\log(d/l)/n})$. Here $d$ is the total weight dimension, $s$ is the number of nonzero entries of all the weights and the magnitude of weights per layer is upper bounded by $r$. Moreover, we prove the one-to-one correspondence of the non-degenerate stationary points between the empirical and population risks and provide convergence guarantee for each pair. We also establish the uniform convergence of the empirical risk to its population counterpart and further derive the stability and generalization bounds for the empirical risk. In addition, we analyze these properties for deep \emph{nonlinear} neural networks with sigmoid activation functions. We prove similar results for convergence behavior of their empirical risk gradients, non-degenerate stationary points as well as the empirical risk itself.
To our best knowledge, this work is the first one theoretically characterizing the uniform convergence of the gradient and stationary points of the empirical risk of DNN models, which benefits the theoretical understanding on how the neural network depth $l$, the layer width $\dm_i$, the network size $d$, the sparsity in weight and the parameter magnitude $r$ determine the neural network landscape.

We present graph partition neural networks (GPNN), an extension of graph neural networks (GNNs) able to handle extremely large graphs. GPNNs alternate between locally propagating information between nodes in small subgraphs and globally propagating information between the subgraphs. To efficiently partition graphs, we experiment with spectral partitioning and also propose a modified multi-seed flood fill for fast processing of large scale graphs. We extensively test our model on a variety of semi-supervised node classification tasks. Experimental results indicate that GPNNs are either superior or comparable to state-of-the-art methods on a wide variety of datasets for graph-based semi-supervised classification. We also show that GPNNs can achieve similar performance as standard GNNs with fewer propagation steps.

We analyze the expressiveness and loss surface of practical deep convolutional
neural networks (CNNs) with shared weights and max pooling layers. We show
that such CNNs produce linearly independent features at a “wide” layer which
has more neurons than the number of training samples. This condition holds e.g.
for the VGG network. Furthermore, we provide for such wide CNNs necessary
and sufficient conditions for global minima with zero training error. For the case
where the wide layer is followed by a fully connected layer we show that almost
every critical point of the empirical loss is a global minimum with zero training
error. Our analysis suggests that both depth and width are very important in deep
learning. While depth brings more representational power and allows the network
to learn high level features, width smoothes the optimization landscape of the
loss function in the sense that a sufficiently wide network has a well-behaved loss
surface with almost no bad local minima.
tl;dr: Adversarial error has similar power-law form for all datasets and models studied, and architecture matters.

It is becoming increasingly clear that many machine learning classifiers are vulnerable to adversarial examples. In attempting to explain the origin of adversarial examples, previous studies have typically focused on the fact that neural networks operate on high dimensional data, they overfit, or they are too linear. Here we show that distributions of logit differences have a universal functional form. This functional form is independent of architecture, dataset, and training protocol; nor does it change during training. This leads to adversarial error having a universal scaling, as a power-law, with respect to the size of the adversarial perturbation. We show that this universality holds for a broad range of datasets (MNIST, CIFAR10, ImageNet, and random data), models (including state-of-the-art deep networks, linear models, adversarially trained networks, and networks trained on randomly shuffled labels), and attacks (FGSM, step l.l., PGD). Motivated by these results, we study the effects of reducing prediction entropy on adversarial robustness. Finally, we study the effect of network architectures on adversarial sensitivity. To do this, we use neural architecture search with reinforcement learning to find adversarially robust architectures on CIFAR10. Our resulting architecture is more robust to white \emph{and} black box attacks compared to previous attempts.
tl;dr: We introduce MIST RNNs, which a) exhibit superior vanishing-gradient properties in comparison to LSTM; b) improve performance substantially over LSTM and Clockwork RNNs on tasks requiring very long-term dependencies; and c) are much more efficient than previously-proposed NARX RNNs, with even fewer parameters and operations than LSTM.

Recurrent neural networks (RNNs) have achieved state-of-the-art performance on many diverse tasks, from machine translation to surgical activity recognition, yet training RNNs to capture long-term dependencies remains difficult. To date, the vast majority of successful RNN architectures alleviate this problem using nearly-additive connections between states, as introduced by long short-term memory (LSTM). We take an orthogonal approach and introduce MIST RNNs, a NARX RNN architecture that allows direct connections from the very distant past. We show that MIST RNNs 1) exhibit superior vanishing-gradient properties in comparison to LSTM and previously-proposed NARX RNNs; 2) are far more efficient than previously-proposed NARX RNN architectures, requiring even fewer computations than LSTM; and 3) improve performance substantially over LSTM and Clockwork RNNs on tasks requiring very long-term dependencies.
tl;dr: Program synthesis from natural language description and input / output examples via Tree-Beam Search over Seq2Tree model

We present a Neural Program Search, an algorithm to generate programs from natural language description and a small number of input / output examples. The algorithm combines methods from Deep Learning and Program Synthesis fields by designing rich domain-specific language (DSL) and defining efficient search algorithm guided by a Seq2Tree model on it. To evaluate the quality of the approach we also present a semi-synthetic dataset of descriptions with test examples and corresponding programs. We show that our algorithm significantly outperforms sequence-to-sequence model with attention baseline.
tl;dr: Finding correspondences between domains by performing matching/mapping iterations

Identifying analogies across domains without supervision is a key task for artificial intelligence. Recent advances in cross domain image mapping have concentrated on translating images across domains. Although the progress made is impressive, the visual fidelity many times does not suffice for identifying the matching sample from the other domain. In this paper, we tackle this very task of finding exact analogies between datasets i.e. for every image from domain A find an analogous image in domain B. We present a matching-by-synthesis approach: AN-GAN, and show that it outperforms current techniques. We further show that the cross-domain mapping task can be broken into two parts: domain alignment and learning the mapping function. The tasks can be iteratively solved, and as the alignment is improved, the unsupervised translation function reaches quality comparable to full supervision.
tl;dr: Recovery guarantee of stochastic gradient descent with random initialization for learning a two-layer neural network with two hidden nodes, unit-norm weights, ReLU activation functions and Gaussian inputs.

Deep learning models can be efficiently optimized via stochastic gradient descent, but there is little theoretical evidence to support this. A key question in optimization is to understand when the optimization landscape of a neural network is amenable to gradient-based optimization. We focus on a simple neural network two-layer ReLU network with two hidden units, and show that all local minimizers are global. This combined with recent work of Lee et al. (2017); Lee et al. (2016) show that gradient descent converges to the global minimizer.
tl;dr: We propose of method of using group properties to learn a representation of motion without labels and demonstrate the use of this method for representing 2D and 3D motion.

Motion is an important signal for agents in dynamic environments, but learning to represent motion from unlabeled video is a difficult and underconstrained problem. We propose a model of motion based on elementary group properties of transformations and use it to train a representation of image motion. While most methods of estimating motion are based on pixel-level constraints, we use these group properties to constrain the abstract representation of motion itself. We demonstrate that a deep neural network trained using this method captures motion in both synthetic 2D sequences and real-world sequences of vehicle motion, without requiring any labels. Networks trained to respect these constraints implicitly identify the image characteristic of motion in different sequence types. In the context of vehicle motion, this method extracts information useful for localization, tracking, and odometry. Our results demonstrate that this representation is useful for learning motion in the general setting where explicit labels are difficult to obtain.
tl;dr: Enabling Visual Question Answering models to count by handling overlapping object proposals.

Visual Question Answering (VQA) models have struggled with counting objects in natural images so far. We identify a fundamental problem due to soft attention in these models as a cause. To circumvent this problem, we propose a neural network component that allows robust counting from object proposals. Experiments on a toy task show the effectiveness of this component and we obtain state-of-the-art accuracy on the number category of the VQA v2 dataset without negatively affecting other categories, even outperforming ensemble models with our single model. On a difficult balanced pair metric, the component gives a substantial improvement in counting over a strong baseline by 6.6%.
tl;dr: This paper studies the discrimination and generalization properties of GANs when the discriminator set is a restricted function class like neural networks.

Generative adversarial training can be generally understood as minimizing certain moment matching loss defined by a set of discriminator functions, typically neural networks. The discriminator set should be large enough to be able to uniquely identify the true distribution (discriminative), and also be small enough to go beyond memorizing samples (generalizable). In this paper, we show that a discriminator set is guaranteed to be discriminative whenever its linear span is dense in the set of bounded continuous functions. This is a very mild condition satisfied even by neural networks with a single neuron. Further, we develop generalization bounds between the learned distribution and true distribution under different evaluation metrics. When evaluated with neural distance, our bounds show that generalization is guaranteed as long as the discriminator set is small enough, regardless of the size of the generator or hypothesis set. When evaluated with KL divergence, our bound provides an explanation on the counter-intuitive behaviors of testing likelihood in GAN training. Our analysis sheds lights on understanding the practical performance of GANs.
tl;dr: Memory networks with faster inference

Real-world Question Answering (QA) tasks consist of thousands of words that often represent many facts and entities. Existing models based on LSTMs require a large number of parameters to support external memory and do not generalize well for long sequence inputs. Memory networks attempt to address these limitations by storing information to an external memory module but must examine all inputs in the memory. Hence, for longer sequence inputs the intermediate memory components proportionally scale in size resulting in poor inference times and high computation costs.
In this paper, we present Adaptive Memory Networks (AMN) that process input question pairs to dynamically construct a network architecture optimized for lower inference times. During inference, AMN parses input text into entities within different memory slots. However, distinct from previous approaches, AMN is a dynamic network architecture that creates variable numbers of memory banks weighted by question relevance. Thus, the decoder can select a variable number of memory banks to construct an answer using fewer banks, creating a runtime trade-off between accuracy and speed.
AMN is enabled by first, a novel bank controller that makes discrete decisions with high accuracy and second, the capabilities of a dynamic framework (such as PyTorch) that allow for dynamic network sizing and efficient variable mini-batching. In our results, we demonstrate that our model learns to construct a varying number of memory banks based on task complexity and achieves faster inference times for standard bAbI tasks, and modified bAbI tasks. We achieve state of the art accuracy over these tasks with an average 48% lower entities are examined during inference.

Robust real-world learning should benefit from both demonstrations and interaction with the environment. Current approaches to learning from demonstration and reward perform supervised learning on expert demonstration data and use reinforcement learning to further improve performance based on reward from the environment. These tasks have divergent losses which are difficult to jointly optimize; further, such methods can be very sensitive to noisy demonstrations. We propose a unified reinforcement learning algorithm that effectively normalizes the Q-function, reducing the Q-values of actions unseen in the demonstration data. Our Normalized Actor-Critic (NAC) method can learn from demonstration data of arbitrary quality and also leverages rewards from an interactive environment. NAC learns an initial policy network from demonstration and refines the policy in a real environment. Crucially, both learning from demonstration and interactive refinement use exactly the same objective, unlike prior approaches that combine distinct supervised and reinforcement losses. This makes NAC robust to suboptimal demonstration data, since the method is not forced to mimic all of the examples in the dataset. We show that our unified reinforcement learning algorithm can learn robustly and outperform existing baselines when evaluated on several realistic driving games.
368. Neuron as an Agent
tl;dr: Neuron as an Agent (NaaA) enable us to train multi-agent communication without a trusted third party.

Existing multi-agent reinforcement learning (MARL) communication methods have relied on a trusted third party (TTP) to distribute reward to agents, leaving them inapplicable in peer-to-peer environments. This paper proposes reward distribution using {\em Neuron as an Agent} (NaaA) in MARL without a TTP with two key ideas: (i) inter-agent reward distribution and (ii) auction theory. Auction theory is introduced because inter-agent reward distribution is insufficient for optimization. Agents in NaaA maximize their profits (the difference between reward and cost) and, as a theoretical result, the auction mechanism is shown to have agents autonomously evaluate counterfactual returns as the values of other agents. NaaA enables representation trades in peer-to-peer environments, ultimately regarding unit in neural networks as agents. Finally, numerical experiments (a single-agent environment from OpenAI Gym and a multi-agent environment from ViZDoom) confirm that NaaA framework optimization leads to better performance in reinforcement learning.
tl;dr: Advantage-based regret minimization is a new deep reinforcement learning algorithm that is particularly effective on partially observable tasks, such as 1st person navigation in Doom and Minecraft.

Deep reinforcement learning algorithms that estimate state and state-action value functions have been shown to be effective in a variety of challenging domains, including learning control strategies from raw image pixels. However, algorithms that estimate state and state-action value functions typically assume a fully observed state and must compensate for partial or non-Markovian observations by using finite-length frame-history observations or recurrent networks. In this work, we propose a new deep reinforcement learning algorithm based on counterfactual regret minimization that iteratively updates an approximation to a cumulative clipped advantage function and is robust to partially observed state. We demonstrate that on several partially observed reinforcement learning tasks, this new class of algorithms can substantially outperform strong baseline methods: on Pong with single-frame observations, and on the challenging Doom (ViZDoom) and Minecraft (Malmö) first-person navigation benchmarks.
tl;dr: We investigate the various kinds of prior knowledge that help human learning and find that general priors about objects play the most critical role in guiding human gameplay.

What makes humans so good at solving seemingly complex video games? Unlike computers, humans bring in a great deal of prior knowledge about the world, enabling efficient decision making. This paper investigates the role of human priors for solving video games. Given a sample game, we conduct a series of ablation studies to quantify the importance of various priors. We do this by modifying the video game environment to systematically mask different types of visual information that could be used by humans as priors. We find that removal of some prior knowledge causes a drastic degradation in the speed with which human players solve the game, e.g. from 2 minutes to over 20 minutes. Furthermore, our results indicate that general priors, such as the importance of objects and visual consistency, are critical for efficient game-play.

Methods for neural network hyperparameter optimization and meta-modeling are computationally expensive due to the need to train a large number of model configurations. In this paper, we show that standard frequentist regression models can predict the final performance of partially trained model configurations using features based on network architectures, hyperparameters, and time series validation performance data. We empirically show that our performance prediction models are much more effective than prominent Bayesian counterparts, are simpler to implement, and are faster to train. Our models can predict final performance in both visual classification and language modeling domains, are effective for predicting performance of drastically varying model architectures, and can even generalize between model classes. Using these prediction models, we also propose an early stopping method for hyperparameter optimization and meta-modeling, which obtains a speedup of a factor up to 6x in both hyperparameter optimization and meta-modeling. Finally, we empirically show that our early stopping method can be seamlessly incorporated into both reinforcement learning-based architecture selection algorithms and bandit based search methods. Through extensive experimentation, we empirically show our performance prediction models and early stopping algorithm are state-of-the-art in terms of prediction accuracy and speedup achieved while still identifying the optimal model configurations.
tl;dr: We show that in contras to popular wisdom, the exploding gradient problem has not been solved and that it limits the depth to which MLPs can be effectively trained. We show why gradients explode and how ResNet handles them.

Whereas it is believed that techniques such as Adam, batch normalization and, more recently, SeLU nonlinearities ``solve'' the exploding gradient problem, we show that this is not the case and that in a range of popular MLP architectures, exploding gradients exist and that they limit the depth to which networks can be effectively trained, both in theory and in practice. We explain why exploding gradients occur and highlight the {\it collapsing domain problem}, which can arise in architectures that avoid exploding gradients.
ResNets have significantly lower gradients and thus can circumvent the exploding gradient problem, enabling the effective training of much deeper networks, which we show is a consequence of a surprising mathematical property. By noticing that {\it any neural network is a residual network}, we devise the {\it residual trick}, which reveals that introducing skip connections simplifies the network mathematically, and that this simplicity may be the major cause for their success.
tl;dr: We improve the running of all existing gradient descent algorithms.

Stochastic Gradient Descent or SGD is the most popular optimization algorithm for large-scale problems. SGD estimates the gradient by uniform sampling with sample size one. There have been several other works that suggest faster epoch wise convergence by using weighted non-uniform sampling for better gradient estimates. Unfortunately, the per-iteration cost of maintaining this adaptive distribution for gradient estimation is more than calculating the full gradient. As a result, the false impression of faster convergence in iterations leads to slower convergence in time, which we call a chicken-and-egg loop. In this paper, we break this barrier by providing the first demonstration of a sampling scheme, which leads to superior gradient estimation, while keeping the sampling cost per iteration similar to that of the uniform sampling. Such an algorithm is possible due to the sampling view of Locality Sensitive Hashing (LSH), which came to light recently. As a consequence of superior and fast estimation, we reduce the running time of all existing gradient descent algorithms. We demonstrate the benefits of our proposal on both SGD and AdaGrad.
tl;dr: We propose a new way to compress neural networks using probabilistic data structures.

The large memory requirements of deep neural networks strain the capabilities of many devices, limiting their deployment and adoption. Model compression methods effectively reduce the memory requirements of these models, usually through applying transformations such as weight pruning or quantization. In this paper, we present a novel scheme for lossy weight encoding which complements conventional compression techniques. The encoding is based on the Bloomier filter, a probabilistic data structure that can save space at the cost of introducing random errors. Leveraging the ability of neural networks to tolerate these imperfections and by re-training around the errors, the proposed technique, Weightless, can compress DNN weights by up to 496x; with the same model accuracy, this results in up to a 1.51x improvement over the state-of-the-art.

We provide a novel thinking of regularization neural networks. We smooth the objective of neural networks w.r.t small adversarial perturbations of the inputs. Different from previous works, we assume the adversarial perturbations are caused by the movement field. When the magnitude of movement field approaches 0, we call it virtual movement field. By introducing the movement field, we cast the problem of finding adversarial perturbations into the problem of finding adversarial movement field. By adding proper geometrical constraints to the movement field, such smoothness can be approximated in closed-form by solving a min-max problem and its geometric meaning is clear. We define the approximated smoothness as the regularization term. We derive three regularization terms as running examples which measure the smoothness w.r.t shift, rotation and scale respectively by adding different constraints. We evaluate our methods on synthetic data, MNIST and CIFAR-10. Experimental results show that our proposed method can significantly improve the baseline neural networks. Compared with the state of the art regularization methods, proposed method achieves a tradeoff between accuracy and geometrical interpretability as well as computational cost.
376. Fraternal Dropout
tl;dr: We propose to train two identical copies of an recurrent neural network (that share parameters) with different dropout masks while minimizing the difference between their (pre-softmax) predictions.

Recurrent neural networks (RNNs) are important class of architectures among neural networks useful for language modeling and sequential prediction. However, optimizing RNNs is known to be harder compared to feed-forward neural networks. A number of techniques have been proposed in literature to address this problem. In this paper we propose a simple technique called fraternal dropout that takes advantage of dropout to achieve this goal. Specifically, we propose to train two identical copies of an RNN (that share parameters) with different dropout masks while minimizing the difference between their (pre-softmax) predictions. In this way our regularization encourages the representations of RNNs to be invariant to dropout mask, thus being robust. We show that our regularization term is upper bounded by the expectation-linear dropout objective which has been shown to address the gap due to the difference between the train and inference phases of dropout. We evaluate our model and achieve state-of-the-art results in sequence modeling tasks on two benchmark datasets - Penn Treebank and Wikitext-2. We also show that our approach leads to performance improvement by a significant margin in image captioning (Microsoft COCO) and semi-supervised (CIFAR-10) tasks.
tl;dr: multi-modal imitation learning from unstructured demonstrations using stochastic neural network modeling intention.

Recent advances in learning from demonstrations (LfD) with deep neural networks have enabled learning complex robot skills that involve high dimensional perception such as raw image inputs.
LfD algorithms generally assume learning from single task demonstrations. In practice, however, it is more efficient for a teacher to demonstrate a multitude of tasks without careful task set up, labeling, and engineering. Unfortunately in such cases, traditional imitation learning techniques fail to represent the multi-modal nature of the data, and often result in sub-optimal behavior. In this paper we present an LfD approach for learning multiple modes of behavior from visual data. Our approach is based on a stochastic deep neural network (SNN), which represents the underlying intention in the demonstration as a stochastic activation in the network. We present an efficient algorithm for training SNNs, and for learning with vision inputs, we also propose an architecture that associates the intention with a stochastic attention module.
We demonstrate our method on real robot visual object reaching tasks, and show that
it can reliably learn the multiple behavior modes in the demonstration data. Video results are available at https://vimeo.com/240212286/fd401241b9.
tl;dr: A general framework for creating covariant graph neural networks

Most existing neural networks for learning graphs deal with the issue of permutation invariance by conceiving of the network as a message passing scheme, where each node sums the feature vectors coming from its neighbors. We argue that this imposes a limitation on their representation power, and instead propose a new general architecture for representing objects consisting of a hierarchy of parts, which we call Covariant Compositional Networks (CCNs). Here covariance means that the activation of each neuron must transform in a specific way under permutations, similarly to steerability in CNNs. We achieve covariance by making each activation transform according to a tensor representation of the permutation group, and derive the corresponding tensor aggregation rules that each neuron must implement. Experiments show that CCNs can outperform competing methods on some standard graph learning benchmarks.
tl;dr: Combining Imitation Learning and Reinforcement Learning to learn to outperform the expert

In this paper, we propose to combine imitation and reinforcement learning via the idea of reward shaping using an oracle. We study the effectiveness of the near- optimal cost-to-go oracle on the planning horizon and demonstrate that the cost- to-go oracle shortens the learner’s planning horizon as function of its accuracy: a globally optimal oracle can shorten the planning horizon to one, leading to a one- step greedy Markov Decision Process which is much easier to optimize, while an oracle that is far away from the optimality requires planning over a longer horizon to achieve near-optimal performance. Hence our new insight bridges the gap and interpolates between imitation learning and reinforcement learning. Motivated by the above mentioned insights, we propose Truncated HORizon Policy Search (THOR), a method that focuses on searching for policies that maximize the total reshaped reward over a finite planning horizon when the oracle is sub-optimal. We experimentally demonstrate that a gradient-based implementation of THOR can achieve superior performance compared to RL baselines and IL baselines even when the oracle is sub-optimal.

\emph{Tensor train (TT) decomposition} is a powerful representation for high-order tensors, which has been successfully applied to various machine learning tasks in recent years. In this paper, we propose a more generalized tensor decomposition with ring structure network by employing circular multilinear products over a sequence of lower-order core tensors, which is termed as TR representation. Several learning algorithms including blockwise ALS with adaptive tensor ranks and SGD with high scalability are presented. Furthermore, the mathematical properties are investigated, which enables us to perform basic algebra operations in a computationally efficiently way by using TR representations. Experimental results on synthetic signals and real-world datasets demonstrate the effectiveness of TR model and the learning algorithms. In particular, we show that the structure information and high-order correlations within a 2D image can be captured efficiently by employing tensorization and TR representation.
tl;dr: It is a mostly theoretical paper that describes the challenges in disentangling factors of variation, using autoencoders and GAN.

We study the problem of building models that disentangle independent factors of variation. Such models encode features that can efficiently be used for classification and to transfer attributes between different images in image synthesis. As data we use a weakly labeled training set, where labels indicate what single factor has changed between two data samples, although the relative value of the change is unknown. This labeling is of particular interest as it may be readily available without annotation costs. We introduce an autoencoder model and train it through constraints on image pairs and triplets. We show the role of feature dimensionality and adversarial training theoretically and experimentally. We formally prove the existence of the reference ambiguity, which is inherently present in the disentangling task when weakly labeled data is used. The numerical value of a factor has different meaning in different reference frames. When the reference depends on other factors, transferring that factor becomes ambiguous. We demonstrate experimentally that the proposed model can successfully transfer attributes on several datasets, but show also cases when the reference ambiguity occurs.
tl;dr: To understand GAN training, we define simple GAN dynamics, and show quantitative differences between optimal and first order updates in this model.

Generative Adversarial Networks (GANs) have been proposed as an approach to learning generative models. While GANs have demonstrated promising performance on multiple vision tasks, their learning dynamics are not yet well understood, neither in theory nor in practice. In particular, the work in this domain has been focused so far only on understanding the properties of the stationary solutions that this dynamics might converge to, and of the behavior of that dynamics in this solutions’ immediate neighborhood.
To address this issue, in this work we take a first step towards a principled study of the GAN dynamics itself. To this end, we propose a model that, on one hand, exhibits several of the common problematic convergence behaviors (e.g., vanishing gradient, mode collapse, diverging or oscillatory behavior), but on the other hand, is sufficiently simple to enable rigorous convergence analysis.
This methodology enables us to exhibit an interesting phenomena: a GAN with an optimal discriminator provably converges, while guiding the GAN training using only a first order approximation of the discriminator leads to unstable GAN dynamics and mode collapse. This suggests that such usage of the first order approximation of the discriminator, which is a de-facto standard in all the existing GAN dynamics, might be one of the factors that makes GAN training so challenging in practice. Additionally, our convergence result constitutes the first rigorous analysis of a dynamics of a concrete parametric GAN.

We propose DropMax, a stochastic version of softmax classifier which at each iteration drops non-target classes with some probability, for each instance. Specifically, we overlay binary masking variables over class output probabilities, which are learned based on the input via regularized variational inference. This stochastic regularization has an effect of building an ensemble classifier out of combinatorial number of classifiers with different decision boundaries. Moreover, the learning of dropout probabilities for non-target classes on each instance allows the classifier to focus more on classification against the most confusing classes. We validate our model on multiple public datasets for classification, on which it obtains improved accuracy over regular softmax classifier and other baselines. Further analysis of the learned dropout masks shows that our model indeed selects confusing classes more often when it performs classification.
384. Learning to Infer
tl;dr: We propose a new class of inference models that iteratively encode gradients to estimate approximate posterior distributions.

Inference models, which replace an optimization-based inference procedure with a learned model, have been fundamental in advancing Bayesian deep learning, the most notable example being variational auto-encoders (VAEs). In this paper, we propose iterative inference models, which learn how to optimize a variational lower bound through repeatedly encoding gradients. Our approach generalizes VAEs under certain conditions, and by viewing VAEs in the context of iterative inference, we provide further insight into several recent empirical findings. We demonstrate the inference optimization capabilities of iterative inference models, explore unique aspects of these models, and show that they outperform standard inference models on typical benchmark data sets.
tl;dr: We introduce a novel method to train Seq2Seq models with language models that converge faster, generalize better and can almost completely transfer to a new domain using less than 10% of labeled data.

Sequence-to-sequence (Seq2Seq) models with attention have excelled at tasks which involve generating natural language sentences such as machine translation, image captioning and speech recognition. Performance has further been improved by leveraging unlabeled data, often in the form of a language model. In this work, we present the Cold Fusion method, which leverages a pre-trained language model during training, and show its effectiveness on the speech recognition task. We show that Seq2Seq models with Cold Fusion are able to better utilize language information enjoying i) faster convergence and better generalization, and ii) almost complete transfer to a new domain while using less than 10% of the labeled training data.
tl;dr: A method for performing automated design on real world objects such as heat sinks and wing airfoils that makes use of neural networks and gradient descent.

We propose a novel method that makes use of deep neural networks and gradient decent to perform automated design on complex real world engineering tasks. Our approach works by training a neural network to mimic the fitness function of a design optimization task and then, using the differential nature of the neural network, perform gradient decent to maximize the fitness. We demonstrate this methods effectiveness by designing an optimized heat sink and both 2D and 3D airfoils that maximize the lift drag ratio under steady state flow conditions. We highlight that our method has two distinct benefits over other automated design approaches. First, evaluating the neural networks prediction of fitness can be orders of magnitude faster then simulating the system of interest. Second, using gradient decent allows the design space to be searched much more efficiently then other gradient free methods. These two strengths work together to overcome some of the current shortcomings of automated design.
tl;dr: An approach that speeds up neural architecture search by 10x, whilst using 100x less computing resource.

We propose Efficient Neural Architecture Search (ENAS), a faster and less expensive approach to automated model design than previous methods. In ENAS, a controller learns to discover neural network architectures by searching for an optimal path within a larger model. The controller is trained with policy gradient to select a path that maximizes the expected reward on the validation set. Meanwhile the model corresponding to the selected path is trained to minimize the cross entropy loss. On the Penn Treebank dataset, ENAS can discover a novel architecture thats achieves a test perplexity of 57.8, which is state-of-the-art among automatic model design methods on Penn Treebank. On the CIFAR-10 dataset, ENAS can design novel architectures that achieve a test error of 2.89%, close to the 2.65% achieved by standard NAS (Zoph et al., 2017). Most importantly, our experiments show that ENAS is more than 10x faster and 100x less resource-demanding than NAS.
tl;dr: A neural architecture for scoring and ranking program repair candidates to perform semantic program repair statically without access to unit tests.

We study the problem of semantic code repair, which can be broadly defined as automatically fixing non-syntactic bugs in source code. The majority of past work in semantic code repair assumed access to unit tests against which candidate repairs could be validated. In contrast, the goal here is to develop a strong statistical model to accurately predict both bug locations and exact fixes without access to information about the intended correct behavior of the program. Achieving such a goal requires a robust contextual repair model, which we train on a large corpus of real-world source code that has been augmented with synthetically injected bugs. Our framework adopts a two-stage approach where first a large set of repair candidates are generated by rule-based processors, and then these candidates are scored by a statistical model using a novel neural network architecture which we refer to as Share, Specialize, and Compete. Specifically, the architecture (1) generates a shared encoding of the source code using an RNN over the abstract syntax tree, (2) scores each candidate repair using specialized network modules, and (3) then normalizes these scores together so they can compete against one another in comparable probability space. We evaluate our model on a real-world test set gathered from GitHub containing four common categories of bugs. Our model is able to predict the exact correct repair 41% of the time with a single guess, compared to 13% accuracy for an attentional sequence-to-sequence model.
tl;dr: Explaining the generalization of stochastic deep learning algorithms, theoretically and empirically, via ensemble robustness

The question why deep learning algorithms generalize so well has attracted increasing
research interest. However, most of the well-established approaches,
such as hypothesis capacity, stability or sparseness, have not provided complete
explanations (Zhang et al., 2016; Kawaguchi et al., 2017). In this work, we focus
on the robustness approach (Xu & Mannor, 2012), i.e., if the error of a hypothesis
will not change much due to perturbations of its training examples, then it
will also generalize well. As most deep learning algorithms are stochastic (e.g.,
Stochastic Gradient Descent, Dropout, and Bayes-by-backprop), we revisit the robustness
arguments of Xu & Mannor, and introduce a new approach – ensemble
robustness – that concerns the robustness of a population of hypotheses. Through
the lens of ensemble robustness, we reveal that a stochastic learning algorithm can
generalize well as long as its sensitiveness to adversarial perturbations is bounded
in average over training examples. Moreover, an algorithm may be sensitive to
some adversarial examples (Goodfellow et al., 2015) but still generalize well. To
support our claims, we provide extensive simulations for different deep learning
algorithms and different network architectures exhibiting a strong correlation between
ensemble robustness and the ability to generalize.
tl;dr: We use search techniques to discover novel activation functions, and our best discovered activation function, f(x) = x * sigmoid(beta * x), outperforms ReLU on a number of challenging tasks like ImageNet.

The choice of activation functions in deep networks has a significant effect on the training dynamics and task performance. Currently, the most successful and widely-used activation function is the Rectified Linear Unit (ReLU). Although various hand-designed alternatives to ReLU have been proposed, none have managed to replace it due to inconsistent gains. In this work, we propose to leverage automatic search techniques to discover new activation functions. Using a combination of exhaustive and reinforcement learning-based search, we discover multiple novel activation functions. We verify the effectiveness of the searches by conducting an empirical evaluation with the best discovered activation function. Our experiments show that the best discovered activation function, f(x) = x * sigmoid(beta * x), which we name Swish, tends to work better than ReLU on deeper models across a number of challenging datasets. For example, simply replacing ReLUs with Swish units improves top-1 classification accuracy on ImageNet by 0.9% for Mobile NASNet-A and 0.6% for Inception-ResNet-v2. The simplicity of Swish and its similarity to ReLU make it easy for practitioners to replace ReLUs with Swish units in any neural network.
tl;dr: Using a novel representation of symmetric linear dynamical systems with a latent state, we formulate optimal control as a convex program, giving the first polynomial-time algorithm that solves optimal control with sample complexity only polylogarithmic in the time horizon.

We study the control of symmetric linear dynamical systems with unknown dynamics and a hidden state. Using a recent spectral filtering technique for concisely representing such systems in a linear basis, we formulate optimal control in this setting as a convex program. This approach eliminates the need to solve the non-convex problem of explicit identification of the system and its latent state, and allows for provable optimality guarantees for the control signal. We give the first efficient algorithm for finding the optimal control signal with an arbitrary time horizon T, with sample complexity (number of training rollouts) polynomial only in log(T) and other relevant parameters.
tl;dr: using deep neural networks and clever algorithms to capture human mental visual concepts

Understanding how people represent categories is a core problem in cognitive science, with the flexibility of human learning remaining a gold standard to which modern artificial intelligence and machine learning aspire. Decades of psychological research have yielded a variety of formal theories of categories, yet validating these theories with naturalistic stimuli remains a challenge. The problem is that human category representations cannot be directly observed and running informative experiments with naturalistic stimuli such as images requires having a workable representation of these stimuli. Deep neural networks have recently been successful in a range of computer vision tasks and provide a way to represent the features of images. In this paper, we introduce a method for estimating the structure of human categories that draws on ideas from both cognitive science and machine learning, blending human-based algorithms with state-of-the-art deep representation learners. We provide qualitative and quantitative results as a proof of concept for the feasibility of the method. Samples drawn from human distributions rival the quality of current state-of-the-art generative models and outperform alternative methods for estimating the structure of human categories.
tl;dr: We extend recent insights related to softmax consistency to achieve state-of-the-art results in continuous control.

Trust region methods, such as TRPO, are often used to stabilize policy optimization algorithms in reinforcement learning (RL). While current trust region strategies are effective for continuous control, they typically require a large amount of on-policy interaction with the environment. To address this problem, we propose an off-policy trust region method, Trust-PCL, which exploits an observation that the optimal policy and state values of a maximum reward objective with a relative-entropy regularizer satisfy a set of multi-step pathwise consistencies along any path. The introduction of relative entropy regularization allows Trust-PCL to maintain optimization stability while exploiting off-policy data to improve sample efficiency. When evaluated on a number of continuous control tasks, Trust-PCL significantly improves the solution quality and sample efficiency of TRPO.
tl;dr: the proposed models with external knowledge further improve the state of the art on the SNLI dataset.

Modeling informal inference in natural language is very challenging. With the recent availability of large annotated data, it has become feasible to train complex models such as neural networks to perform natural language inference (NLI), which have achieved state-of-the-art performance. Although there exist relatively large annotated data, can machines learn all knowledge needed to perform NLI from the data? If not, how can NLI models benefit from external knowledge and how to build NLI models to leverage it? In this paper, we aim to answer these questions by enriching the state-of-the-art neural natural language inference models with external knowledge. We demonstrate that the proposed models with external knowledge further improve the state of the art on the Stanford Natural Language Inference (SNLI) dataset.
tl;dr: A new regularization term can improve your training of wasserstein gans

Since their invention, generative adversarial networks (GANs) have become a popular approach for learning to model a distribution of real (unlabeled) data. Convergence problems during training are overcome by Wasserstein GANs which minimize the distance between the model and the empirical distribution in terms of a different metric, but thereby introduce a Lipschitz constraint into the optimization problem. A simple way to enforce the Lipschitz constraint on the class of functions, which can be modeled by the neural network, is weight clipping. Augmenting the loss by a regularization term that penalizes the deviation of the gradient norm of the critic (as a function of the network's input) from one, was proposed as an alternative that improves training. We present theoretical arguments why using a weaker regularization term enforcing the Lipschitz constraint is preferable. These arguments are supported by experimental results on several data sets.
tl;dr: Incorporating the ability to say I-don't-know can improve the fairness of a classifier without sacrificing too much accuracy, and this improvement magnifies when the classifier has insight into downstream decision-making.

When machine learning models are used for high-stakes decisions, they should predict accurately, fairly, and responsibly. To fulfill these three requirements, a model must be able to output a reject option (i.e. say "``I Don't Know") when it is not qualified to make a prediction. In this work, we propose learning to defer, a method by which a model can defer judgment to a downstream decision-maker such as a human user. We show that learning to defer generalizes the rejection learning framework in two ways: by considering the effect of other agents in the decision-making process, and by allowing for optimization of complex objectives. We propose a learning algorithm which accounts for potential biases held by decision-makerslater in a pipeline. Experiments on real-world datasets demonstrate that learning
to defer can make a model not only more accurate but also less biased. Even when
operated by highly biased users, we show that
deferring models can still greatly improve the fairness of the entire pipeline.
tl;dr: A new generative model for discrete structured data. The proposed stochastic lazy attribute converts the offline semantic check into online guidance for stochastic decoding, which effectively addresses the constraints in syntax and semantics, and also achieves superior performance

Deep generative models have been enjoying success in modeling continuous data. However it remains challenging to capture the representations for discrete structures with formal grammars and semantics, e.g., computer programs and molecular structures. How to generate both syntactically and semantically correct data still remains largely an open problem. Inspired by the theory of compiler where syntax and semantics check is done via syntax-directed translation (SDT), we propose a novel syntax-directed variational autoencoder (SD-VAE) by introducing stochastic lazy attributes. This approach converts the offline SDT check into on-the-fly generated guidance for constraining the decoder. Comparing to the state-of-the-art methods, our approach enforces constraints on the output space so that the output will be not only syntactically valid, but also semantically reasonable. We evaluate the proposed model with applications in programming language and molecules, including reconstruction and program/molecule optimization. The results demonstrate the effectiveness in incorporating syntactic and semantic constraints in discrete generative models, which is significantly better than current state-of-the-art approaches.
tl;dr: We train predictive models on proprioceptive information and show they represent properties of external objects.

We consider the setting of an agent with a fixed body interacting with an unknown and uncertain external world. We show that models trained to predict proprioceptive information about the agent's body come to represent objects in the external world. In spite of being trained with only internally available signals, these dynamic body models come to represent external objects through the necessity of predicting their effects on the agent's own body. That is, the model learns holistic persistent representations of objects in the world, even though the only training signals are body signals. Our dynamics model is able to successfully predict distributions over 132 sensor readings over 100 steps into the future and we demonstrate that even when the body is no longer in contact with an object, the latent variables of the dynamics model continue to represent its shape. We show that active data collection by maximizing the entropy of predictions about the body---touch sensors, proprioception and vestibular information---leads to learning of dynamic models that show superior performance when used for control. We also collect data from a real robotic hand and show that the same models can be used to answer questions about properties of objects in the real world. Videos with qualitative results of our models are available at https://goo.gl/mZuqAV.
tl;dr: We propose a simple and efficent method for architecture search for convolutional neural networks.

Neural networks have recently had a lot of success for many tasks. However, neural
network architectures that perform well are still typically designed manually
by experts in a cumbersome trial-and-error process. We propose a new method
to automatically search for well-performing CNN architectures based on a simple
hill climbing procedure whose operators apply network morphisms, followed
by short optimization runs by cosine annealing. Surprisingly, this simple method
yields competitive results, despite only requiring resources in the same order of
magnitude as training a single network. E.g., on CIFAR-10, our method designs
and trains networks with an error rate below 6% in only 12 hours on a single GPU;
training for one day reduces this error further, to almost 5%.
tl;dr: We propose a neural network that is able to generate topic-specific questions.

Asking questions is an important ability for a chatbot. This paper focuses on question generation. Although there are existing works on question generation based on a piece of descriptive text, it remains to be a very challenging problem. In the paper, we propose a new question generation problem, which also requires the input of a target topic in addition to a piece of descriptive text. The key reason for proposing the new problem is that in practical applications, we found that useful questions need to be targeted toward some relevant topics. One almost never asks a random question in a conversation. Due to the fact that given a descriptive text, it is often possible to ask many types of questions, generating a question without knowing what it is about is of limited use. To solve the problem, we propose a novel neural network that is able to generate topic-specific questions. One major advantage of this model is that it can be trained directly using a question-answering corpus without requiring any additional annotations like annotating topics in the questions or answers. Experimental results show that our model outperforms the state-of-the-art baseline.
tl;dr: We build a stronger natural language generator by discriminatively training scoring functions that rank candidate generations with respect to various qualities of good writing.

Recurrent Neural Networks (RNNs) are powerful autoregressive sequence models for learning prevalent patterns in natural language. Yet language generated by RNNs often shows several degenerate characteristics that are uncommon in human language; while fluent, RNN language production can be overly generic, repetitive, and even self-contradictory. We postulate that the objective function optimized by RNN language models, which amounts to the overall perplexity of a text, is not expressive enough to capture the abstract qualities of good generation such as Grice’s Maxims. In this paper, we introduce a general learning framework that can construct a decoding objective better suited for generation. Starting with a generatively trained RNN language model, our framework learns to construct a substantially stronger generator by combining several discriminatively trained models that can collectively address the limitations of RNN generation. Human evaluation demonstrates that text generated by the resulting generator is preferred over that of baselines by a large margin and significantly enhances the overall coherence, style, and information content of the generated text.
402. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
tl;dr: We propose soft actor-critic, an off-policy actor-critic deep RL algorithm based on the maximum entropy reinforcement learning framework.

Model-free deep reinforcement learning (RL) algorithms have been demonstrated on a range of challenging decision making and control tasks. However, these methods typically suffer from two major challenges: very high sample complexity and brittle convergence properties, which necessitate meticulous hyperparameter tuning. Both of these challenges severely limit the applicability of such methods to complex, real-world domains. In this paper, we propose soft actor-critic, an off-policy actor-critic deep RL algorithm based on the maximum entropy reinforcement learning framework. In this framework, the actor aims to maximize expected reward while also maximizing entropy - that is, succeed at the task while acting as randomly as possible. Prior deep RL methods based on this framework have been formulated as either off-policy Q-learning, or on-policy policy gradient methods. By combining off-policy updates with a stable stochastic actor-critic formulation, our method achieves state-of-the-art performance on a range of continuous control benchmark tasks, outperforming prior on-policy and off-policy methods. Furthermore, we demonstrate that, in contrast to other off-policy algorithms, our approach is very stable, achieving very similar performance across different random seeds.
tl;dr: A faster method for generating node embeddings that employs a number of permutations over a node's immediate neighborhood as context to generate its representation.

Representation learning is one of the foundations of Deep Learning and allowed important improvements on several Machine Learning tasks, such as Neural Machine Translation, Question Answering and Speech Recognition. Recent works have proposed new methods for learning representations for nodes and edges in graphs. Several of these methods are based on the SkipGram algorithm, and they usually process a large number of multi-hop neighbors in order to produce the context from which node representations are learned. In this paper, we propose an effective and also efficient method for generating node embeddings in graphs that employs a restricted number of permutations over the immediate neighborhood of a node as context to generate its representation, thus ego-centric representations. We present a thorough evaluation showing that our method outperforms state-of-the-art methods in six different datasets related to the problems of link prediction and node classification, being one to three orders of magnitude faster than baselines when generating node embeddings for very large graphs.
tl;dr: We define a flexible DSL for RNN architecture generation that allows RNNs of varying size and complexity and propose a ranking function that represents RNNs as recursive neural networks, simulating their performance to decide on the most promising architectures.

The process of designing neural architectures requires expert knowledge and extensive trial and error.
While automated architecture search may simplify these requirements, the recurrent neural network (RNN) architectures generated by existing methods are limited in both flexibility and components.
We propose a domain-specific language (DSL) for use in automated architecture search which can produce novel RNNs of arbitrary depth and width.
The DSL is flexible enough to define standard architectures such as the Gated Recurrent Unit and Long Short Term Memory and allows the introduction of non-standard RNN components such as trigonometric curves and layer normalization. Using two different candidate generation techniques, random search with a ranking function and reinforcement learning,
we explore the novel architectures produced by the RNN DSL for language modeling and machine translation domains.
The resulting architectures do not follow human intuition yet perform well on their targeted tasks, suggesting the space of usable RNN architectures is far larger than previously assumed.
tl;dr: We proposed a supervised algorithm, DNA-GAN, to disentangle multiple attributes of images.

Disentangling factors of variation has always been a challenging problem in representation learning. Existing algorithms suffer from many limitations, such as unpredictable disentangling factors, bad quality of generated images from encodings, lack of identity information, etc. In this paper, we proposed a supervised algorithm called DNA-GAN trying to disentangle different attributes of images. The latent representations of images are DNA-like, in which each individual piece represents an independent factor of variation. By annihilating the recessive piece and swapping a certain piece of two latent representations, we obtain another two different representations which could be decoded into images. In order to obtain realistic images and also disentangled representations, we introduced the discriminator for adversarial training. Experiments on Multi-PIE and CelebA datasets demonstrate the effectiveness of our method and the advantage of overcoming limitations existing in other methods.

Collecting a large dataset with high quality annotations is expensive and time-consuming. Recently, Shrivastava et al. (2017) propose Simulated+Unsupervised (S+U) learning: It first learns a mapping from synthetic data to real data, translates a large amount of labeled synthetic data to the ones that resemble real data, and then trains a learning model on the translated data. Bousmalis et al. (2017) propose a similar framework that jointly trains a translation mapping and a learning model.
While these algorithms are shown to achieve the state-of-the-art performances on various tasks, it may have a room for improvement, as they do not fully leverage flexibility of data simulation process and consider only the forward (synthetic to real) mapping. While these algorithms are shown to achieve the state-of-the-art performances on various tasks, it may have a room for improvement, as it does not fully leverage flexibility of data simulation process and consider only the forward (synthetic to real) mapping. Inspired by this limitation, we propose a new S+U learning algorithm, which fully leverage the flexibility of data simulators and bidirectional mappings between synthetic data and real data. We show that our approach achieves the improved performance on the gaze estimation task, outperforming (Shrivastava et al., 2017).
tl;dr: We demonstrate that large, but pruned models (large-sparse) outperform their smaller, but dense (small-dense) counterparts with identical memory footprint.

Model pruning seeks to induce sparsity in a deep neural network's various connection matrices, thereby reducing the number of nonzero-valued parameters in the model. Recent reports (Han et al., 2015; Narang et al., 2017) prune deep networks at the cost of only a marginal loss in accuracy and achieve a sizable reduction in model size. This hints at the possibility that the baseline models in these experiments are perhaps severely over-parameterized at the outset and a viable alternative for model compression might be to simply reduce the number of hidden units while maintaining the model's dense connection structure, exposing a similar trade-off in model size and accuracy. We investigate these two distinct paths for model compression within the context of energy-efficient inference in resource-constrained environments and propose a new gradual pruning technique that is simple and straightforward to apply across a variety of models/datasets with minimal tuning and can be seamlessly incorporated within the training process. We compare the accuracy of large, but pruned models (large-sparse) and their smaller, but dense (small-dense) counterparts with identical memory footprint. Across a broad range of neural network architectures (deep CNNs, stacked LSTM, and seq2seq LSTM models), we find large-sparse models to consistently outperform small-dense models and achieve up to 10x reduction in number of non-zero parameters with minimal loss in accuracy.
tl;dr: By introducing the notion of an optimal representation space, we provide a theoretical argument and experimental validation that an unsupervised model for sentences can perform well on both supervised similarity and unsupervised transfer tasks.

Experimental evidence indicates that simple models outperform complex deep networks on many unsupervised similarity tasks. Introducing the concept of an optimal representation space, we provide a simple theoretical resolution to this apparent paradox. In addition, we present a straightforward procedure that, without any retraining or architectural modifications, allows deep recurrent models to perform equally well (and sometimes better) when compared to shallow models. To validate our analysis, we conduct a set of consistent empirical evaluations and introduce several new sentence embedding models in the process. Even though this work is presented within the context of natural language processing, the insights are readily applicable to other domains that rely on distributed representations for transfer tasks.
tl;dr: A novel RNN model which outperforms significantly the current frontier of models in a variety of sequential tasks.

The concepts of unitary evolution matrices and associative memory have boosted the field of Recurrent Neural Networks (RNN) to state-of-the-art performance in a variety of sequential tasks. However, RNN still has a limited capacity to manipulate long-term memory. To bypass this weakness the most successful applications of RNN use external techniques such as attention mechanisms. In this paper we propose a novel RNN model that unifies the state-of-the-art approaches: Rotational Unit of Memory (RUM). The core of RUM is its rotational operation, which is, naturally, a unitary matrix, providing architectures with the power to learn long-term dependencies by overcoming the vanishing and exploding gradients problem. Moreover, the rotational unit also serves as associative memory. We evaluate our model on synthetic memorization, question answering and language modeling tasks. RUM learns the Copying Memory task completely and improves the state-of-the-art result in the Recall task. RUM’s performance in the bAbI Question Answering task is comparable to that of models with attention mechanism. We also improve the state-of-the-art result to 1.189 bits-per-character (BPC) loss in the Character Level Penn Treebank (PTB) task, which is to signify the applications of RUM to real-world sequential data. The universality of our construction, at the core of RNN, establishes RUM as a promising approach to language modeling, speech recognition and machine translation.

Policy gradient reinforcement learning has been applied to two-player alternate-turn zero-sum games, e.g., in AlphaGo, self-play REINFORCE was used to improve the neural net model after supervised learning. In this paper, we emphasize that two-player zero-sum games with alternating turns, which have been previously formulated as Alternating Markov Games (AMGs), are different from standard MDP because of their two-agent nature. We exploit the difference in associated Bellman equations, which leads to different policy iteration algorithms. As policy gradient method is a kind of generalized policy iteration, we show how these differences in policy iteration are reflected in policy gradient for AMGs. We formulate an adversarial policy gradient and discuss potential possibilities for developing better policy gradient methods other than self-play REINFORCE. The core idea is to estimate the minimum rather than the mean for the “critic”. Experimental results on the game of Hex show the modified Monte Carlo policy gradient methods are able to learn better pure neural net policies than the REINFORCE variants. To apply learned neural weights to multiple board sizes Hex, we describe a board-size independent neural net architecture. We show that when combined with search, using a single neural net model, the resulting program consistently beats MoHex 2.0, the state-of-the-art computer Hex player, on board sizes from 9×9 to 13×13.
tl;dr: Self-training with different views of the input gives excellent results for semi-supervised image recognition, sequence tagging, and dependency parsing.

We present Cross-View Training (CVT), a simple but effective method for deep semi-supervised learning. On labeled examples, the model is trained with standard cross-entropy loss. On an unlabeled example, the model first performs inference (acting as a "teacher") to produce soft targets. The model then learns from these soft targets (acting as a ``"student"). We deviate from prior work by adding multiple auxiliary student prediction layers to the model. The input to each student layer is a sub-network of the full model that has a restricted view of the input (e.g., only seeing one region of an image). The students can learn from the teacher (the full model) because the teacher sees more of each example. Concurrently, the students improve the quality of the representations used by the teacher as they learn to make predictions with limited data. When combined with Virtual Adversarial Training, CVT improves upon the current state-of-the-art on semi-supervised CIFAR-10 and semi-supervised SVHN. We also apply CVT to train models on five natural language processing tasks using hundreds of millions of sentences of unlabeled data. On all tasks CVT substantially outperforms supervised learning alone, resulting in models that improve upon or are competitive with the current state-of-the-art.

We propose a simple extension to the ReLU-family of activation functions that allows them to shift the mean activation across a layer towards zero. Combined with proper weight initialization, this alleviates the need for normalization layers. We explore the training of deep vanilla recurrent neural networks (RNNs) with up to 144 layers, and show that bipolar activation functions help learning in this setting. On the Penn Treebank and Text8 language modeling tasks we obtain competitive results, improving on the best reported results for non-gated networks. In experiments with convolutional neural networks without batch normalization, we find that bipolar activations produce a faster drop in training error, and results in a lower test error on the CIFAR-10 classification task.

The Fisher information metric is an important foundation of information geometry, wherein it allows us to approximate the local geometry of a probability distribution. Recurrent neural networks such as the Sequence-to-Sequence (Seq2Seq) networks that have lately been used to yield state-of-the-art performance on speech translation or image captioning have so far ignored the geometry of the latent embedding, that they iteratively learn. We propose the information geometric Seq2Seq (GeoSeq2Seq) network which abridges the gap between deep recurrent neural networks and information geometry. Specifically, the latent embedding offered by a recurrent network is encoded as a Fisher kernel of a parametric Gaussian Mixture Model, a formalism common in computer vision. We utilise such a network to predict the shortest routes between two nodes of a graph by learning the adjacency matrix using the GeoSeq2Seq formalism; our results show that for such a problem the probabilistic representation of the latent embedding supersedes the non-probabilistic embedding by 10-15\%.

Program translation is an important tool to migrate legacy code in one language into an ecosystem built in a different language. In this work, we are the first to consider employing deep neural networks toward tackling this problem. We observe that program translation is a modular procedure, in which a sub-tree of the source tree is translated into the corresponding target sub-tree at each step. To capture this intuition, we design a tree-to-tree neural network as an encoder-decoder architecture to translate a source tree into a target one. Meanwhile, we develop an attention mechanism for the tree-to-tree model, so that when the decoder expands one non-terminal in the target tree, the attention mechanism locates the corresponding sub-tree in the source tree to guide the expansion of the decoder. We evaluate the program translation capability of our tree-to-tree model against several state-of-the-art approaches. Compared against other neural translation models, we observe that our approach is consistently better than the baselines with a margin of up to 15 points. Further, our approach can improve the previous state-of-the-art program translation approaches by a margin of 20 points on the translation of real-world projects.
tl;dr: The loss surface is *very* degenerate, and there are no barriers between large batch and small batch solutions.

We study the properties of common loss surfaces through their Hessian matrix. In particular, in the context of deep learning, we empirically show that the spectrum of the Hessian is composed of two parts: (1) the bulk centered near zero, (2) and outliers away from the bulk. We present numerical evidence and mathematical justifications to the following conjectures laid out by Sagun et. al. (2016): Fixing data, increasing the number of parameters merely scales the bulk of the spectrum; fixing the dimension and changing the data (for instance adding more clusters or making the data less separable) only affects the outliers. We believe that our observations have striking implications for non-convex optimization in high dimensions. First, the *flatness* of such landscapes (which can be measured by the singularity of the Hessian) implies that classical notions of basins of attraction may be quite misleading. And that the discussion of wide/narrow basins may be in need of a new perspective around over-parametrization and redundancy that are able to create *large* connected components at the bottom of the landscape. Second, the dependence of a small number of large eigenvalues to the data distribution can be linked to the spectrum of the covariance matrix of gradients of model outputs. With this in mind, we may reevaluate the connections within the data-architecture-algorithm framework of a model, hoping that it would shed light on the geometry of high-dimensional and non-convex spaces in modern applications. In particular, we present a case that links the two observations: small and large batch gradient descent appear to converge to different basins of attraction but we show that they are in fact connected through their flat region and so belong to the same basin.
tl;dr: We explore the structure of neural loss functions, and the effect of loss landscapes on generalization, using a range of visualization methods.

Neural network training relies on our ability to find ````````"good" minimizers of highly non-convex loss functions. It is well known that certain network architecture designs (e.g., skip connections) produce loss functions that train easier, and well-chosen training parameters (batch size, learning rate, optimizer) produce minimizers that generalize better. However, the reasons for these differences, and their effect on the underlying loss landscape, is not well understood.
In this paper, we explore the structure of neural loss functions, and the effect of loss landscapes on generalization, using a range of visualization methods. First, we introduce a simple ``"filter normalization" method that helps us visualize loss function curvature, and make meaningful side-by-side comparisons between loss functions. Then, using a variety of visualizations, we explore how network architecture effects the loss landscape, and how training parameters affect the shape of minimizers.
tl;dr: We introduce theory to explain the failure of GANs on complex datasets and propose a solution to fix it.

Generative Adversarial Networks (GANs), when trained on large datasets with diverse modes, are known to produce conflated images which do not distinctly belong to any of the modes. We hypothesize that this problem occurs due to the interaction between two facts: (1) For datasets with large variety, it is likely that the modes lie on separate manifolds. (2) The generator (G) is formulated as a continuous function, and the input noise is derived from a connected set, due to which G's output is a connected set. If G covers all modes, then there must be some portion of G's output which connects them. This corresponds to undesirable, conflated images. We develop theoretical arguments to support these intuitions. We propose a novel method to break the second assumption via learnable discontinuities in the latent noise space. Equivalently, it can be viewed as training several generators, thus creating discontinuities in the G function. We also augment the GAN formulation with a classifier C that predicts which noise partition/generator produced the output images, encouraging diversity between each partition/generator. We experiment on MNIST, celebA, STL-10, and a difficult dataset with clearly distinct modes, and show that the noise partitions correspond to different modes of the data distribution, and produce images of superior quality.
tl;dr: Parametric adversarial divergences implicitly define more meaningful task losses for generative modeling, we make parallels with structured prediction to study the properties of these divergences and their ability to encode the task of interest.

Generative modeling of high dimensional data like images is a notoriously difficult and ill-defined problem. In particular, how to evaluate a learned generative model is unclear.
In this paper, we argue that *adversarial learning*, pioneered with generative adversarial networks (GANs), provides an interesting framework to implicitly define more meaningful task losses for unsupervised tasks, such as for generating "visually realistic" images. By relating GANs and structured prediction under the framework of statistical decision theory, we put into light links between recent advances in structured prediction theory and the choice of the divergence in GANs. We argue that the insights about the notions of "hard" and "easy" to learn losses can be analogously extended to adversarial divergences. We also discuss the attractive properties of parametric adversarial divergences for generative modeling, and perform experiments to show the importance of choosing a divergence that reflects the final task.

Generative Adversarial Networks (GANs) learn a generative model by playing an adversarial game between a generator and an auxiliary discriminator, which classifies data samples vs. generated ones. However, it does not explicitly model feature co-occurrences in samples. In this paper, we propose a novel Autoregressive Generative Adversarial Network (ARGAN), that models the latent distribution of data using an autoregressive model, rather than relying on binary classification of samples into data/generated categories. In this way, feature co-occurrences in samples can be more efficiently captured. Our model was evaluated on two widely used datasets: CIFAR-10 and STL-10. Its performance is competitive with respect to other GAN models both quantitatively and qualitatively.
tl;dr: Proposed methods for time-dependent event representation and regularization for sequence prediction; Evaluated these methods on five datasets that involve a range of sequence prediction tasks.

Existing sequence prediction methods are mostly concerned with time-independent sequences, in which the actual time span between events is irrelevant and the distance between events is simply the difference between their order positions in the sequence. While this time-independent view of sequences is applicable for data such as natural languages, e.g., dealing with words in a sentence, it is inappropriate and inefficient for many real world events that are observed and collected at unequally spaced points of time as they naturally arise, e.g., when a person goes to a grocery store or makes a phone call. The time span between events can carry important information about the sequence dependence of human behaviors. In this work, we propose a set of methods for using time in sequence prediction. Because neural sequence models such as RNN are more amenable for handling token-like input, we propose two methods for time-dependent event representation, based on the intuition on how time is tokenized in everyday life and previous work on embedding contextualization. We also introduce two methods for using next event duration as regularization for training a sequence prediction model. We discuss these methods based on recurrent neural nets. We evaluate these methods as well as baseline models on five datasets that resemble a variety of sequence prediction tasks. The experiments revealed that the proposed methods offer accuracy gain over baseline models in a range of settings.
tl;dr: We describe a biologically plausible learning algorithm for fixed point recurrent networks without tied weights

The biological plausibility of the backpropagation algorithm has long been doubted by neuroscientists. Two major reasons are that neurons would need to send two different types of signal in the forward and backward phases, and that pairs of neurons would need to communicate through symmetric bidirectional connections.
We present a simple two-phase learning procedure for fixed point recurrent networks that addresses both these issues.
In our model, neurons perform leaky integration and synaptic weights are updated through a local mechanism.
Our learning method extends the framework of Equilibrium Propagation to general dynamics, relaxing the requirement of an energy function.
As a consequence of this generalization, the algorithm does not compute the true gradient of the objective function,
but rather approximates it at a precision which is proven to be directly related to the degree of symmetry of the feedforward and feedback weights.
We show experimentally that the intrinsic properties of the system lead to alignment of the feedforward and feedback weights, and that our algorithm optimizes the objective function.
tl;dr: We propose a framework that learns to encode knowledge symbolically and generate programs to reason about the encoded knowledge.

Deep neural networks (DNNs) had great success on NLP tasks such as language modeling, machine translation and certain question answering (QA) tasks. However, the success is limited at more knowledge intensive tasks such as QA from a big corpus. Existing end-to-end deep QA models (Miller et al., 2016; Weston et al., 2014) need to read the entire text after observing the question, and therefore their complexity in responding a question is linear in the text size. This is prohibitive for practical tasks such as QA from Wikipedia, a novel, or the Web. We propose to solve this scalability issue by using symbolic meaning representations, which can be indexed and retrieved efficiently with complexity that is independent of the text size. More specifically, we use sequence-to-sequence models to encode knowledge symbolically and generate programs to answer questions from the encoded knowledge. We apply our approach, called the N-Gram Machine (NGM), to the bAbI tasks (Weston et al., 2015) and a special version of them (“life-long bAbI”) which has stories of up to 10 million sentences. Our experiments show that NGM can successfully solve both of these tasks accurately and efficiently. Unlike fully differentiable memory models, NGM’s time complexity and answering quality are not affected by the story length. The whole system of NGM is trained end-to-end with REINFORCE (Williams, 1992). To avoid high variance in gradient estimation, which is typical in discrete latent variable models, we use beam search instead of sampling. To tackle the exponentially large search space, we use a stabilized auto-encoding objective and a structure tweak procedure to iteratively reduce and refine the search space.
tl;dr: We propose a method of distributed fine-tuning of language models on user devices without collection of private data

One of the big challenges in machine learning applications is that training data can be different from the real-world data faced by the algorithm. In language modeling, users’ language (e.g. in private messaging) could change in a year and be completely different from what we observe in publicly available data. At the same time, public data can be used for obtaining general knowledge (i.e. general model of English). We study approaches to distributed fine-tuning of a general model on user private data with the additional requirements of maintaining the quality on the general data and minimization of communication costs. We propose a novel technique that significantly improves prediction quality on users’ language compared to a general model and outperforms gradient compression methods in terms of communication efficiency. The proposed procedure is fast and leads to an almost 70% perplexity reduction and 8.7 percentage point improvement in keystroke saving rate on informal English texts. Finally, we propose an experimental framework for evaluating differential privacy of distributed training of language models and show that our approach has good privacy guarantees.
424. Adversarial Spheres
tl;dr: We hypothesize that the vulnerability of image models to small adversarial perturbation is a naturally occurring result of the high dimensional geometry of the data manifold. We explore and theoretically prove this hypothesis for a simple synthetic dataset.
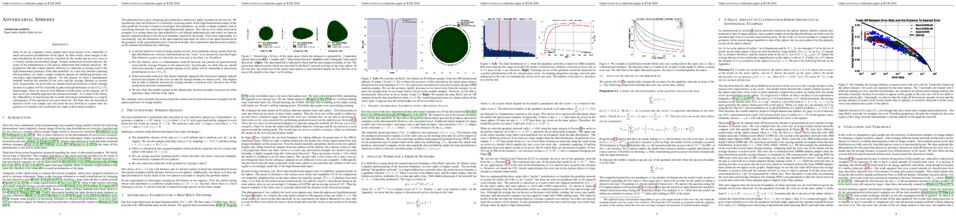
State of the art computer vision models have been shown to be vulnerable to small adversarial perturbations of the input. In other words, most images in the data distribution are both correctly classified by the model and are very close to a visually similar misclassified image. Despite substantial research interest, the cause of the phenomenon is still poorly understood and remains unsolved. We hypothesize that this counter intuitive behavior is a naturally occurring result of the high dimensional geometry of the data manifold. As a first step towards exploring this hypothesis, we study a simple synthetic dataset of classifying between two concentric high dimensional spheres. For this dataset we show a fundamental tradeoff between the amount of test error and the average distance to nearest error. In particular, we prove that any model which misclassifies a small constant fraction of a sphere will be vulnerable to adversarial perturbations of size $O(1/\sqrt{d})$. Surprisingly, when we train several different architectures on this dataset, all of their error sets naturally approach this theoretical bound. As a result of the theory, the vulnerability of neural networks to small adversarial perturbations is a logical consequence of the amount of test error observed. We hope that our theoretical analysis of this very simple case will point the way forward to explore how the geometry of complex real-world data sets leads to adversarial examples.

A bottleneck problem in machine learning-based relationship extraction (RE) algorithms, and particularly of deep learning-based ones, is the availability of training data in the form of annotated corpora. For specific domains, such as biomedicine, the long time and high expertise required for the development of manually annotated corpora explain that most of the existing one are relatively small (i.e., hundreds of sentences). Beside, larger corpora focusing on general or domain-specific relationships (such as citizenship or drug-drug interactions) have been developed. In this paper, we study how large annotated corpora developed for alternative tasks may improve the performances on biomedicine related tasks, for which few annotated resources are available. We experiment two deep learning-based models to extract relationships from biomedical texts with high performance. The first one combine locally extracted features using a Convolutional Neural Network (CNN) model, while the second exploit the syntactic structure of sentences using a Recursive Neural Network (RNN) architecture. Our experiments show that, contrary to the former, the latter benefits from a cross-corpus learning strategy to improve the performance of relationship extraction tasks. Indeed our approach leads to the best published performances for two biomedical RE tasks, and to state-of-the-art results for two other biomedical RE tasks, for which few annotated resources are available (less than 400 manually annotated sentences). This may be particularly impactful in specialized domains in which training resources are scarce, because they would benefit from the training data of other domains for which large annotated corpora does exist.